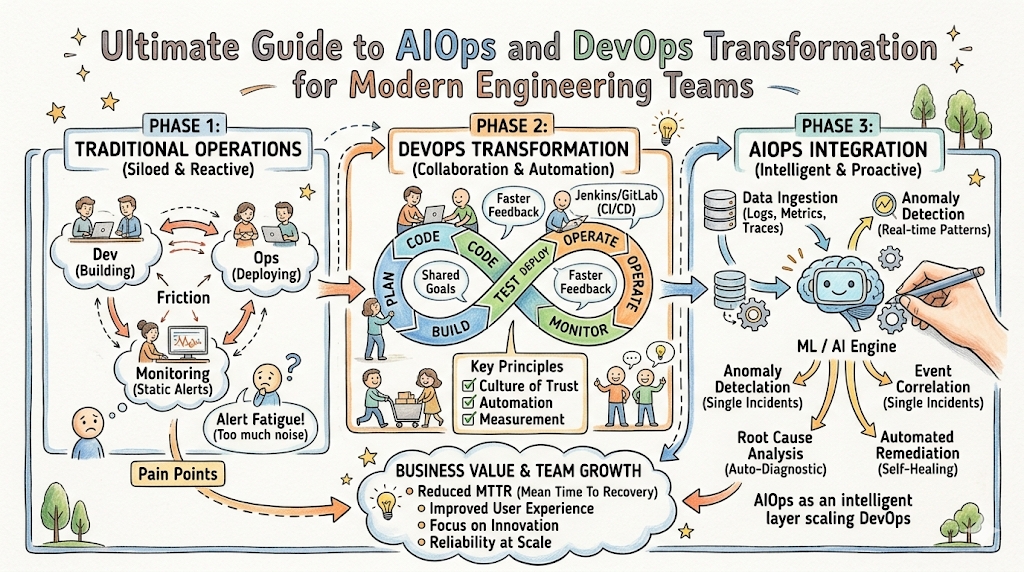
Introduction
The rapid acceleration of software delivery workflows has transformed the modern enterprise. Organizations worldwide have enthusiastically adopted DevOps methodologies to break down siloes, accelerate release velocities, and establish robust continuous integration and continuous deployment pipelines. Yet, as architectures evolve from centralized monoliths into highly dynamic, ephemeral, and distributed environments, a new operational paradigm has emerged. The shear volume, velocity, and variety of telemetry data generated by modern systems are outpacing the human capacity to interpret them.
In this cloud-native era, traditional infrastructure monitoring tools are no longer sufficient. Legacy systems rely on static thresholds, disconnected dashboards, and manual triage processes that fail when applied to thousands of microservices running across multi-cloud environments. When a critical production incident occurs, engineering teams are routinely inundated with thousands of downstream alerts triggered by a single upstream dependency failure.This operational friction is precisely where AIOpsSchool helps professionals pivot from reactive firefighting to intelligent, automated, and proactive operations.
Featured Snippet
What Is AIOps in DevOps?
AIOps in DevOps is the integration of artificial intelligence and machine learning into the software delivery and operations lifecycle. It ingests big data from logs, metrics, traces, and events across complex IT environments to automatically correlate data, detect anomalies, isolate root causes, and initiate automated remediation workflows, thereby scaling DevOps automation.
Understanding DevOps Transformation
What Is DevOps Transformation?
DevOps transformation is a fundamental shift in culture, process, and tooling designed to merge software development and IT operations. Rather than functioning as isolated entities with conflicting incentives (where developers push rapid changes and operations minimizes system updates to ensure stability), teams operate under a shared responsibility model. The focus centers on continuous value delivery, fast feedback loops, and highly integrated automation practices.
Goals of DevOps Transformation
The core tenets of a mature transformation extend far beyond simply installing a CI/CD server or adopting containerization. Organizations target several vital milestones:
- Accelerated Time-to-Market: Minimizing the cycle time between writing code and running it successfully in production.
- Enhanced Deployment Frequency: Shipping small, iterative features continuously rather than deploying massive, risky quarterly releases.
- Improved Quality: Shifting testing left to catch bugs early in the development lifecycle, leading to a lower change failure rate.
- Organizational Agility: Empowering engineering teams to adapt to shifting market conditions and user feedback almost instantaneously.
Evolution from Traditional IT Operations
Historically, IT environments changed slowly. Systems ran on physical bare-metal hardware or persistent virtual machines with clear boundaries. Software releases occurred every few months, managed by specialized deployment teams using rigid runbooks. Modern engineering has evolved into highly automated, infrastructure-as-code models where environments spin up and scale down programmatically in seconds based on demand.
Challenges Faced by Modern DevOps Teams
While DevOps effectively optimizes the delivery of software, it introduces massive operational complexity. Microservices, container orchestrators like Kubernetes, and serverless architectures generate deep interdependencies that are invisible to the naked eye. DevOps accelerates software delivery, but without advanced assistance, it leaves teams struggling to manage the vast operational footprint. This gap is precisely why modern organizations integrate artificial intelligence layer models over their workflows.
Section Engagement Insights
- In Simple Terms: DevOps transformation is changing how a company builds and runs software by making developers and operations teams work as one fast, automated unit.
- Real-World Example: A logistics enterprise replaces a manual, month-long deployment process with an automated Jenkins-driven pipeline that updates microservices multiple times a day across global Kubernetes clusters.
- Common Mistake: Treating the transformation strictly as a tooling upgrade (e.g., buying a platform licence) while ignoring the underlying culture, resulting in fragmented teams using modern tools in old, siloed ways.
Section Key Takeaways
- DevOps transformations merge development and operations to prioritize speed, reliability, and continuous iteration.
- Cloud-native architectures introduce high levels of systemic noise and obscure complex microservices dependencies.
- AIOps acts as an essential operational layer that complements fast software delivery with intelligent, scalable system management.
What Is AIOps?
Artificial Intelligence for IT Operations (AIOps) refers to the strategic application of machine learning, data science, and advanced analytics to automate the identification and resolution of IT operational challenges. An effective platform ingests massive volumes of diverse data directly from the infrastructure, unifies it, and derives actionable intelligence that humans simply cannot extract manually.
+-------------------------------------------------------------+
| Telemetry Ingestion |
| (Logs, Metrics, Events, Distributed Traces) |
+------------------------------+------------------------------+
|
v
+-------------------------------------------------------------+
| AIOps Engine Layer |
| (Big Data Storage -> ML & Event Correlation -> Analytics) |
+------------------------------+------------------------------+
|
v
+-------------------------------------------------------------+
| Actionable Output |
| (Anomaly Detection -> Root Cause Analysis -> Self-Healing) |
+-------------------------------------------------------------+
Key Components of AIOps
Machine Learning
Algorithms establish dynamic, real-time baselines for what constitutes normal system behavior across thousands of variables. Instead of manual configurations, the platform learns historical usage patterns, identifying subtle mathematical deviations that indicate impending degradations.
Big Data Analytics
Modern operations generate enormous data streams. The platform unifies unstructured logs, structured metrics, real-time events, and distributed application traces into a highly scalable, centralized data lake for comprehensive cross-layer analysis.
Event Correlation
Instead of treating alerts as isolated data points, advanced correlation grouping engines bundle thousands of concurrent notifications across different systems into a single, cohesive operational incident context based on timing, topology, and historical behavior.
Automation
When an incident is identified, the system moves beyond alerting to execute predefined scripts, triggering API calls, webhooks, or serverless functions to fix known issues instantly without human intervention.
Predictive Analytics
By evaluating historical system data, machine learning models anticipate infrastructure capacity shortages, resource constraints, and hardware degradation points well before they impact end-users.
Ingestion of Multi-Source Telemetry
AIOps does not replace your monitoring tools; it unifies them. The system ingests and processes five core types of operational data:
- Logs: Unstructured textual printouts generated by applications, containers, and operating systems.
- Metrics: Numerical values sampled over time, such as CPU utilization, memory footprints, and network throughput.
- Events: Specific, point-in-time operational actions, including code deployments, cloud auto-scaling actions, and configuration changes.
- Traces: End-to-end journey maps of individual application requests flowing through highly complex microservice chains.
- Operational Telemetry: Network flow logs, security events, and cloud provider status updates.
Section Engagement Insights
- In Simple Terms: AIOps is like a super-smart digital assistant for your servers that looks at all data simultaneously to find and fix hidden system problems before they cause an outage.
- Real-World Example: An analytics platform uses historical machine learning models to notice that a 5% increase in API latency on Monday morning perfectly matches a memory leak pattern seen three months ago, flagging it automatically.
- Common Mistake: Expecting an AIOps platform to work perfectly on day one without feeding it structured, high-quality historical log data to train its internal models.
Section Key Takeaways
- AIOps combines big data, algorithmic analytics, and automated response capabilities to optimize complex architectures.
- The framework ingests five key elements of system telemetry: logs, metrics, events, traces, and operational metadata.
- It moves IT operations from a strictly reactive posture to a predictive, highly automated environment.
Why DevOps Needs AIOps
The very success of DevOps has created the core challenge it now faces: an overwhelming explosion of operational data. As engineering teams deploy code faster, infrastructure scales programmatically, making it difficult for humans to manually keep pace with system changes.
The Monitoring Data Explosion
A distributed microservices architecture can easily generate terabytes of telemetry data every hour. Every single API gateway, container, message queue, and serverless function continuously writes logs and emits performance metrics. Humans cannot write enough regex patterns or configure enough static dashboards to accurately watch these data streams in real time.
Alert Fatigue
When thousands of components are interdependent, a minor glitch can cause a massive chain reaction of warnings. On-call engineering teams find themselves bombarded by endless streams of Slack alerts, PagerDuty pages, and automated emails. This constant noise causes alert fatigue, where engineers begin tuning out notifications, frequently leading them to miss the critical early warnings of a major system crash.
Increasing Infrastructure Complexity
Modern cloud infrastructures are highly ephemeral. Containers live for minutes; serverless functions execute in milliseconds. Traditional monitoring tools designed for static, long-lived bare-metal servers cannot map these fast-moving relationships effectively.
Multi-Cloud Challenges
Enterprise applications routinely span across multiple public cloud vendors (such as AWS, Azure, and GCP) alongside legacy on-premises datacenters. Each cloud ecosystem comes with its own native logging formats, metric structures, and API behaviors, leaving engineers with a highly fragmented view of operational health.
Microservices Visibility Problems
In a modern microservices architecture, a single user transaction might traverse dozens of separate services written in different programming languages and running on entirely different cloud clusters. When a user experiences a slow checkout experience, pinpointing the exact microservice causing the bottleneck becomes incredibly difficult without automated correlation engines.
Section Engagement Insights
- In Simple Terms: Teams are building software so fast and across so many cloud servers that they are drowning in alerts and cannot find the true cause of errors manually.
- Real-World Example: A streaming media service experiences an outage because an on-call engineer silences a PagerDuty channel after receiving 1,500 low-priority disk space alerts within a two-hour window.
- Common Mistake: Adding more standalone dashboard tools to fix visibility issues, which accidentally increases confusion by forcing engineers to jump between multiple screens during an incident.
Section Key Takeaways
- Fast deployment loops and microservices produce an unmanageable amount of telemetry data for human analysis.
- Alert fatigue creates significant business risks by causing teams to overlook critical, high-severity infrastructure problems.
- Multi-cloud and ephemeral architectures require centralized, AI-driven correlation layers to maintain complete operational clarity.
How AIOps Supports DevOps Transformation
AIOps acts as an intelligent automation layer that directly accelerates DevOps maturity. It converts raw, disconnected telemetry into clear, actionable operational steps, helping teams shift away from chaotic firefighting toward controlled, continuous improvement.
Intelligent Monitoring and Anomaly Detection
Traditional monitoring relies entirely on hardcoded, static thresholds—for instance, triggering an alert only when CPU utilization crosses 85%. However, a database server running at 90% during a scheduled batch backup at 3:00 AM might be completely normal, while that same 90% utilization at 12:00 PM on a Tuesday indicates a major performance bug. AIOps platforms use machine learning to dynamically map regular behavioral baselines that adjust for time of day, day of the week, and seasonal traffic spikes, ensuring teams are alerted only to genuine anomalies.
Automated Event Correlation
When a core network switch drops packets, hundreds of downstream microservices will simultaneously report connectivity errors. AIOps engines ingest this flood of alerts and use topology mapping and timing analysis to combine them into a single, cohesive incident ticket. Instead of receiving 400 separate notifications, the engineering team receives one master notification explaining that a single network component failure is currently impacting 400 downstream items.
Root Cause Analysis (RCA)
Finding the root cause of an incident inside a distributed system usually requires hours of manual cross-referencing across different systems. AIOps tools speed up this process by automatically matching the exact timestamp of an anomaly with code deployments, infrastructure configuration updates, and dependency mappings. The system presents engineers with the single most likely point of failure, drastically shrinking the time required to understand the underlying problem.
Predictive Incident Prevention
The true power of AIOps lies in its ability to look ahead. By analyzing historical trends and early failure signatures, predictive analytics engines identify subtle system degradations—such as a slow, steady memory leak in a container or a predictable storage depletion curve on a critical disk volume—well before the issue impacts the end-user experience.
[ Telemetry Data Stream ]
│
▼
[ Machine Learning Baseline Engine ] ──► (Detects subtle mathematical drift)
│
▼
[ Topology Mapping & Correlation ] ──► (Groups 400 alerts into 1 Incident)
│
▼
[ Root Cause Analysis Engine ] ──► (Pinpoints exact bad deployment commit)
│
▼
[ Automated Remediation Script ] ──► (Triggers rollback via CI/CD Webhook)
Automated Remediation and Self-Healing Infrastructure
AIOps bridges the gap between insight and action by driving closed-loop automation. When the platform identifies a known, well-documented issue, it doesn’t just notify an engineer; it directly runs automated remediation playbooks. Whether it’s safely clearing a localized log cache, restarting a locked service container, or calling a CI/CD webhook to automatically roll back a buggy code deployment, the infrastructure resolves its own routine operational anomalies safely.
Section Engagement Insights
- In Simple Terms: AIOps automatically groups hundreds of confusing alerts into one clear problem description, points to the broken line of code, and runs a script to fix it.
- Real-World Example: A fintech platform automatically detects an unusual spike in payment processing errors following a midnight code release, identifies the exact bad commit, and triggers an automated GitOps rollback within four minutes.
- Common Mistake: Configuring automated remediation workflows to execute complex, high-risk infrastructure changes without first validating the accuracy of the underlying playbooks in non-production environments.
Section Key Takeaways
- Dynamic machine learning baselines eliminate the need for engineering teams to constantly maintain fragile, manual static alert thresholds.
- Advanced automated event correlation groups thousands of downstream warnings into single, clear incident contexts.
- Closed-loop self-healing automation resolves routine infrastructure errors directly, freeing developers to focus on building features.
AIOps vs. Traditional DevOps Monitoring
To fully understand the value of an AI-driven operational approach, it helps to compare its core capabilities directly against traditional DevOps monitoring systems.
| Capability | Traditional DevOps Monitoring | AIOps-Driven DevOps Operations |
| Data Analysis Focus | Processes data in siloes (separate dashboards for logs, metrics, and traces). | Unifies all logs, metrics, traces, and events into a single, cohesive data lake. |
| Threshold Configuration | Relies on manual, static rules that require constant engineering updates. | Uses automated machine learning to establish dynamic, self-adjusting baselines. |
| Alert Management | Passively routes every alert, resulting in severe noise and alert fatigue. | Clusters related notifications into a single, context-rich incident ticket. |
| Root Cause Analysis | Requires manual team war-rooms to search through disjointed dashboards. | Uses algorithmic analytics to instantly isolate the probable root cause. |
| Operational Stance | Completely reactive; triggers notifications only after a failure threshold is breached. | Highly predictive; flags early system deviations before an actual outage occurs. |
| Remediation Workflows | Depends on engineers manually executing runbook steps during emergencies. | Triggers automated, closed-loop scripts to safely self-heal known issues. |
| System Scalability | Degrades as architectures scale, requiring significant manual overhead. | Scales effortlessly with microservices and complex multi-cloud deployments. |
Section Engagement Insights
- In Simple Terms: Traditional monitoring is like a smoke alarm that goes off only when your kitchen is already on fire; AIOps is like an intelligent thermal camera that warns you the moment a wire begins overheating behind the wall.
- Real-World Example: During a heavy traffic surge, a legacy tool pages teams because CPU usage hits 90%, whereas an AIOps tool recognizes the traffic surge as a normal seasonal pattern and keeps teams focused on genuine performance errors instead.
- Common Mistake: Assuming an AIOps deployment means throwing away existing investments in Prometheus or Grafana, rather than using AIOps as an intelligent layer that unifies those exact tools.
Section Key Takeaways
- Traditional monitoring tools are limited by siloed data processing and rigid, manual alert threshold management.
- AIOps unifies infrastructure data streams to deliver complete, contextual system visibility across every layer.
- Shifting from reactive alerting to predictive analysis helps engineering teams stop outages before they affect customers.
Key Benefits of AIOps in DevOps Environments
Integrating machine learning into your infrastructure workflows delivers measurable improvements across both operational metrics and overall team productivity.
Faster Incident Detection and Lower MTTR
By continuously evaluating system data streams, AIOps engines flag anomalous patterns within seconds. Once a problem is detected, automated root cause identification cuts down Mean Time to Resolution (MTTR). Teams spend significantly less time arguing in emergency war rooms and more time deploying precise resolutions.
Drastic Noise Reduction and Less Alert Fatigue
By clustering downstream warnings into a single master incident ticket, AIOps platforms filter out up to 90% of redundant operational noise. On-call engineers receive far fewer false alarms, ensuring they remain alert and focused when a genuine high-priority incident requires their manual intervention.
Maximized System Reliability and Availability
Predictive analytics engines give operations teams the visibility needed to address system bottlenecks, resource risks, and capacity strains long before they lead to unexpected application downtime. This proactivity directly translates into higher service-level objectives (SLOs) and rock-solid application availability.
Elevated Customer and User Experiences
When system anomalies are caught and remediated behind the scenes via automated workflows, end-users never experience transaction failures, page latencies, or application drop-offs. Maintaining clean, highly responsive software lifecycles builds long-term customer satisfaction and brand trust.
Measurable Reductions in Operational Costs
Automating routine infrastructure tasks—such as cleanup routines, database optimization scripts, and localized service restarts—substantially reduces manual operational overhead. Furthermore, fast incident resolutions protect enterprises from the severe financial penalties and lost revenue associated with major production outages.
Optimized Team Productivity and Innovation Velocity
When engineers are freed from the daily grind of triaging duplicate alerts and manually digging through log files, they can refocus their time on high-value initiatives. Teams shift their energy toward writing clean features, improving platform architecture, and optimizing release pipelines.
Section Engagement Insights
- In Simple Terms: AIOps gives engineering teams their time back by silencing false alarms, resolving minor bugs automatically, and making sure software runs reliably for users.
- Real-World Example: A global SaaS company cuts its incident resolution time from four hours down to twelve minutes by using an AI engine to instantly correlate application trace anomalies with database lock exceptions.
- Common Mistake: Measuring the success of an AIOps initiative solely by the number of dashboards built, instead of focusing on key business outcomes like reduced MTTR and improved system stability.
Section Key Takeaways
- AIOps significantly improves operational efficiency by accelerating incident detection and driving down corporate MTTR metrics.
- Intelligent event grouping eliminates redundant system alerts, protecting engineering teams from burnout and alert fatigue.
- Automating routine operational tasks allows developers to step away from infrastructure firefighting and focus on feature innovation.
AIOps Across the DevOps Lifecycle
AIOps is not a single tool used exclusively by an operations team during a production crash. Instead, it serves as a continuous, intelligent feedback mechanism that adds value across every single stage of the modern software delivery lifecycle.
[ PLANNING ] ◄── (Historical Capacity Analytics)
│
▼
[ DEVELOPMENT ] ◄── (Pre-Production Code Profiling)
│
▼
[ TESTING ] ◄── (Automated Regression Flakiness Analysis)
│
▼
[ DEPLOYMENT ] ◄── (Real-Time Deployment Anomaly Profiling)
│
▼
[ MONITORING ] ◄── (Dynamic ML-Driven Baseline Evaluation)
│
▼
[ INCIDENT RESPONSE ] ◄── (Root Cause Isolation & Self-Healing)
│
▼
[ CONTINUOUS IMPROVEMENT ] ◄── (Post-Mortem Telemetry Generation)
1. Planning
During the initial design phase, product managers and software architects leverage historical operational telemetry to make data-driven decisions. AIOps tools analyze historical system usage, compute resource trends, and application load behaviors over the past year. This enables teams to accurately budget cloud infrastructure costs, forecast capacity constraints, and prioritize technical debt remediation based on actual system strains rather than guesswork.
2. Development
AIOps enhances development workflows by shifting operational insights left directly into the coding phase. AI engines analyze how code behaves in development and staging environments, identifying hidden code smells, inefficient database queries, and thread synchronization issues long before the software is committed to the main repository branch. This proactive visibility ensures developers ship inherently resilient code from day one.
3. Testing
Modern automated testing suites often generate vast quantities of complex test logs, particularly when running extensive regression suites or load tests. AIOps platforms quickly parse these test outputs to flag flaky tests, identify non-deterministic test failures, and isolate performance regressions. This prevents broken code from slipping through the QA pipeline while ensuring build failures are meaningful and actionable.
4. Deployment
The deployment phase represents one of the highest risk points in the software delivery cycle. When a new microservice container is pushed to production via a canary or blue-green deployment strategy, the AIOps engine continuously compares the real-time telemetry of the new deployment against historical baselines. If the new code causes a subtle, low-frequency anomaly—such as a minor increase in 5xx errors or an unusual memory utilization slope—the engine flags the regression instantly, allowing the deployment pipeline to trigger an automated rollback before the update rolls out to the entire user base.
5. Monitoring
Once code runs stably in production, the platform provides continuous, intelligent observability. It ingests the entire corporate data stream, evaluating logs, metrics, and application traces simultaneously. Instead of relying on static configurations, it continuously updates its internal behavioral models, mapping normal system behavior across changing infrastructure states and traffic patterns.
6. Incident Management
When an unexpected infrastructure failure occurs, AIOps coordinates the response workflow. It silences non-urgent alerts, bundles related anomalies into a single clear incident file, isolates the most likely root cause, and points engineers to the broken lines of code or faulty configuration parameters. If a pre-verified remediation script exists, the platform runs it immediately to safely resolve the incident without requiring human intervention.
7. Continuous Improvement
Following the resolution of an incident, the system automates the creation of comprehensive post-mortem documentation. It extracts the exact timeline of the failure, aggregates the relevant telemetry traces, documents the automated actions taken, and highlights systemic vulnerabilities. This gives engineering teams the objective data needed to make long-term architecture improvements and prevent the issue from ever returning.
Section Engagement Insights
- In Simple Terms: AIOps helps at every stage of making software—from planning what to build next and spotting bugs during testing, to safely deploying code and fixing live production issues.
- Real-World Example: A mobile banking company integrates its deployment pipeline with an AIOps engine, which catches a 3% memory leak during a minor canary release and automatically aborts the rollout before users notice anything.
- Common Mistake: Using AIOps exclusively as a production alerting tool, which misses the opportunity to use its insights earlier in the testing and development pipelines to catch bugs early.
Section Key Takeaways
- Integrating AIOps across the entire software delivery pipeline prevents infrastructure vulnerabilities from reaching production.
- Automated canary analysis flags subtle deployment anomalies early, allowing CI/CD systems to run safe, programmatic rollbacks.
- Data-driven post-incident analytics give teams the deep system visibility needed to design long-term architectural stability.
Essential AIOps Technologies and Tools
Building an intelligent operational environment requires combining several specialized technologies into a unified observability and automation platform.
+-------------------------------------------------------------------------+
| Observability Layers |
| (Datadog / Dynatrace / New Relic / Splunk / Prometheus / Elastic) |
+------------------------------------+------------------------------------+
|
v
+-------------------------------------------------------------------------+
| Intelligent Action Layer |
| (PagerDuty / Opsgenie / BigPanda / Moogsoft) |
+------------------------------------+------------------------------------+
|
v
+-------------------------------------------------------------------------+
| Automated Resolution Layer |
| (Ansible / Terraform / Kubernetes Operators / Rundeck) |
+-------------------------------------------------------------------------+
Full-Stack Observability Platforms
Modern observability suites go far beyond traditional monitoring by combining data ingestion with native machine learning models. Platforms like Dynatrace and New Relic use deterministic AI and causal analysis to automatically discover application topologies, map microservice dependencies, and pinpoint performance bottlenecks down to the exact broken line of code. Similarly, Datadog features integrated machine learning engines that provide automated anomaly detection, log outlier analysis, and predictive infrastructure capacity forecasting across complex cloud environments.
Enterprise Log Analytics and Big Data Engines
Managing large volumes of unstructured log data requires powerful, highly scalable ingestion engines. Splunk leverages advanced machine learning algorithms to index terabytes of operational logs daily, allowing teams to perform real-time correlation, run predictive analytics, and detect hidden security risks. For organizations utilizing open-source frameworks, the Elastic Stack (ELK) provides embedded machine learning features that automatically flag anomalous log rates, group similar log messages together, and identify system outliers across multi-cloud deployments.
Incident Correlation and Response Orchestration
When alerts flood in from multiple disjointed monitoring tools, correlation engines are essential for cutting through the digital noise. Platforms like BigPanda and Moogsoft ingest raw event streams from across the enterprise, deduplicate identical notifications, and group related warnings into singular, context-rich incident tickets based on timing and infrastructure topology. These insights feed into incident management platforms like PagerDuty and Opsgenie, which use intelligent routing, automated on-call escalation policies, and machine learning triage capabilities to ensure the right team is notified along with the full operational context needed to solve the issue.
Infrastructure Automation and Remediation Frameworks
Once an AIOps engine identifies the root cause of an incident, it coordinates with automation tools to execute precise remediation playbooks. Tools like Ansible and Rundeck run automated workflows to resolve routine issues, such as safely purging localized application caches, rotating expiring security certificates, or restarting locked service threads. In containerized environments, custom Kubernetes Operators leverage internal feedback loops to monitor cluster states, automatically scale pod deployments during sudden traffic surges, and self-heal failing containers without human intervention.
Section Engagement Insights
- In Simple Terms: You do not need to build AI tools from scratch; you connect your existing monitoring tools to advanced correlation engines and automation frameworks to create an intelligent system.
- Real-World Example: An enterprise combines Datadog for anomaly detection, BigPanda for event correlation, and PagerDuty to route the grouped alert directly to the on-call engineer along with the correct Ansible rollback script.
- Common Mistake: Collecting every single tool on the market without a clear integration plan, which leads to fragmented data silos and actually increases operational noise.
Section Key Takeaways
- Full-stack observability tools use built-in machine learning models to map microservice dependencies and accelerate root cause analysis.
- Event correlation engines act as a central clearinghouse, filtering out redundant alert noise before it reaches on-call engineers.
- Connecting your correlation engines to automation frameworks enables self-healing workflows that resolve routine infrastructure glitches.
Real-World Use Cases
To understand the business value of combining AI and DevOps, let’s explore how different industries use intelligent operations to maintain uptime and scale their infrastructure.
E-Commerce Platforms
- The Challenge: During a high-traffic Black Friday shopping event, a major e-commerce retailer experiences an unexpected checkout slowdown. Legacy monitoring systems trigger hundreds of separate alerts across the API gateway, payment processing microservices, and database layers, leaving engineers unable to identify the actual source of the bottleneck during peak sales hours.
- The AIOps Solution: An enterprise AIOps engine unifies the incoming alert streams and uses real-time topology mapping to instantly isolate the root cause: a minor code update had introduced an unindexed database query within the inventory validation microservice. The platform surfaces this specific insight, suppressing all other downstream alerts.
- The Business Outcome: The engineering team deploys a database index patch within nine minutes, reducing the average resolution time by 88%. This prevents a major prolonged outage, protects millions of dollars in transaction revenue, and maintains a seamless checkout experience for customers.
Digital Banking Systems
- The Challenge: A retail banking application runs a highly complex infrastructure spanning across multiple public clouds and legacy on-premises mainframes. A subtle memory leak inside an authentication microservice causes performance to degrade slowly over several weeks, slipping completely under traditional static monitoring thresholds until the application suddenly crashes.
- The AIOps Solution: The bank deploys machine learning algorithms to continuously analyze historical performance trends. The AI engine notices a slow, steady upward drift in memory consumption that deviates from normal weekly usage baselines, flagging the anomaly weeks before a critical system failure occurs.
- The Business Outcome: The system automatically notifies the platform engineering team of the impending memory exhaustion risk. This allows developers to safely schedule and deploy a permanent memory management patch during a planned maintenance window without causing any service disruptions for banking customers.
SaaS Enterprise Applications
- The Challenge: A rapidly growing cloud-native SaaS provider manages thousands of isolated Kubernetes containers across multiple global regions. The platform operations team is overwhelmed by alert fatigue, spending hours every day manually closing duplicate alerts and tracking down non-critical infrastructure glitches.
- The AIOps Solution: The organization implements an intelligent event correlation platform that automatically groups related alert streams based on timing and cluster proximity. Additionally, they configure automated remediation playbooks to handle routine, well-documented system events.
- The Business Outcome: Redundant operational alert noise is slashed by 85%, and over 40% of standard infrastructure issues—such as localized disk capacity constraints and stuck application threads—are resolved automatically by self-healing scripts, allowing engineers to focus on product feature development.
Healthcare Digital Platforms
- The Challenge: A large healthcare provider runs an integrated telehealth platform that handles critical patient monitoring data. A sudden, unexpected surge in user traffic causes database connection pools to saturate, leading to severe latency spikes that disrupt live video consultations between doctors and patients.
- The AIOps Solution: An AI-driven operations platform monitors infrastructure health in real time. The moment connection latencies deviate from standard operational baselines, the platform executes an automated remediation playbook that dynamically spins up auxiliary read replicas and expands the active database connection pool.
- The Business Outcome: System latency drops back to normal parameters within two minutes without requiring any manual engineering intervention. Telehealth sessions remain completely stable, protecting patient care and ensuring continuous compliance with healthcare service level agreements.
Section Engagement Insights
- In Simple Terms: Across e-commerce, banking, and healthcare, AIOps cuts through infrastructure noise to find hidden glitches early, keeping critical digital services running smoothly for users.
- Real-World Example: A SaaS platform uses an event correlation engine to reduce its daily alert volume from 12,000 chaotic notifications down to 45 actionable incidents, saving its engineering team hours of manual triage every week.
- Common Mistake: Believing your architecture is too unique for standard AIOps models, ignoring that machine learning algorithms excel at discovering custom patterns across any structured telemetry stream.
Section Key Takeaways
- E-commerce platforms leverage real-time topology analysis to protect transaction revenues during high-volume sales events.
- Financial institutions use predictive trend modeling to catch slow-moving system vulnerabilities long before they cause unexpected downtime.
- Automating routine infrastructure fixes enables healthcare and SaaS providers to protect user experiences and maintain high service availability.
Common Challenges in AIOps Adoption
While the operational advantages of an AI-driven infrastructure are clear, organizations frequently encounter common roadblocks during initial deployment. Recognizing these challenges early allows engineering leaders to plan a smooth, successful rollout.
[ ROADBLOCK ] ──► [ SOLUTION ]
┌───────────────────────────────┐ ┌───────────────────────────────┐
│ "Garbage In, Garbage Out" │ │ Implement OpenTelemetry and │
│ Fragmented, low-quality data │ │ standardize logging formats │
└───────────────────────────────┘ └───────────────────────────────┘
┌───────────────────────────────┐ ┌───────────────────────────────┐
│ "Black Box" Skepticism │ │ Start with read-only insights │
│ Engineers don't trust the AI │ │ before enabling automation │
└───────────────────────────────┘ └───────────────────────────────┘
┌───────────────────────────────┐ ┌───────────────────────────────┐
│ Skills & Tooling Siloes │ │ Cross-train teams on data │
│ Lack of internal data skills │ │ science and system topology │
└───────────────────────────────┘ └───────────────────────────────┘
Telemetry Fragmentation and Data Quality Issues
Machine learning models depend entirely on the quality of the data they ingest. If an enterprise’s telemetry data is fragmented—with development teams using different logging formats, inconsistent metric names, and incomplete tracing coverage—the AIOps engine will generate inaccurate insights and false positives, a classic case of “garbage in, garbage out.”
- The Practical Solution: Establish strict corporate telemetry standards by adopting modern, open-source collection frameworks like OpenTelemetry. Standardize log structures, enforce uniform tagging rules across all cloud resources, and ensure comprehensive distributed tracing coverage before training your AI models.
Cultural Resistance and the “Black Box” Trust Gap
Experienced engineers are often skeptical of automated systems, particularly when algorithms make critical operational recommendations without presenting a clear, understandable rationale. If an engineering team does not trust the AI, they will ignore its insights, turn off automated playbooks, and fall back to manual troubleshooting methods during emergencies.
- The Practical Solution: Implement AIOps in visible, progressive phases. Begin by using the platform strictly in a “read-only” advisory capacity, allowing the AI to display its analytical reasoning alongside its findings. Once engineers see the models consistently identify root causes accurately over several months, teams will naturally gain the trust needed to safely enable automated, closed-loop remediation workflows.
Legacy Infrastructure and Tool Integration Gaps
Large enterprises often run legacy, monolithic software suites alongside modern, containerized cloud environments. Many legacy systems lack open APIs, struggle to emit real-time telemetry, and fail to integrate with modern event correlation engines, creating blind spots in the enterprise operational footprint.
- The Practical Solution: Deploy specialized telemetry forwarders and API bridge layers to extract data from legacy systems. When full integration is impossible, focus your AIOps deployment on core business paths—such as customer-facing frontends, payment processing channels, and modern microservices layers—where intelligent operations deliver the highest financial return.
Internal Data Science Skill Gaps
DevOps engineers and site reliability specialists are experts in managing infrastructure, writing code, and configuring deployment pipelines, but they rarely have formal training in data science, statistical modeling, or machine learning engineering. This makes it difficult for teams to optimize AI configurations and fine-tune correlation algorithms.
- The Practical Solution: Invest in modern, turnkey enterprise AIOps tools that feature pre-trained machine learning models, automated topology discovery tools, and user-friendly, low-code configuration interfaces. Additionally, encourage your platform engineers to utilize educational resources like AIOpsSchool to build practical, long-term skills in data-driven operations.
Section Engagement Insights
- In Simple Terms: Implementing AIOps successfully requires setting up clean data streams, building team trust slowly, and focusing on cross-training engineers rather than just installing new tools.
- Real-World Example: An insurance provider overcomes team skepticism by running an AI engine in a staging environment for three months, demonstrating that it accurately identifies deployment bugs without causing false alarms.
- Common Mistake: Turning on fully automated, self-healing remediation scripts across your entire production infrastructure on day one, which can lead to unpredictable automated feedback loops if your scripts contain hidden bugs.
Section Key Takeaways
- Successful AIOps adoptions require standardized telemetry architectures built on open frameworks like OpenTelemetry.
- Building long-term engineering trust requires a phased rollout approach, moving from advisory insights to automated remediation.
- Providing structured team training ensures operations specialists can confidently configure and maximize AI platform capabilities.
Best Practices for Successful AIOps-Driven DevOps
Transitioning to an intelligent operational model requires a structured, deliberate roadmap. By following these industry-proven implementation guidelines, organizations can maximize system reliability while avoiding common deployment pitfalls.
1. Build a Foundation of Deep System Observability
Before deploying advanced machine learning models, ensure your infrastructure has complete observability coverage. You cannot analyze data that you are not actively collecting. Work to eliminate operational blind spots by gathering high-resolution metrics, unstructured log streams, and end-to-end distributed application traces across every layer of your modern cloud environments.
2. Define Clear, Actionable Business KPIs
Avoid the temptation to measure everything at once. Instead, align your platform configurations with key business outcomes and operations metrics. Focus on tracking clear performance indicators that directly impact user experiences and bottom-line costs:
- Mean Time to Detect (MTTD): How quickly your system flags an operational anomaly.
- Mean Time to Resolution (MTTR): The average time required to completely resolve a system incident.
- Change Failure Rate: The percentage of code deployments that result in production errors.
- Alert-to-Incident Ratio: A direct metric indicating how effectively your engine filters out redundant system noise.
3. Focus on Data Quality and Standardized Tagging
Ensure all incoming telemetry data is structured, consistently formatted, and rich with metadata. Establish automated compliance checks within your infrastructure-as-code configurations to enforce uniform tagging guidelines across all cloud servers, containers, and microservices. Clean, well-tagged data allows correlation engines to accurately understand system relationships and map application dependencies.
4. Implement Closed-Loop Automation Gradually
Adopt a conservative, phased approach when rolling out automated remediation workflows. Start by automating simple, low-risk, and well-understood tasks, such as clearing localized disk caches or gathering diagnostic dumps during application latencies. Review execution logs carefully, and only transition to high-impact automated operations—such as programmatic service rollbacks or dynamic resource adjustments—after the underlying playbooks have proven perfectly reliable over time.
5. Foster an Educational Culture of Continuous Learning
Technology tools alone cannot transform an enterprise operations culture. Invest heavily in cross-training your development, platform, and site reliability engineering teams. Provide engineers with the dedicated time and educational resources needed to master advanced log analysis, statistical anomaly tracking, and automated incident response frameworks, ensuring your organization can scale its internal operational capabilities smoothly.
Section Engagement Insights
- In Simple Terms: Start by collecting clean, organized data, pick a few key performance metrics to track, automate minor fixes first, and invest heavily in training your engineering teams.
- Real-World Example: A travel booking platform focuses its initial AIOps rollout on reducing its high customer checkout MTTR, shrinking it from two hours down to six minutes within the first sixty days of deployment.
- Common Mistake: Focusing purely on technical metrics like CPU utilization graphs while ignoring how system performance directly impacts core business outcomes and customer transaction success rates.
Section Key Takeaways
- Establishing high-quality, full-stack system observability is an essential prerequisite for any successful AIOps deployment.
- Aligning infrastructure metrics with business outcomes ensures your AI platform investments deliver measurable financial value.
- Rolling out automated remediation scripts in gradual, structured phases protects production environments from unexpected automation glitches.
Career Opportunities in AIOps and DevOps
The shift toward intelligent operations is creating a surge in demand for engineering professionals who know how to combine software development, system reliability, and data science capabilities.
┌─────────────────────────────────────────┐
│ AIOps & Observability Leader │
└────────────────────▲────────────────────┘
│
┌──────────────────────────┴──────────────────────────┐
│ │
┌───────────────────────┐ ┌───────────────────────┐
│ AIOps Engineer │ │ Observability Eng. │
└───────────▲───────────┘ └───────────▲───────────┘
│ │
└──────────────────────────┬──────────────────────────┘
│
┌──────────────────────────┴──────────────────────────┐
│ │
┌───────────────────────┐ ┌───────────────────────┐
│ DevOps Engineer │ │ SRE Specialist │
└───────────────────────┘ └───────────────────────┘
AIOps Engineer
- Core Responsibilities: These specialists design, build, and maintain the corporate intelligent operations framework. They build scalable big data ingestion pipelines, configure real-time alert correlation engines, and tune machine learning models to prevent false alarms. They collaborate closely with development teams to build automated self-healing scripts and closed-loop infrastructure remediation playbooks.
- Essential Skills: Strong proficiency in data science architectures, big data systems (such as Kafka, Spark, or Elasticsearch), scripting languages (Python, Go), and practical experience with enterprise AIOps engines (like Splunk, Dynatrace, or Moogsoft).
Site Reliability Engineer (SRE)
- Core Responsibilities: SREs use software engineering principles to solve complex infrastructure scalability and system reliability challenges. They leverage AI insights to manage enterprise Service Level Objectives (SLOs), coordinate automated responses during production outages, and run detailed post-incident reviews to permanently eliminate architectural vulnerabilities.
- Essential Skills: Deep knowledge of cloud-native systems, container management platforms (Kubernetes), infrastructure-as-code automation (Terraform), and a strong familiarity with algorithmic anomaly detection and distributed application tracing frameworks.
Platform Engineer
- Core Responsibilities: Platform engineers focus on building and optimizing an Internal Developer Platform (IDP)—a curated suite of automated tools, cloud templates, and self-service workflows that allow software developers to safely deploy and monitor code without manually managing complex backend infrastructure components.
- Essential Skills: Designing self-service developer portals (such as Backstage), building automated CI/CD deployment pipelines, managing enterprise configuration tools, and integrating AI-driven observability guardrails directly into the software delivery workflow.
Observability Engineer
- Core Responsibilities: These dedicated professionals focus entirely on building full-stack visibility architectures across the corporate enterprise. They deploy automated telemetry agents, integrate open-source telemetry frameworks (OpenTelemetry) into application codebases, design centralized visualization dashboards, and ensure data ingestion lakes remain fast and cost-effective.
- Essential Skills: Mastery of data formatting specifications, open collection ecosystems (OpenTelemetry, Prometheus), data lake management, and configuring deep application performance monitoring (APM) tools across multi-cloud environments.
Section Engagement Insights
- In Simple Terms: The shift to AI-driven operations is creating high-paying career paths for engineers who know how to mix software engineering, cloud automation, and machine learning analytics.
- Real-World Example: A senior DevOps engineer completes specialized training in data analytics and transitions into a dedicated AIOps Architect role, leading an enterprise-wide initiative to automate incident response workflows.
- Common Mistake: Assuming you need a PhD in advanced mathematics to become an AIOps engineer, when companies value practical cloud automation skills and a solid understanding of system architectures.
Section Key Takeaways
- Modern operations requires a new class of specialized engineering professionals focused on automated infrastructure and system visibility.
- AIOps engineers bridge the gap between software development, site reliability engineering, and practical machine learning application.
- Upskilling in data analytics and open telemetry standards opens doors to rapid career advancement and leadership roles.
Future of AIOps and DevOps Transformation
As machine learning models grow more powerful, the relationship between AI and DevOps will evolve from simple pattern recognition into fully autonomous, self-directed operational systems.
Integration of Generative AI and Large Language Models
Generative AI is changing how teams interact with complex IT environments. Modern operations platforms feature embedded natural language interfaces that allow engineers to interrogate their infrastructure using plain English queries—such as asking, “Why did database latency spike in region west-2 over the last hour?” The AI instantly analyzes relevant metrics, reads recent log entries, evaluates code deployment history, and generates a detailed analytical narrative alongside the exact code patch required to resolve the issue.
Autonomous Incident Response and Agentic Operations
We are rapidly moving beyond simple, rule-based automation scripts toward intelligent, agentic operations. In this model, autonomous AI agents continuously monitor system states, collaborate with other software tools, and independently make complex operational decisions. When a multi-cloud outage occurs, an AI agent can dynamically diagnose the infrastructure failure, evaluate alternative cloud routing topologies, spin up backup environments, and safely migrate live traffic without requiring any human engineering assistance.
Ubiquitous Self-Healing Architecture
In the coming years, self-healing architecture will transition from an advanced enterprise luxury to a standard infrastructure requirement. Applications will be built with internal feedback loops that allow them to automatically optimize their own configurations based on changing real-time demands. Systems will independently adjust memory footprints, rewrite inefficient database queries on the fly, and dynamically reconfigure internal microservice parameters to guarantee constant system availability.
Platform Engineering and Intelligent Developer Guards
AI will become deeply integrated into Internal Developer Platforms, acting as an automated gatekeeper that protects system stability. As developers write code, AI engines will continuously evaluate modifications against real-time production telemetry. If a developer attempts to commit code that would introduce a security vulnerability, violate compliance rules, or cause a resource strain based on current production traffic, the platform will automatically block the commit and provide specific optimization recommendations before the code can ever reach production.
Section Engagement Insights
- In Simple Terms: The future of technology operations is fully autonomous software that can chat with engineers in plain English, diagnose its own glitches, and heal its own code failures instantly.
- Real-World Example: An enterprise deploys an AI agent that detects a global network routing failure, chats with the team on Slack to explain the situation, and safely reroutes web traffic to a backup data center within forty seconds.
- Common Mistake: Fearing that AI automation will replace human engineering jobs, rather than realizing it frees developers from boring firefighting tasks so they can focus on high-value creative architecture.
Section Key Takeaways
- Generative AI tools allow developers to troubleshoot complex infrastructure issues using simple natural language queries.
- Advanced autonomous agents will soon manage end-to-end incident response workflows across complex multi-cloud deployments.
- Embedding AI guardrails into platforms allows organizations to catch performance bugs early, ensuring long-term system stability.
FAQ Section
1.What is AIOps in DevOps?
AIOps in DevOps is the integration of machine learning and data science into software delivery pipelines. It automatically collects, correlates, and analyzes full-stack infrastructure telemetry data to optimize system reliability and streamline daily operations.
2. How does AIOps improve DevOps?
AIOps enhances DevOps environments by cutting through redundant alert noise, automatically identifying the root cause of production incidents, predicting resource capacity constraints, and executing automated self-healing playbooks to resolve infrastructure issues quickly.
3. Is AIOps replacing DevOps?
No, AIOps does not replace DevOps; it acts as an intelligent automation layer that supports it. DevOps defines the collaboration cultures, deployment processes, and delivery workflows, while AIOps provides the automated data analysis needed to manage those operations at scale.
4. What skills are needed for AIOps?
Professionals need a solid understanding of cloud-native infrastructure, container management frameworks (Kubernetes), infrastructure automation tools (Terraform, Ansible), scripting languages (Python, Go), alongside a strong practical familiarity with data science, telemetry processing, and log analytics engines.
5. What are the benefits of AIOps?
Key business benefits include significantly faster incident detection times, lower corporate MTTR metrics, a drastic reduction in redundant alert noise, maximized application availability, minimized infrastructure operational costs, and elevated development productivity.
6. How does AIOps reduce MTTR?
AIOps drives down Mean Time to Resolution (MTTR) by automatically analyzing logs, metrics, and application traces simultaneously during an anomaly. It isolates the exact root cause of a failure within seconds, eliminating the need for engineers to conduct manual triage sessions during production outages.
7. What tools are commonly used in AIOps?
Popular industry tools include full-stack observability platforms like Dynatrace, Datadog, and New Relic; enterprise log analytics solutions like Splunk and the Elastic Stack (ELK); alongside incident correlation and routing frameworks like BigPanda, Moogsoft, and PagerDuty.
8. Can startups use AIOps?
Yes, startups can leverage modern, turnkey SaaS observability platforms that feature pre-trained anomaly detection models out of the box. Implementing intelligent baselines early allows small engineering teams to protect system uptime without drowning in manual monitoring overhead.
9. Is AIOps useful for Kubernetes?
AIOps is highly effective for managing Kubernetes environments. The ephemeral, fast-changing nature of container orchestration makes manual mapping impossible; AI engines excel at tracking real-time container topologies, mapping microservice dependencies, and automating container auto-scaling workflows.
10. How does AIOps support SRE practices?
AIOps directly supports Site Reliability Engineering (SRE) by providing the automated, data-driven insights needed to manage complex Service Level Objectives (SLOs), filtering out non-urgent alert noise, and executing automated remediation workflows to safely reduce overall operational toil.
11. Does AIOps require a data science degree?
No, modern enterprise AIOps tools feature user-friendly interfaces, automated configuration engines, and pre-trained machine learning models designed to be managed directly by standard cloud operations, DevOps, and platform engineering teams.
12. What is event correlation in AIOps?
Event correlation is the process of using time-series algorithms and infrastructure topology maps to automatically group thousands of concurrent, duplicate system alerts triggered by a single underlying failure into a single, comprehensive incident ticket.
13. How does AIOps handle predictive analytics?
AIOps engines evaluate large volumes of historical system telemetry to map long-term operational trends. By detecting subtle system drifts, resource leaks, and capacity strains early, the platform alerts teams to infrastructure risks long before an actual outage occurs.
14. What is the first step to adopt AIOps?
The critical first step is establishing deep, standardized full-stack system observability. Ensure your applications, containers, and databases are generating clean, well-structured logs, metrics, and traces using open framework collection specifications like OpenTelemetry.
15. Where can I learn AIOps skills?
Engineers and IT professionals can build comprehensive, practical skills in intelligent cloud operations, automated incident management, and modern observability frameworks by utilizing specialized educational training platforms like AIOpsSchool.
Final Summary
Modern DevOps transformations have fundamentally accelerated software delivery velocity and empowered organizations to iterate with unprecedented speed. However, this rapid innovation has introduced significant operational complexity. The massive explosion of multi-cloud environments, containerized microservices, and ephemeral architectures produces a flood of telemetry data that easily overwhelms traditional static monitoring tools, resulting in widespread alert fatigue and costly extended outages.
AIOps addresses this challenge by serving as an intelligent data analysis layer that unifies enterprise logs, metrics, events, and traces into a cohesive operational ecosystem. By leveraging machine learning models, automated dependency mapping, and dynamic event correlation, AIOps silences up to 90% of redundant infrastructure noise, isolates the true root cause of complex failures within seconds, and executes automated playbooks to safely resolve routine issues without requiring manual human intervention.