Every infrastructure engineer knows the feeling of being woken up at three in the morning by a cascade of alerts. Your inbox is flooded, your dashboard is glowing red, and finding the single root cause among thousands of noise signals feels impossible. This scenario leads to massive downtime, stressed teams, and missed business goals. Most enterprises are still struggling with reactive firefighting, but there is a better way to handle these challenges.
Introduction to AIOps: Revolutionizing IT Operations refers to the application of machine learning, data science, and automation to streamline IT operational processes. By analyzing vast amounts of telemetry data, these systems identify hidden patterns and automate manual troubleshooting tasks. Enterprises are moving toward this intelligent model because it shifts the focus from fixing broken services to preventing failures before they impact users. This guide provides a clear roadmap for engineers looking to master these concepts, and you can discover more expert guidance by visiting AIOpsSchool.
The Origin of IT Operations Challenges
The Early Infrastructure Monitoring Problems
Traditional monitoring systems rely on static thresholds. You set a limit, and if a metric crosses it, an alert fires. While useful for simple servers, this approach fails in complex, distributed environments. Static thresholds trigger endless false alarms for minor fluctuations, creating a sea of noise that buries actual critical issues.
Transition from Reactive Support to Intelligent Operations
Engineers realized that manual management could not keep up with the speed of cloud-native development. The transition to intelligent operations involves moving away from manual, ticket-based responses. Instead, organizations now implement systems that learn from historical data, automatically grouping related alerts and suggesting potential fixes before human intervention is required.
Enterprise Adoption Across Large-Scale Ecosystems
Large organizations face the most pressure to modernize because their infrastructure is too vast for human teams to monitor manually. By adopting AI-driven platforms, these enterprises unify data from cloud environments, on-premise hardware, and container clusters. This centralization is the prerequisite for achieving true operational resilience at scale.
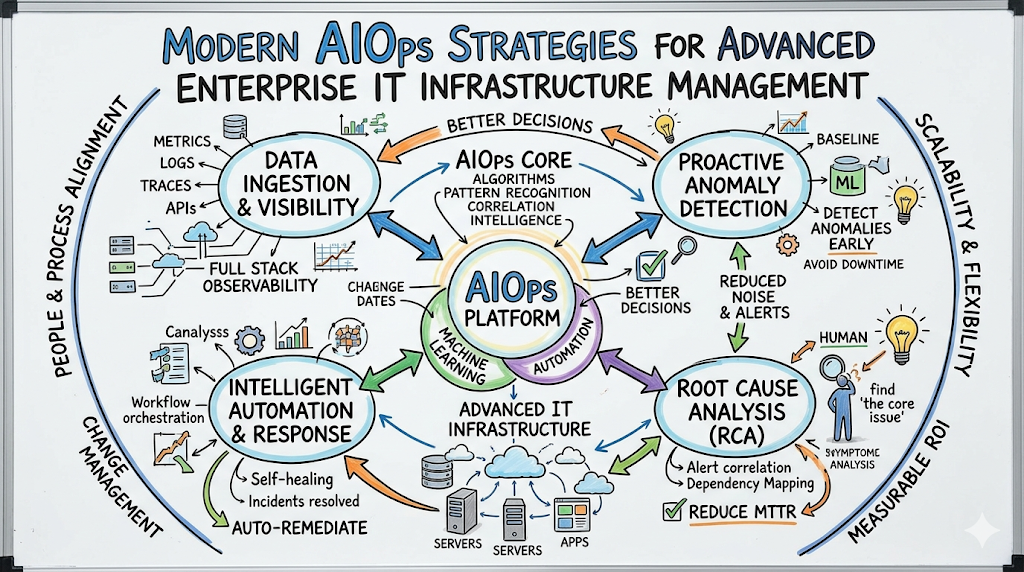
Defining Modern AIOps Architecture
The Core Foundation of AIOps Platforms
An AIOps platform acts as an intelligence layer on top of your existing tools. It ingests logs, metrics, traces, and events through pipelines. An analytics engine then processes this data, applying algorithms to detect anomalies and cluster related information into meaningful insights.
Daily Responsibilities of AIOps Engineers
Engineers in this space don’t just “monitor” systems. Their daily work involves building data pipelines, fine-tuning machine learning models to reduce noise, and writing automation scripts that handle incident remediation. They act as the bridge between raw infrastructure data and actionable business intelligence.
Event Correlation vs. Root Cause Analysis
Event correlation is the process of grouping multiple related alerts into a single incident. Root Cause Analysis (RCA) takes this a step further by identifying the specific service or code change that triggered the event. While correlation reduces the noise, RCA provides the answer to “Why did this happen?”
The Predictive Operations Mindset
Adopting a predictive mindset means moving from “What is wrong?” to “What is about to break?” By analyzing performance trends, AI models forecast potential capacity issues or memory leaks. This allows engineers to perform maintenance during low-traffic windows rather than scrambling during an unexpected outage.
The 7 Core Principles of Introduction to AIOps: Revolutionizing IT Operations
1. Intelligent Event Correlation
These systems recognize that a web server error, a database timeout, and a load balancer alert are all symptoms of one underlying network latency issue. By clustering these alerts, the system presents one incident to the team instead of fifty individual notifications.
2. Predictive Analytics and Anomaly Detection
Machine learning algorithms baseline “normal” behavior for your systems. When a server’s CPU usage climbs slowly over time, the system recognizes this as an anomaly compared to the historical norm, allowing for proactive scaling before the service crashes.
3. Automation of Repetitive IT Tasks
Many IT tasks are mundane, such as restarting services, clearing caches, or generating ticket reports. Automation engines execute these actions the moment a recurring issue is identified, freeing up engineers to focus on higher-value development work.
4. Unified Observability Across Systems
Operational data often lives in silos—logs in one tool, metrics in another. AIOps unifies this data, creating a single “source of truth.” This visibility is essential for understanding how a failure in a backend database affects the end-user experience on a mobile app.
5. AI-Driven Incident Response
When an incident occurs, the system can automatically trigger a workflow that gathers diagnostics and notifies the correct team. Some advanced systems can even apply known “self-healing” patches to resolve issues without human interaction.
6. Continuous Learning and Optimization
Machine learning models are not static. As your infrastructure changes, the models learn from new data. This self-improving nature ensures that the system becomes more accurate at detecting true problems while ignoring irrelevant background noise over time.
7. Scalable Cloud-Native Operations
Managing a thousand microservices in Kubernetes is impossible without assistance. AIOps provides the capability to monitor and manage these dynamic environments, tracking ephemeral resources that exist only for seconds or minutes.
Key Operational Concepts You Must Know
AI vs. ML vs. AIOps — Explained Simply
- AI (Artificial Intelligence): The broad field of machines mimicking human intelligence.
- ML (Machine Learning): A subset of AI where systems learn from data patterns without explicit programming.
- AIOps: The specific implementation of these technologies to solve IT operational challenges.
Event Correlation — The Backbone of Modern AIOps
Without correlation, every single device creates its own stream of alerts. Correlation is the filter that transforms thousands of data points into a single, actionable event that an engineer can actually understand and investigate.
Alert Fatigue — The Silent Productivity Killer
Alert fatigue happens when engineers are bombarded with so many notifications that they stop paying attention. It is a major cause of burnout and leads to missed critical incidents. Intelligent platforms solve this by reducing the volume of alerts to only those that require human action.
Incident Management & Automated RCA
Modern incident management uses AI to suggest potential causes based on past occurrences. If a similar issue happened last month, the system can point the engineer toward the fix that worked previously, drastically reducing the time spent searching for answers.
Capacity Forecasting
Instead of waiting for an out-of-memory error, the system analyzes traffic growth and storage consumption. It tells you exactly when you will run out of resources, helping you plan infrastructure upgrades months in advance.
The Four Pillars of Intelligent Observability
- Logs: The textual history of events.
- Metrics: Numerical data representing performance over time.
- Traces: Information about how a request moves across services.
- Events: Specific occurrences that signal a state change.
Traditional IT Operations vs. AIOps — What’s the Real Difference?
The Philosophy Difference
Traditional operations are reactive—you wait for something to break and then fix it. AIOps philosophy is proactive and data-centric—you use history to predict and prevent problems before they impact the user.
Roles & Responsibilities Compared
- Traditional: Focuses on manual monitoring, ticket resolution, and patching servers.
- AIOps: Focuses on data engineering, model tuning, automation design, and observability architecture.
Can Traditional Monitoring and AIOps Work Together?
Absolutely. AIOps sits on top of your existing monitoring tools. You do not have to discard your current infrastructure; rather, you feed the data from those tools into an AIOps engine to gain more intelligence from the data you already collect.
Which Operational Model Should Your Organization Adopt?
Organizations with high traffic, distributed architectures, or multi-cloud setups should adopt AIOps immediately to maintain sanity. Smaller organizations may start with basic automation before scaling to full-scale AI-driven observability.
Real-World Use Cases of Modern AIOps
Predictive Incident Detection in Enterprises
A retail website identifies that a specific checkout API is slowing down every Friday evening. The AI detects the trend, alerts the team on Wednesday, and the engineers increase capacity before the surge happens.
AI-Powered Root Cause Analysis
During a network outage, the platform traces the error back to a recent configuration change in a specific load balancer. It instantly highlights the exact line of code that caused the conflict.
Managing Reliability in Multi-Cloud Environments
An enterprise uses both AWS and Azure. AIOps aggregates logs from both clouds into one view, allowing the team to see how a database spike in one cloud affects the performance of an application hosted in the other.
AIOps in Financial and Banking Platforms
Banking systems require near-zero downtime. AIOps monitors transaction latency in real-time, detecting any deviation in performance and instantly failing over to secondary systems if a component shows signs of instability.
Lightweight AIOps Strategies for Startups
Startups often have limited staff. A lean AIOps approach focuses on automating basic alerts and using simple anomaly detection to reduce the need for a 24/7 on-call rotation of ten different engineers.
Common Mistakes in AIOps Implementation
Mistake 1 — Treating AIOps as Just Another Monitoring Tool
AIOps is a methodology, not just a software download. You must change your internal processes to embrace automation and data-driven decision-making, or the tools will provide no value.
Mistake 2 — Ignoring Data Quality Issues
If you feed “garbage” data into your AI models, you will get “garbage” insights. Ensure your logs are structured and your metrics are accurate before attempting to run complex correlation algorithms on them.
Mistake 3 — Automating Broken Processes
Automating a bad process just makes it fail faster. Before you use AI to automate your incident response, ensure that your underlying manual processes are sound, documented, and effective.
Mistake 4 — Overlooking Human Collaboration
AI is meant to support the engineer, not replace the need for communication. Teams must still work together to define which alerts are critical and how they should be routed to human responders.
Mistake 5 — Excessive Alert Configuration
Setting the sensitivity of your AI models too high can lead back to alert fatigue. Spend time calibrating your systems to ensure they only notify humans when action is truly required.
Mistake 6 — Delaying AI Adoption in Cloud-Native Infrastructure
The complexity of modern applications grows faster than human capacity. Relying on manual monitoring in a containerized environment is a recipe for disaster; start small and scale your AI adoption early.
Essential AIOps Tools & Technologies
Monitoring & Observability Platforms
Tools like Prometheus, Datadog, and Dynatrace gather the raw data. They serve as the eyes and ears of your infrastructure, providing the telemetry that the AI will analyze.
Incident Management Solutions
Platforms like PagerDuty or ServiceNow organize the alerts. They are the coordination layer that ensures the right engineer gets the notification at the right time.
Automation & Orchestration Platforms
Technologies used to execute remediation scripts. Once the AI identifies an issue, these platforms perform the actual server restarts or configuration rollbacks.
Machine Learning & Analytics Engines
The “brain” of the operation. These engines process the streams of data from your monitoring tools to detect patterns and anomalies that humans would never see.
Cloud & Kubernetes Monitoring
Specialized tools that understand the ephemeral nature of pods and clusters, ensuring that you monitor the application performance rather than just the underlying host server.
Becoming an AIOps Professional — Career Roadmap
Essential Skills Every AIOps Engineer Needs
You need a solid foundation in Linux, networking, and cloud platforms. You must also become proficient in Python or Go for automation, understand data science basics for AI, and master the observability stack.
Step-by-Step Professional Learning Path
Start by mastering traditional monitoring and logging. Once you have a deep understanding of infrastructure, move into learning how to automate those tasks. Finally, study how machine learning models process operational data to build your own intelligence layers.
Certifications Worth Pursuing
Focus on certifications related to Kubernetes, cloud-native observability, and general automation engineering. These credentials prove you can handle the complexities of modern infrastructure.
Educational Resources with [PROVIDER_NAME]
To accelerate your journey and gain a structured understanding of these technologies, explore the specialized certification programs and learning paths available at AIOpsSchool.
The Future of Intelligent IT Operations
AI-Driven Autonomous Infrastructure
The ultimate goal is the “self-healing” datacenter. This is an environment where the infrastructure detects, troubleshoots, and repairs its own failures without any human input.
Platform Engineering and Self-Service Operations
Engineers are building “Internal Developer Platforms” (IDPs). These platforms allow developers to deploy their own services while AIOps tools ensure that the underlying infrastructure remains stable and compliant.
AIOps in Kubernetes and Cloud-Native Ecosystems
As organizations move entirely to Kubernetes, the focus will shift to “service mesh” observability, where the communication between thousands of microservices is managed by intelligent AI agents.
Emerging Skills That Will Define Future Operations Teams
Future teams will require skills in FinOps (managing cloud costs with AI), observability engineering (designing the data stream), and data ethics (ensuring AI makes fair and unbiased operational decisions).
FAQ Section
- How does AIOps impact career growth for junior engineers?
AIOps shifts the career focus from repetitive manual monitoring to high-level automation and data analysis. This provides junior engineers with the opportunity to gain exposure to machine learning, big data, and complex architecture early in their careers. - Is a degree in data science required to work in AIOps?
No, a formal degree in data science is not required. While understanding algorithms is helpful, the most successful AIOps professionals have deep backgrounds in IT infrastructure, system administration, and software development. - What is the most effective way to start an AIOps implementation?
The best strategy is to start by identifying one high-noise area, such as a specific service that triggers too many false alerts. Implement event correlation on that single area first, learn from the results, and then scale your efforts to broader systems. - Do I need to replace my existing monitoring stack to use AIOps?
You do not need to replace your stack. AIOps is an “intelligence layer” that integrates with your existing tools, such as your logging systems and performance monitors, to add a layer of advanced analysis and automation. - How do AIOps platforms reduce operational burnout?
By automating repetitive troubleshooting tasks and suppressing irrelevant alerts, AIOps platforms ensure that engineers only focus on genuinely critical issues. This results in fewer middle-of-the-night interruptions and a more manageable workload. - Will AI eventually replace IT operations teams?
AI will not replace teams; it will evolve them. While AI handles the routine detection and repetitive remediation, human engineers will remain essential for architecting systems, handling complex edge cases, and making high-level strategic decisions about infrastructure.
Final Summary
Introduction to AIOps: Revolutionizing IT Operations is not merely a technical trend—it is a necessary evolution for any modern enterprise that relies on digital services. By moving from reactive manual troubleshooting to predictive, automated intelligence, teams can significantly improve uptime, reduce costs, and eliminate the burnout caused by constant alert fatigue. This is a journey of continuous improvement, and the best way to start is by building a strong foundation in observability and automation. To gain the skills and certification required to lead these transformations, visit AIOpsSchool and begin your path today.