Introduction
Modern enterprise technology environments are incredibly complex. A single online banking or e-commerce transaction can travel through dozens of microservices, multiple cloud environments, encrypted databases, and third-party payment gateways. When a single component slow down or fails, finding the root cause manually feels like searching for a needle in a digital haystack. This scale of operation is exactly why traditional IT monitoring systems are no longer enough. For beginners, students, and IT professionals, mastering this domain is one of the most stable career decisions you can make. The industry is moving rapidly toward autonomous, self-healing infrastructure, creating a massive demand for professionals who understand how these intelligent systems work. If you are looking to build a foundation in this space, comprehensive training programs and structured learning tracks provided by AIOpsSchool offer a clear path to gaining the exact architectural knowledge and practical experience that modern enterprises demand.
What Is Predictive Analytics in AIOps?
To understand predictive analytics within AIOps, it helps to examine how enterprise IT management has changed over the last few decades.
Definition and Core Concepts
Predictive analytics in AIOps is the application of mathematical algorithms and machine learning models to historical and real-time operational data (such as metrics, logs, events, and traces) to forecast future system behavior, performance trends, and potential failure points.
Instead of simple threshold alerts (like telling you when a CPU hits 90% utilization), predictive systems analyze the context, rate of change, and multi-variable correlations to tell you that a disk volume will run out of space in exactly four hours based on current application traffic patterns.
The Evolution of AIOps Analytics
IT monitoring has evolved through three distinct eras:
- Reactive Monitoring: Looking backward. Teams relied on static dashboards and basic alerts. An incident occurred, an alarm sounded, and engineers rushed to investigate what broke.
- Proactive Observability: Looking at the present. Systems collected rich telemetry data (metrics, logs, and traces) to provide deep visibility into the internal state of applications, helping teams diagnose active problems faster.
- Predictive Operations: Looking forward. Systems analyze historical context and stream real-time data to forecast what will happen next, turning raw telemetry into actionable future insights.
The Relationship Between AI, ML, and IT Operations
Artificial Intelligence (AI) is the broad vision of creating systems capable of mimicking intelligent human behavior. Machine Learning (ML) is the specific subset of AI that allows software applications to become more accurate at predicting outcomes without being explicitly programmed.
In an enterprise IT ecosystem, machine learning models ingest millions of data points generated by applications and infrastructure every minute. These models learn the unique operational baseline of an organization, identifying what “normal” looks like during peak sale days, quiet weekends, or standard business hours.
Why Predictive Analytics Became Essential
Traditional IT architectures were largely static and monolithic, making them relatively easy to monitor using simple rules. Modern environments rely on dynamic cloud infrastructure, auto-scaling Kubernetes clusters, and ephemeral serverless functions that spin up and down in seconds. Humans simply cannot write enough manual rules to keep up with these fluid environments. Predictive analytics provides the automated mathematical oversight needed to process data at this extreme scale.
Why Predictive Analytics Matters in Modern IT Operations
When an enterprise enterprise system goes down, every minute of outage translates directly to lost customers, interrupted operations, and severe financial penalties. Predictive analytics fundamentally alters this risk profile by providing several key structural advantages:
- Faster Incident Detection: Traditional alerts trigger only after a failure line is crossed. Predictive monitoring identifies slow, creeping performance drift early, giving engineering teams hours of advance notice to resolve a bottleneck.
- Reduced Downtime: By warning engineers about database lockups, memory leaks, or network congestion before they manifest as outright service failures, systems remain continually accessible to users.
- Intelligent Alerting: Operations teams are constantly bombarded by thousands of low-priority alerts, a major driver of team burnout known as alert fatigue. Predictive analytics groups related warnings together, suppressing background noise and surfacing only valid operational threats.
- Root Cause Prediction: When a major issue starts to brew, predictive intelligence tracks the sequence of anomalous behaviors across the infrastructure, mapping out the dependency tree to tell engineers exactly which component started the chain reaction.
- Infrastructure Reliability: Consistent predictive modeling helps infrastructure teams balance workloads across cloud instances, preventing hardware exhaustion and improving overall platform stability.
- Cloud-Scale Monitoring: As services scale across multiple global regions, AI-driven IT operations dynamically adapt to changing traffic volumes, ensuring that temporary traffic spikes do not trigger false emergency procedures.
- Operational Efficiency: Instead of senior engineers spending hours digging through logs to find out why an application is sluggish, the AIOps platform delivers the underlying diagnostics automatically, allowing teams to focus on building features rather than fighting fires.
- Business Continuity: High-value transactions, such as core banking transfers or airline check-ins, are protected against sudden underlying infrastructure drops, ensuring reliable, uninterrupted customer experiences.
Core Concepts of Predictive AIOps
To build a clear understanding of predictive AIOps architectures, it helps to break the system down into its core underlying functional layers.
Machine Learning in IT Operations
Machine learning algorithms serve as the processing engine of AIOps. The platform uses supervised learning (training models on labeled historical incident data to recognize specific types of failures) and unsupervised learning (analyzing unlabeled data to discover hidden patterns and unusual behaviors without human guidance). These algorithms continuously adjust their mathematical weights as your production systems evolve.
Anomaly Detection
Traditional monitoring relies on fixed thresholds, such as alerting when RAM usage exceeds 85%. However, if a batch job run at midnight naturally consumes 90% of RAM every night without issue, a static alert creates unnecessary noise. Anomaly detection uses statistical models to establish a dynamic baseline of behavior that adapts to the time of day, day of the week, or seasonal business cycles, flagging deviations only when a metric behaves outside its learned normal range.
Event Correlation
A single infrastructure failure can cause thousands of downstream alerts to fire simultaneously, overwhelming on-call engineers. Event correlation engines use topology mapping and time-series clustering to group these thousands of related symptoms into a single, cohesive incident ticket, highlighting the core issue while filtering out the secondary noise.
Predictive Monitoring
Predictive monitoring uses forecasting algorithms to map out the future trajectory of a metric. For instance, by evaluating linear and non-linear consumption trends, the system calculates the exact future time window when an application’s connection pool will be entirely exhausted, allowing operators to scale up resources well in advance.
Incident Forecasting
By analyzing historical incident tracking logs alongside telemetry data, incident forecasting systems identify early structural warning signs that typically precede a major application crash. This gives teams an automated early-warning window to patch or restart vulnerable services.
Root Cause Analysis (RCA)
When a failure occurs, finding the source requires tracing connections across a complex web of dependencies. Predictive AIOps leverages real-time architecture graphs to run downstream cause-and-effect calculations, pointing out the specific broken microservice, bad deployment configuration, or locked database row responsible for the problem.
Observability
While basic monitoring tracks whether a system is running or stopped, observability is the practice of measuring a system’s internal states based on its external outputs: metrics (numeric values over time), logs (structured lines of text describing specific events), and traces (the end-to-end journey of a request through a system). Predictive analytics relies on this rich, multi-dimensional observability data to form its conclusions.
Automated Remediation
Once an incident is predicted or detected, automated remediation engines step in to resolve the issue without human intervention. This is achieved by triggering pre-configured automated workflows, such as running a script to clear temporary log directories, restarting a hung container, or allocating additional cloud storage.
Self-Healing Systems
The ultimate realization of an advanced enterprise IT architecture is a self-healing system. By tightly coupling predictive analytics with automated remediation, the platform continuously forecasts resource shortages or application faults, automatically applying corrective fixes in the background so that production systems maintain continuous, uninterrupted operation.
AIOps Architecture & Workflow
An effective predictive AIOps system follows a highly structured, data-driven framework to convert raw operational data into automated resolutions.
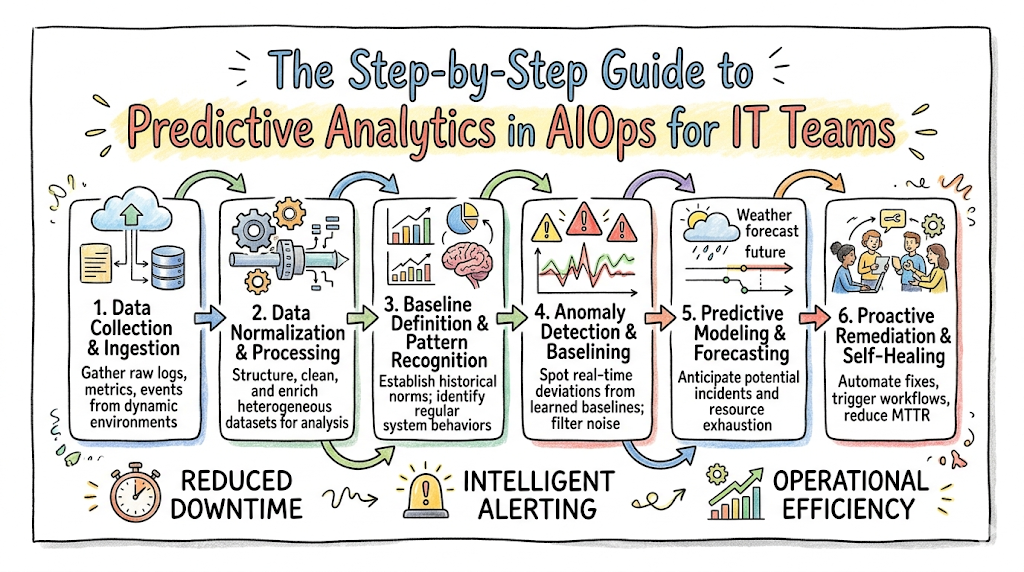
1. Data Collection and Pipeline
The workflow begins at the infrastructure layer, where data collection agents and streaming APIs ingest continuous telemetry from every corner of the enterprise: physical hardware, virtual machines, cloud services, application frameworks, network routers, and database instances. This data must be collected with minimal latency to ensure real-time analysis.
2. Log Analytics and Metric Ingestion
Once collected, raw text logs are parsed and structured, while time-series metrics are clean and indexed. This high-volume ingestion engine aggregates disparate data formats into a unified format, preparing it for statistical modeling.
3. AI/ML Processing Layer
The structured data streams directly into the core engine where machine learning models execute real-time statistical evaluations. This layer runs the dynamic baselining computations, measures behavioral variance, and monitors for active data anomalies across interdependent systems.
4. Event Intelligence and Action
If an anomaly is verified, the event intelligence engine cross-references the event against known dependency topologies and past incident patterns. It suppresses duplicate alerts, isolates the projected root cause, and generates a detailed alert profile. This output is either delivered directly to an engineer’s console or handed off to the incident automation layer, which executes a self-healing script to fix the system before a single user experiences a performance issue.
Predictive Analytics Lifecycle in AIOps
To understand how data flows and transforms throughout a predictive operational cycle, we can map out the lifecycle stages from initial raw ingestion to permanent continuous learning:
| Stage | Purpose | Technologies Used | Real-World Outcome |
| Data Collection | Gather continuous raw telemetry across all corporate systems. | Prometheus, OpenTelemetry, Fluentd | Total visibility into infrastructure state without manual tracking gaps. |
| Data Processing | Standardize, clean, and format disparate metrics and log types. | Apache Kafka, Logstash, Vector | High-speed, unified data pipelines ready for immediate mathematical evaluation. |
| Pattern Analysis | Establish deep behavioral baselines and map structural dependencies. | K-Means Clustering, Linear Regression | Clear, automated understanding of regular system behavior during all hours. |
| Anomaly Detection | Isolate unusual variations from the established normal baselines. | Isolation Forests, Autoencoders | Immediate detection of hidden, creeping performance drops or unusual leaks. |
| Prediction Modeling | Forecast the exact timeline and impact of future system failures. | LSTM Networks, ARIMA Modeling | Early warning alerts giving engineering teams hours to prepare and resolve issues. |
| Incident Response | Package anomalies and predictions into clear, prioritized alerts. | ServiceNow, Jira Service Management | Clean, organized workspaces showing root causes while filtering out junk alerts. |
| Automation | Run automated scripts to fix the forecasted issues instantly. | Ansible, Rundeck, AWS Systems Manager | Rapid self-healing of systems without requiring late-night engineer intervention. |
| Continuous Learning | Update model weights based on human feedback and new resolutions. | Reinforcement Learning, MLOps Loops | System becomes progressively smarter over time, minimizing future false alarms. |
Popular AIOps Tools & Platforms
Modern enterprises use an array of highly specialized tools to handle different aspects of the predictive analytics lifecycle.
Monitoring and Observability Platforms
These platforms are designed to ingest massive streams of telemetry, provide end-to-end visualization, and apply built-in machine learning models to detect real-time anomalies.
Log Analytics and AI Automation Tools
These systems focus on parsing billions of lines of unstructured log messages to find rare errors, run correlation rules, and execute automated corrective actions across infrastructure.
To see how these core technologies stack up against each other in real-world deployments, review the comparison table below:
| Tool | Purpose | Difficulty | Enterprise Usage |
| Dynatrace | Full-stack observability with deterministic AI engine (Davis) for precise root-cause analysis. | Advanced | Heavily used by large banks and global financial firms to monitor multi-cloud systems. |
| Datadog | Unified SaaS platform combining cloud metrics, application tracing, and predictive anomaly alerts. | Medium | Popular among fast-growing SaaS enterprises, cloud-native startups, and DevOps squads. |
| Splunk Enterprise Security | Massive-scale log analytics engine that uses machine learning to predict system and security risks. | Advanced | Utilized by global corporations for central log management, compliance, and core infrastructure operations. |
| Dynatrace AutomationEngine | Orchestrates self-healing workflows and code remediation based on active AI triggers. | Advanced | Integrated directly into automated delivery pipelines to handle continuous platform healing. |
| Elastic Observability | Open-source foundation optimized for searching logs, tracking metrics, and identifying trend anomalies. | Medium | Widely deployed across corporate IT units for customizable search, debugging, and analytics. |
| PagerDuty | Intelligent event orchestration platform that groups alerts and automates incident calling. | Easy to Medium | Used universally by on-call engineering teams to manage incident responses and reduce alert noise. |
Predictive Analytics Use Cases in AIOps
Predictive analytics is not a theoretical concept; it is actively protecting critical infrastructure across multiple global industries right now.
- Cloud Infrastructure: A global software provider notices a massive spike in user logins during a marketing campaign. Predictive monitoring scales up cloud instances ahead of time, ensuring zero page latency for incoming users.
- Kubernetes Environments: In a complex containerized cluster, an internal microservice develops a gradual memory leak. The AIOps platform forecasts a container crash two hours in advance, triggering an automated rolling restart of the specific pod without dropping active user connections.
- Banking Systems: A major retail bank processes millions of instant payments simultaneously. The predictive analytics engine spots a tiny micro-delay pattern building inside a core database cluster, isolating a locking table row before payment processing grinds to a halt.
- Telecom Networks: A telecommunications provider manages thousands of cellular towers. Predictive models analyze radio frequency metrics and weather trends to identify towers likely to degrade, allowing maintenance teams to swap out aging hardware before a local service outage occurs.
- Healthcare IT: Hospital patient monitoring databases must maintain constant availability. AIOps platforms watch underlying network data streams, predicting and rerouting bandwidth around failing routing switches to keep lifesaving data flowing continuously to medical staff.
- E-Commerce Platforms: During a massive global flash sale, an e-commerce platform’s inventory microservice slows down due to an unexpected database lock. The analytics system detects the anomaly instantly, isolating the issue and automatically scaling up database read-replicas to handle the transaction load without interrupting shoppers.
- SaaS Applications: A multi-tenant software-as-a-service application tracks user interactions. Predictive modeling monitors usage patterns to detect if a specific tenant is approaching their api rate limit, automatically alerting the account manager and scaling resources to accommodate the spike seamlessly.
- Enterprise Monitoring Systems: Corporate internal authentication portals handle thousands of employee logins every morning. AIOps tools track login attempt velocities, predicting network gateway bottlenecks at 9:00 AM and dynamically adjusting load balancer weights to maintain snappy employee access.
Benefits of Predictive AIOps
Transitioning an enterprise to an AI-driven operational model yields massive, quantifiable improvements across every facet of technology delivery:
- Faster MTTR (Mean Time to Resolution): By delivering precise root-cause diagnostics alongside an incident prediction, teams cut down troubleshooting times from hours to mere minutes.
- Reduced Alert Fatigue: Filtering out background noise and duplicate alerts keeps engineering teams focused, clear-headed, and dedicated to solving critical problems.
- Proactive Incident Management: Shifting the operational framework from a chaotic firefighting structure to planned, preventive maintenance completely changes team culture for the better.
- Better Scalability: Automated predictive scaling allows infrastructure to expand gracefully alongside business growth, without requiring manual capacity planning from system administrators.
- Improved Uptime: Eliminating infrastructure outages ensures critical digital products remain highly reliable and fully operational for global users around the clock.
- Automation Efficiency: Eliminating manual intervention loops allows basic infrastructure adjustments to execute automatically, freeing human capital for strategic engineering tasks.
- Reduced Operational Costs: Minimizing prolonged service outages protects organizations from expensive regulatory fines, contractual SLA violations, and emergency remediation expenses.
- Better Customer Experience: Smooth, lag-free, and dependable application interactions build lasting trust and keep end users consistently engaged with your digital services.
Challenges & Limitations
While the power of predictive AIOps is clear, implementing these platforms comes with real operational hurdles that enterprise teams must address:
- Data Quality Issues (Garbage In, Garbage Out): Machine learning models require clean, comprehensive, and consistent telemetry data to generate accurate forecasts. If your underlying infrastructure logs are poorly structured, fragmented, or missing key fields, the predictive engine will produce unreliable, inaccurate forecasts.
- Solution: Implement strict, standardized data collection policies using open frameworks like OpenTelemetry to ensure clean, structured logging across all production applications.
- AI Model Complexity: Advanced deep learning models can operate as mysterious black boxes, making it difficult for engineers to see exactly how a machine arrived at a specific incident forecast.
- Solution: Focus on utilizing AIOps platforms that leverage causal AI and explainable models, which explicitly lay out the underlying logical path and evidence behind every prediction.
- False Positives: If an anomaly detection model is configured with overly sensitive settings, it can flag normal operational shifts as critical emergencies, creating new forms of alert noise.
- Solution: Allow models an extended initial baseline learning window, and continuously train the system by having engineers mark false alarms via platform feedback loops.
- Integration Challenges: Legacy enterprise software architectures often rely on old, siloed monitoring utilities that do not naturally export data to modern AI streaming pipelines.
- Solution: Deploy lightweight open-source log forwarders and API wrappers to bridge the data gap, extracting data from legacy systems and feeding it smoothly into central messaging queues.
- Skill Shortages: There is a major industry shortage of specialized engineering talent who understand both core cloud infrastructure operations and practical data science concepts.
- Solution: Invest in structured engineering upskilling and clear foundational learning paths, utilizing expert training programs like those provided by AIOpsSchool.
AIOps Roles & Career Opportunities
The widespread adoption of predictive operations has led to a major hiring surge for specialized cloud professionals.
Primary Roles in the Market
- AIOps Engineer: Focuses on deploying, tuning, and maintaining the central AI engines, managing the underlying machine learning training loops, and ensuring data parsing pipelines run cleanly.
- SRE (Site Reliability Engineer): Bridges the gap between development and operations, using software engineering principles to automate system reliability and manage proactive self-healing infrastructure.
- Observability Engineer: Designs the telemetry frameworks, ensuring that all microservices, databases, and cloud systems export high-quality metrics, logs, and traces.
- DevOps Engineer: Coordinates automated deployment pipelines, integrating predictive monitoring hooks directly into continuous integration and delivery cycles.
Core Skills Required
To thrive in this field, professionals need an integrated mix of skills:
- Systems Operation: Deep comfort with Linux environments, network protocols, and core container concepts.
- Telemetry Knowledge: Mastery of log aggregation, time-series analysis, and distributed application tracing.
- Scripting and Automation: Ability to write clean Python scripts and build automated configuration plays using tools like Ansible.
- Basic Data Science: Understanding how anomaly detection, classification, and regression models evaluate datasets.
Salary Trends and Industry Demand
Because these skills are highly specialized, salaries in this domain sit at the very top tier of the technology market. Globally, skilled AIOps and site reliability engineers command premium compensation, with major hubs in the US, Europe, and India reporting consistent year-over-year increases in unfilled roles. Companies are actively competing for engineers who can protect their cloud infrastructure from downtime.
Beginner Roadmap for Learning AIOps
Breaking into the world of predictive AIOps requires a methodical, step-by-step approach to learning. You cannot master machine learning for operations without first understanding how basic operations work.
Step 1: Master Linux Basics
Linux is the foundation of the modern cloud. You must feel comfortable navigating the command line, configuring user permissions, managing filesystems, and troubleshooting basic processes.
Step 2: Understand Networking Fundamentals
Learn how data moves across the internet. Master the basics of the TCP/IP stack, DNS resolution, HTTP request structures, load balancing, and routing principles.
Step 3: Learn Monitoring Fundamentals
Start with traditional monitoring concepts. Learn how to configure static alerts, gather system metrics (CPU, Memory, Disk, Network), and read standard application logs.
Step 4: Adopt Cloud Platforms
Gain practical experience with at least one major cloud provider (such as AWS, Microsoft Azure, or Google Cloud Platform). Learn how to launch instances, manage cloud storage, and configure virtual networks.
Step 5: Embrace DevOps and Containers
Learn how containers work by mastering Docker. From there, move into Kubernetes to understand container orchestration, service discovery, and cluster management.
Step 6: Pick Up Python Scripting
Python is the universal language of both automation and data science. Learn how to write scripts that read log files, make API calls, parse JSON payloads, and automate repetitive tasks.
Step 7: Explore Machine Learning Basics
You do not need a PhD in mathematics, but you must understand core concepts. Learn the difference between supervised and unsupervised learning, and study how basic linear regression and clustering models function.
Step 8: Dive Deep into Observability
Move beyond basic monitoring. Learn how to implement distributed tracing using tools like OpenTelemetry, analyze structured application logs, and build deep dashboards.
Step 9: Practice Incident Management
Study how modern teams handle outages. Learn about incident lifecycle stages, on-call rotations, alert routing, and writing post-mortem reports.
Step 10: Master Dedicated AIOps Tools
Now that you have the foundation, learn to configure enterprise-grade AIOps platforms. Practice creating dynamic baseline rules, fine-tuning anomaly detection models, and hooking up automated self-healing workflows.
Certifications & Training
Validating your knowledge through recognized professional training is a fantastic way to stand out to enterprise hiring managers.
| Certification | Level | Best For | Skills Covered |
| Certified Kubernetes Administrator (CKA) | Intermediate | Engineers managing modern container infrastructure and production microservices. | Core Kubernetes architecture, cluster networking, scheduling, and pod troubleshooting. |
| AIOpsSchool Professional Foundation | Beginner | Systems entry-level learners seeking a clear entry point into intelligent automation. | Core AIOps concepts, dynamic baselining, telemetry collection, and alert tuning. |
| Datadog Fundamentals Certification | Beginner to Intermediate | Cloud engineers aiming to specialize in modern SaaS observability and monitoring. | APM tracing, dashboard engineering, log management, and automated anomaly alerts. |
| Dynatrace Certified Associate | Intermediate | Enterprise architects deploying enterprise-scale AI-driven root cause analysis engines. | Causal AI operations, full-stack infrastructure tracing, and automated remediation. |
| Splunk Core Certified Power User | Intermediate | Data analysts and security professionals running heavy multi-terabyte log analytics. | Advanced search syntax, machine learning toolkits, data transformation, and reporting. |
Common Beginner Mistakes
When starting out in this advanced domain, keep an eye out for these frequent learning traps:
- Learning Tools Without Understanding Operations: Many beginners rush to learn an advanced tool like Dynatrace or Datadog before understanding how a basic Linux server or network router actually works. If you do not know what a metric means, an AI tool cannot help you fix it.
- Ignoring Monitoring Fundamentals: Skipping basic log management and standard time-series metrics to jump straight into complex machine learning models leaves you without the foundational troubleshooting skills needed when an AI platform fails.
- Skipping Cloud Basics: Attempting to implement advanced automated remediation workflows without a solid grasp of basic cloud infrastructure security, networking, and compute primitives leads to fragile, poorly designed automation.
- Over-Focusing on AI Buzzwords: Do not get distracted by flashy marketing terms. Focus on the core engineering reality: how data is collected, how it is processed, and how automated actions are executed reliably in production.
- Lack of Hands-On Practice: Reading theory articles or watching videos is a start, but you will never truly understand AIOps until you break a live application in a lab environment and use log analytics and metrics to find and fix the root cause yourself.
Best Practices for Enterprise AIOps
If you are tasked with implementing or managing a predictive AIOps framework within an organization, follow these operational guidelines:
- Adopt an Automation-First Strategy: Every time an engineer manually resolves an incident, they should ask: “How can we write a script to automate this fix next time?” The end goal of predictive analytics should always be driving automated self-healing workflows.
- Implement Deep Observability Early: Ensure that your development teams build telemetry logging directly into their application code from day one. An AIOps platform can only be as smart as the data you feed it.
- Maintain Continuous Monitoring: Production systems change constantly with new code deployments. Your anomaly detection models must run continuously, constantly adjusting their learned baselines to mirror the live state of your application environment.
- Enforce Strict Incident Prioritization: Do not treat every single anomaly as a critical emergency. Group alerts logically, and prioritize warnings based on actual user-facing impact, keeping your on-call engineers fresh and focused.
- Optimize AI Models Regularly: Schedule periodic operational reviews to tune your alerting models. Identify and silence frequent false positives, and adjust statistical thresholds to match seasonal business changes.
- Keep Clear Documentation: Document every automated remediation workflow clearly. Every engineer on the team must know exactly what scripts the AI platform is authorized to run when a system failure is predicted.
- Integrate Security Practices: Ensure that your data collection pipelines comply with corporate data governance laws. Strip out sensitive user data, passwords, and personally identifiable information (PII) at the collection agent level before logs enter your central analytics databases.
Future of Predictive Analytics in AIOps
The field of AI-driven operations is evolving at an incredible pace. Over the coming years, several structural shifts will redefine how enterprise technology infrastructure is managed:
- Generative AI Integration: Large language models are merging with AIOps tools, allowing engineers to converse naturally with their infrastructure. Instead of writing complex query syntax, an operator can simply ask: “What is causing the slight latency spike in our checkout service right now?” and receive a clear text analysis alongside the fixing script.
- Fully Autonomous IT Systems: We are rapidly moving past basic alert generation toward completely self-contained, autonomous IT ecosystems. Future platforms will independently discover new services, configure their own monitoring profiles, detect drift, and run internal patches without needing human confirmation.
- AI Copilots for SRE Teams: On-call engineers will work side-by-side with intelligent digital assistants that continuously evaluate system code, surface optimization opportunities, write post-mortem reports, and guide teams through complex incident responses.
- Hyperautomation Across Layers: Automation will extend deep past simple infrastructure scaling. Predictive systems will continuously optimize cloud spending, alter network routing configurations globally in real time, and adjust application configurations on the fly to maximize efficiency.
- Intelligent Edge Observability: As internet-of-things (IoT) devices and edge computing environments expand, predictive analytics models will shrink, running directly on localized cell towers, medical devices, and smart hardware to spot and fix faults locally without relying on a central cloud response.
FAQs
- What is predictive analytics in AIOps?
Predictive analytics in AIOps is the practice of using historical system telemetry data and machine learning models to forecast future performance trends and catch technical issues before they cause system downtime.
2. How does AIOps reduce downtime?
It monitors live data patterns, identifies early system errors or resource drops, isolates the true root cause, and triggers automated scripts to resolve the issue before users experience a service disruption.
3. Is machine learning necessary for AIOps?
Yes. Traditional monitoring rely on static manual thresholds that cannot handle modern, fast-changing cloud environments. Machine learning allows systems to discover complex data anomalies and adapt dynamically without human coding.
4. Which tools are used in predictive monitoring?
Leading enterprise tools include Dynatrace, Datadog, Splunk, Elastic Observability, and automated event management systems like PagerDuty.
5. Can beginners learn AIOps?
Absolutely. Anyone can learn AIOps by building a solid foundation in Linux, basic networking, container management, and cloud infrastructure operations before moving into advanced AI utilities.
6. Is coding required for AIOps?
Yes, basic scripting skills are highly important. You should know how to write simple Python code and design automation plays to connect different systems, parse files, and manage APIs.
7. What industries use AIOps?
It is widely used across finance, retail e-commerce, telecommunications, healthcare IT, software-as-a-service providers, and any enterprise running large-scale cloud applications.
8. How long does it take to learn AIOps?
If you are starting from scratch, it typically takes six to twelve months of dedicated study and practical project work to build strong comfort with cloud operations, telemetry pipelines, and AIOps tools.
9. What is the difference between monitoring and observability?
Monitoring tracks basic system health states (whether a service is up or down), while observability allows you to understand a system’s internal state by looking deeply at its metrics, logs, and traces.
10. What is alert fatigue?
Alert fatigue is the mental exhaustion experienced by engineering teams when they are constantly bombarded with a high volume of minor, non-critical notifications, often causing them to miss real system threats.
11. How do you prevent false positives in AIOps?
False alarms are prevented by allowing the machine learning models an extended initial window to learn system baselines, and by regularly adjusting sensitivity thresholds based on engineering feedback.
12. What data types does an AIOps platform collect?
It ingests four core data types, often called MELT: Metrics (numeric values), Events (structured occurrences), Logs (text records), and Traces (the paths of requests through a system).
13. Can AIOps fix problems entirely on its own?
Yes. When hooked up to an automated remediation engine, the system can run self-healing scripts to fix common issues like clearing disk space or restarting services without human intervention.
14. What is MTTR and why does it matter?
MTTR stands for Mean Time to Resolution. It measures the average time required to troubleshoot and fix a broken system. Lowering MTTR is a key priority for corporate technology teams.
15. Where can I get structured training in this field?
Comprehensive, step-by-step training tracks covering modern cloud administration, site reliability engineering, and intelligent automation are offered directly by specialized programs like AIOpsSchool.
Final Thoughts
The transformation of enterprise IT operations from a reactive, manual structure into an intelligent, predictive ecosystem is one of the most important shifts in modern technology. As businesses expand their digital operations, they can no longer afford to run systems blindly, waiting for an outage to occur before taking action. The future belongs to organizations that manage infrastructure proactively, and to the engineers who know how to build and guide these intelligent systems.
If you are working your way through this learning curve, avoid the trap of collecting shallow tool names or memorizing industry keywords. Focus heavily on mastering the core principles of reliable system operation, understanding how telemetry data flows, and learning how automation script engines execute tasks.
Excellent explanation of how predictive analytics improves incident management and system reliability in modern IT environments.
Well-written and informative. The article clearly demonstrates how predictive analytics can help IT teams reduce downtime and make smarter operational decisions.
I liked how the article explains the practical role of predictive analytics in improving operational efficiency and reducing downtime.