Introduction
Modern IT teams are drowning in a sea of data. Every second, networks, servers, and cloud applications generate millions of alerts, logs, and metrics. This overwhelming volume leads to a massive problem known as alert fatigue, where critical system warnings get buried under a mountain of digital noise. When systems fail, enterprises lose revenue, customer trust drops, and IT teams face immense stress.
Traditional management systems can no longer keep up with this complexity. This is where Artificial Intelligence for IT Operations, commonly known as AIOps, steps in. AIOps combines big data, machine learning, and advanced analytics to automate and improve enterprise IT operations. Instead of waiting for a system to crash, it helps teams find, understand, and fix issues before they impact users. Enterprises need AIOps because modern tech infrastructures are too large and dynamic for manual tracking. Systems scale up and down in seconds across global cloud networks, making human-only monitoring nearly impossible. By shifting to intelligent operations, businesses can transform their data from a source of confusion into a source of clear, actionable insight. In this comprehensive guide, you will learn how AIOps platform features can optimize your infrastructure, reduce daily operational noise, and transform your IT workflows. If you want to build foundational skills in this revolutionary field, explore the educational resources and structured programs available at AIOpsSchool to start your learning journey today.
Evolution of Enterprise IT Operations
Traditional IT Monitoring Challenges
Years ago, IT environments were static and predictable. Applications lived on physical servers located in dedicated on-premise data centers, making them relatively simple to track.
When a problem occurred, a specific alert pointed directly to the broken hardware. Today, those simple environments have evolved into highly complex systems where finding the root cause of an issue feels like searching for a needle in a digital haystack.
Traditional monitoring tools work in isolated silos. The network team uses one dashboard, the database team uses another, and the cloud engineers use a third.
These separate tools do not talk to each other, creating a fragmented view of the entire infrastructure. When a major incident occurs, every department points fingers at the others, leading to delayed resolutions and extended outages.
Rise of AIOps Platforms
As enterprises migrated to multi-cloud environments and adopted microservices, traditional tracking systems began to crack under the pressure. The sheer volume of data generated by modern applications became too heavy for standard databases and human minds to process.
IT departments realized they needed a system that could aggregate data from every source, correlate it in real time, and extract meaningful patterns.
This operational gap led to the creation of dedicated AIOps platforms. By applying machine learning in IT operations, these advanced platforms can swallow massive streams of diverse data simultaneously. They analyze logs, metrics, events, and traces together, providing a single, unified view of the entire technology stack.
Shift Toward Intelligent IT Operations
We are witnessing a major shift from manual observation to intelligent, automated IT operations. In the past, engineers spent hours writing static rules and setting rigid thresholds, such as receiving an alert when CPU usage crossed a certain percentage.
However, fixed thresholds fail because normal behavior changes depending on the time of day, week, or season.
Intelligent operations replace those rigid rules with dynamic machine learning algorithms. These algorithms learn the unique baseline of an enterprise system over time.
They understand what normal traffic looks like on a Tuesday morning compared to a Saturday night, allowing them to spot true anomalies while ignoring harmless spikes.
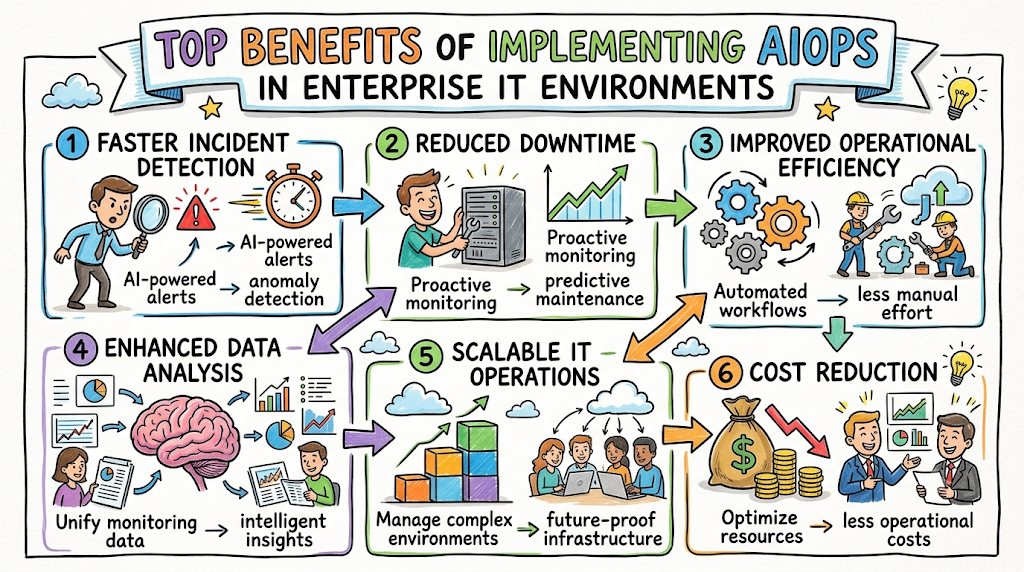
Core Benefits of AIOps in Enterprises
Faster Incident Detection and Resolution
When an enterprise application goes offline, every minute counts. AIOps dramatically cuts down the Mean Time to Detection (MTTD) and Mean Time to Resolution (MTTR) by identifying anomalies the moment they occur.
Instead of waiting for an end-user to file a complaint, the system flags unusual patterns instantly.
Once detected, the platform guides engineers straight to the source of the problem. By accelerating incident management, IT operations teams can resolve complex system glitches in minutes rather than hours. This speed minimizes business disruption and preserves the user experience.
Predictive IT Operations and Issue Prevention
The most significant benefit of intelligent systems is moving away from reactive firefighting. Through advanced predictive analytics, AIOps scans historical data trends to forecast potential system failures before they actually happen.
For example, the platform can predict that a storage disk will run out of space within three days based on its current consumption rate.
It can also detect a slow memory leak in an application days before the server crashes. This foresight allows teams to schedule preventive maintenance during off-peak hours, ensuring total business continuity.
Reduced Alert Fatigue
On a typical day, a large enterprise infrastructure can generate thousands of monitoring notifications. A vast majority of these alerts are duplicate warnings or meaningless background noise, causing engineers to suffer from severe alert fatigue.
When people are bombarded with constant notifications, they naturally start ignoring them, which often leads to missing a critical, high-priority warning.
AIOps solves this by grouping related notifications into a single, comprehensive incident. If a network switch fails, it might trigger a hundred individual alerts from connected servers.
The system groups those hundred alerts into one incident ticket, identifying the switch as the culprit and keeping the engineering team’s inbox clean.
Improved Root Cause Analysis
Finding the underlying reason behind a complex system crash is often the most time-consuming part of an engineer’s job. In a microservices architecture, a failure in one small service can ripple across dozens of dependent applications.
AIOps platforms excel at automated root cause analysis by tracing these complex dependencies.
The machine learning algorithms analyze the precise timing and relationship of events across different layers of the infrastructure.
Instead of showing a long list of symptoms, the platform points directly to the root cause, such as a misconfigured database query, saving hours of manual investigation.
Enhanced Operational Efficiency
By automating repetitive, low-level operational tasks, AIOps frees up IT staff to focus on high-value projects. Highly paid engineers no longer need to spend their mornings manually checking server logs, restarting stuck services, or sorting through low-priority support tickets.
This shift increases overall productivity across your technology departments.
Teams can dedicate their time to building new software features, upgrading infrastructure security, and improving system architecture, driving real business innovation.
Better System Visibility Across Infrastructure
Modern corporate environments are a mix of legacy on-premise hardware, private clouds, and multiple public cloud providers. Gaining a complete view of this hybrid landscape is incredibly challenging.
AIOps acts as a single pane of glass, offering comprehensive monitoring and observability across every layer.
It connects data points from diverse environments, allowing managers to see how a physical server in their office building affects a cloud application running across the world. This deep, end-to-end visibility ensures that no dark corners exist within the enterprise infrastructure.
Key Ways AIOps Transforms Enterprise IT
Automation of Repetitive IT Tasks
Enterprise IT automation is a cornerstone of digital transformation. AIOps platforms do not just find problems; they can also execute automated workflows to fix common, well-understood issues without human intervention.
- Automated Remediation: Running predefined scripts to clear disk space when storage fills up.
- Service Restarts: Automatically restarting a frozen application service if it stops responding.
- Ticket Creation: Opening, categorizing, and assigning incident tickets to the correct team instantly.
- Resource Scaling: Adding more cloud computing capacity during unexpected traffic surges.
Event Correlation and Noise Reduction
Event correlation is the process of finding meaningful connections between different data points. AIOps platforms use advanced algorithms to analyze thousands of data streams simultaneously, looking for patterns that match known issues or indicate new anomalies.
By correlating events across applications, networks, and databases, the platform filters out up to 90% of operational noise.
This drastic reduction allows your incident response teams to focus their energy entirely on genuine, business-critical problems.
Real-Time Performance Monitoring
Business happens in real time, and your monitoring systems must keep pace. AIOps processes data streams on the fly, offering instant insight into application performance and user behavior.
This live tracking ensures that performance drops are addressed before customers even notice a slowdown.
If an e-commerce checkout page begins to slow down by even a fraction of a second, the system detects the deviation immediately. It alerts the DevOps and cloud operations teams, allowing them to optimize performance before shopping carts are abandoned.
Data-Driven IT Decision Making
Too often, enterprise infrastructure planning relies on guesswork or historical habits. AIOps brings concrete data analytics to the decision-making process by analyzing long-term usage patterns across the entire organization.
Managers can accurately see which cloud assets are over-provisioned and under-utilized.
This visibility allows leaders to make smart, data-driven decisions regarding cloud spending, hardware purchases, and resource allocations, preventing wasted technology budgets.
Improved Collaboration Across IT Teams
When a major outage occurs, it is common for different departments to work in isolation, unaware of what other teams are doing to fix the issue. AIOps bridges these communication gaps by providing a single source of truth.
Because everyone looks at the same dashboard and analytical data, teams can collaborate smoothly. DevOps engineers, system administrators, and service desk managers can coordinate their response efforts, leading to faster consensus and more cohesive teamwork.
AIOps vs Traditional IT Operations
| Feature / Aspect | Traditional IT Operations | AIOps-Driven IT Operations |
| Operational Stance | Reactive: Responds after a failure occurs. | Proactive: Anticipates and prevents failures. |
| Analysis Method | Manual: Humans manually search logs and traces. | Automated: Machine learning instantly finds root causes. |
| Data Scope | Siloed: Disconnected data across separate tools. | Unified: Consolidated data from all infrastructure layers. |
| Threshold Settings | Static: Fixed limits that trigger false alarms. | Dynamic: Baselines that adapt to system changes. |
| Business Impact | High Downtime: Longer outages and high business costs. | High Availability: Minimal disruption and smooth operations. |
Real-World Enterprise Use Cases
Cloud Infrastructure Monitoring
Enterprises running huge cloud architectures face unique challenges, such as tracking hundreds of virtual machines and ephemeral container systems. AIOps constantly tracks these cloud environments, mapping out how different services communicate.
If a microservice running in a public cloud encounters an error, the platform traces its impact across all connected cloud resources, ensuring total stability.
Application Performance Management
User experience is directly tied to application performance. AIOps monitors application transaction journeys from end to end.
It keeps a close eye on database response times, third-party API connections, and frontend rendering speeds.
If a backend database update slows down the user application, the system highlights the exact query causing the slowdown, helping developers optimize the software code.
Incident Management Automation
In traditional setups, when a server fails, a helpdesk agent must manually read an alert, create a ticket, decide which team should handle it, and send an email. This manual process takes valuable time.
AIOps completely automates this lifecycle. It creates the ticket, adds all relevant diagnostic logs, identifies the root cause, and routes it to the specific engineer on duty within seconds.
DevOps Optimization
DevOps practices rely heavily on continuous deployment and continuous integration. When developers push new code updates multiple times a day, things can occasionally break.
AIOps platforms support DevOps and cloud operations by comparing system performance metrics before and after a software deployment.
If the new code update causes a sudden spike in errors or memory usage, the platform flags the change immediately, allowing the team to roll back the update safely.
IT Service Management (ITSM) Enhancement
IT Service Management benefits immensely from intelligent data analytics. By integrating with service desk ticketing software, AIOps helps managers identify recurring historical trends.
If employees frequently submit tickets about a specific VPN gateway, the platform highlights this trend, prompting IT leaders to upgrade the underlying network infrastructure permanently.
Common Challenges in AIOps Adoption
Poor Data Quality and Integration
Machine learning models require clean, comprehensive, and high-quality data to function properly. If an enterprise has fragmented systems, messy logs, or missing telemetry data, the platform will struggle to build accurate operational baselines.
Organizations must ensure their systems are properly configured to send consistent, structured data into the platform to avoid the classic “garbage in, garbage out” dilemma.
Lack of Skilled Teams
AIOps is a relatively new discipline that sits at the intersection of traditional IT operations, cloud architecture, and data science. Many enterprises struggle to find professionals who understand both system administration and basic machine learning concepts.
Overcoming this skills gap requires intentional, structured training for existing IT staff to help them adapt to modern, data-driven workflows.
Tool Overload and Complexity
Large companies often own dozens of legacy monitoring tools that have been acquired over many years. Introducing a complex platform on top of a messy, pre-existing tool stack can confuse engineers and increase operational complexity.
Success requires a clear strategy to phase out redundant legacy systems and centralize monitoring under a single platform.
Resistance to Automation
Human trust is a major cultural hurdle when implementing intelligent automation systems. Experienced engineers are often hesitant to allow an automated script to make changes, restart services, or modify cloud configurations on live production servers.
To build trust, organizations should start by deploying automation in “advisor mode,” where the system suggests fixes for humans to approve before granting full autonomy.
Misconfigured Alert Systems
If the initial setup of an analytical platform is rushed, the system might misinterpret normal operational spikes as critical threats, creating a wave of false positives.
Teams must dedicate time during the initial onboarding phase to calibrate the platform, allowing the machine learning algorithms to learn the true rhythms of the business infrastructure.
Essential AIOps Technologies (Conceptual Overview)
An effective intelligent infrastructure relies on a coordinated ecosystem of diverse technical modules working together harmoniously.
At the foundation are monitoring and observability tools that act as the eyes and ears of the enterprise, capturing raw performance metrics from every server, application, and cloud platform.
Next, log analytics systems and event management systems collect, clean, and organize these vast streams of operational data.
Once organized, dedicated AIOps platforms apply advanced machine learning models to correlate events, spot hidden anomalies, and isolate root causes across hybrid environments.
Finally, cloud monitoring platforms provide specialized tracking for dynamic, scalable cloud infrastructure, ensuring that every layer remains visible and secure.
Career Path in AIOps for IT Professionals
Skills Required
To thrive in this evolving landscape, traditional IT professionals need to expand their skill sets beyond basic system administration.
- IT Operations Basics: Deep understanding of server operating systems, networking protocols, and enterprise storage.
- Cloud Computing Fundamentals: Practical knowledge of major public cloud architectures and container systems.
- Data Analytics Basics: Ability to read data trends, understand metrics correlation, and interpret analytical dashboards.
- DevOps Knowledge: Understanding continuous integration, continuous delivery (CI/CD) pipelines, and agile workflows.
- Monitoring Tools Understanding: Familiarity with tracing, log aggregation, and system observability concepts.
- Scripting Fundamentals: Basic coding knowledge in languages like Python or Bash to assist in building automated workflows.
Learning Roadmap
Start your career transition by mastering foundational system administration and network operations. Once comfortable, move into cloud computing and learn how modern microservices architecture operates.
Next, focus on understanding monitoring principles, learning how to collect logs, track metrics, and follow application traces.
Finally, dive into data science concepts to learn how machine learning algorithms identify patterns, predict capacity constraints, and isolate system anomalies.
Certifications & Learning Paths
Professional certifications are a fantastic way to validate your skills and stand out to enterprise recruiters. Focus on pursuing vendor-neutral certifications centered on cloud architecture, DevOps methodology, and modern site reliability engineering (SRE).
Additionally, look for specialized educational programs that focus on data analytics, event correlation, and automated incident response workflows.
Career Opportunities
The demand for professionals skilled in intelligent operations is exploding across the global tech sector. Organizations are actively recruiting for specialized positions such as AIOps Engineers, Site Reliability Engineers (SRE), Cloud Operations Managers, and IT Automation Specialists.
These high-value roles offer excellent compensation, strong job security, and the chance to work on cutting-edge enterprise technology stacks.
Learning Resources from AIOpsSchool
If you are ready to update your career for the future of technology infrastructure, structured education is your best step forward.
By leveraging the comprehensive courses, guided tutorials, and foundational learning pathways offered by AIOpsSchool, you can bridge the gap between traditional IT management and modern AI-driven operations, ensuring your skills remain highly marketable.
Future of AIOps in Enterprises
Autonomous IT Operations
The ultimate goal of intelligent systems is the realization of fully autonomous IT operations. In this future state, enterprise networks will function much like self-driving vehicles.
The underlying systems will constantly monitor their own performance, spot inefficiencies, deploy updates, and adjust configurations independently, requiring minimal human intervention.
Self-Healing Infrastructure
We are moving rapidly toward self-healing infrastructure. When a system component breaks, degrades, or faces a security threat, the environment will patch and repair itself in real time.
If a database becomes corrupted, the system will instantly spin up a clean replica, sync missing data, and reroute active users without a single second of visible downtime.
AI-Driven Incident Management
Future incident management will be entirely handled by intelligent agents. These advanced systems will not only find and fix root causes but will also write their own post-incident reviews.
They will document what broke, explain how it was resolved, and automatically update system code to ensure that specific type of failure can never happen again.
Predictive Enterprise Monitoring
As machine learning models become more sophisticated, predictive monitoring will extend far beyond tracking hardware metrics.
Systems will analyze global business contexts, weather patterns, economic shifts, and consumer behavior trends to predict infrastructure demand days or weeks in advance.
This foresight allows enterprises to scale their infrastructure perfectly to match complex business rhythms.
Future Skills in AIOps
As routine monitoring and basic troubleshooting become fully automated, the role of the IT professional will shift significantly.
Engineers will spend less time fixing broken servers and more time designing resilient architectures, training machine learning models, and managing data pipelines.
Adaptability, analytical thinking, and a strong understanding of automation logic will be the most valuable skills for tech professionals moving forward.
FAQs
- What is AIOps and how does it work?
AIOps stands for Artificial Intelligence for IT Operations. It works by collecting massive amounts of logs, metrics, and alerts from your IT infrastructure and applying machine learning algorithms to find patterns, clear out noise, and identify system anomalies. - What are the primary benefits of AIOps for large enterprises?
The biggest benefits include faster resolution of system failures, a massive reduction in duplicate alert notifications, automated root cause analysis, and the ability to predict and prevent infrastructure crashes before they impact customers. - How does AIOps improve enterprise incident management?
It automates the entire process by instantly detecting anomalies, grouping related alerts into a single incident, pinpointing the exact root cause, and automatically assigning tickets to the right engineers along with relevant diagnostic data. - Can AIOps predict system failures before they happen?
Yes, it uses predictive analytics to study historical performance trends and identify early warning signs of failure, such as slow memory leaks or gradual storage exhaustion, allowing teams to fix issues proactively. - What is the difference between traditional monitoring and AIOps?
Traditional monitoring tells you when a system component breaks based on rigid, manual rules. AIOps uses machine learning to dynamically understand normal behavior across your entire ecosystem, predicting issues and finding root causes automatically. - How does AIOps help DevOps and cloud operations teams?
It provides complete visibility across dynamic cloud environments and automatically evaluates system performance before and after code deployments, helping DevOps teams quickly catch errors introduced by new updates. - What is event correlation and why is it important?
Event correlation is the process of linking separate, related alerts across different infrastructure layers into a single event. It is crucial because it filters out distracting digital background noise, allowing teams to focus on real issues. - What are the main challenges when adopting AIOps platforms?
Common hurdles include poor data quality from legacy systems, a lack of skilled professionals who understand both IT operations and data analytics, tool complexity, and internal cultural resistance to automated changes. - What career opportunities are available in the AIOps space?
There is booming demand for specialized roles such as AIOps Engineers, Site Reliability Engineers (SRE), IT Automation Specialists, and Cloud Operations Managers who can design and oversee intelligent systems. - How can a beginner start learning about AIOps?
Beginners should focus on mastering IT infrastructure basics, cloud computing foundations, and monitoring concepts. Taking structured online courses and leverage training platforms like AIOpsSchool can help build these in-demand skills systematically.
Conclusion
The transition from traditional, manual IT monitoring to modern, intelligent automation is no longer a luxury for large enterprises; it is a necessity for survival. As data landscapes grow more complex, AIOps platforms provide the critical visibility, speed, and intelligence needed to keep systems online and running efficiently.
By leveraging machine learning in IT operations, businesses can move away from stressful reactive troubleshooting and step into a new era of predictive IT operations. Embracing event correlation, automated task remediation, and deep root cause analysis helps businesses protect their customer experience and optimize infrastructure spend.
To stay ahead of the curve in this rapidly changing technological environment, keeping your skills current is absolutely essential. Whether you are an experienced systems administrator or an ambitious IT beginner, explore the expert educational programs provided by AIOpsSchool to master the future of intelligent IT operations today.