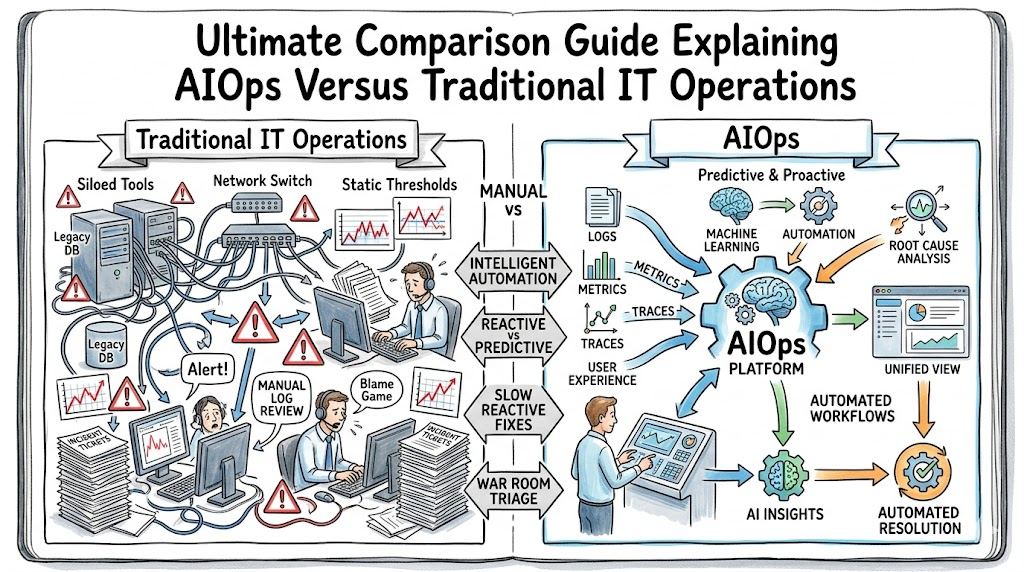
Introduction
This massive scale mismatch is precisely why global enterprises are rapidly shifting toward intelligent operational systems. Organizations are moving away from siloed monitoring setups and adopting Artificial Intelligence for IT Operations, commonly known as AIOps. By injecting machine learning into infrastructure pipelines, businesses can spot system anomalies and resolve outages before their users notice a thing. In this ultimate comprehensive guide, we will break down everything you need to know about this major tectonic shift in technology management. You will discover how modern platforms handle telemetry data, explore the critical structural differences between legacy environments and automated frameworks, and learn how to position your technical career for this transformation. If you are ready to master these advanced enterprise strategies, you can explore structured educational programs at AIOpsSchool.com to accelerate your transition into modern automated engineering.
Understanding Traditional IT Operations
What Traditional IT Operations Means
Traditional IT operations, frequently referred to as ITOM (IT Operations Management) or legacy operations, centers around maintaining corporate infrastructure through human oversight and static rules. In this older model, administrators build infrastructure components and then deploy distinct software agents to track whether those specific components are online or offline.
This methodology operates on a strictly deterministic basis. A system administrator must tell the monitoring platform exactly what conditions constitute a failure. The underlying system does not learn from historical trends, nor does it dynamically adapt when traffic patterns shift unexpectedly throughout the normal business day.
Core Responsibilities of Traditional IT Teams
Legacy infrastructure teams operate within functional silos, where each group focuses entirely on its own specific layer of the technology stack. The network team configures switches, routers, and firewalls while keeping an eye on bandwidth utilization.
Meanwhile, the database administrators tune storage engines and check query execution times. The server team provisions virtual machines and monitors basic system health metrics like CPU usage and memory consumption.
The primary responsibility of these engineering teams is to keep their specific silo operational. They review historical logs, run manual compliance checks, configure scheduled data backups, and perform routine patches during late-night maintenance windows.
When a new application goes live, these teams work independently to provision resources according to rigid, pre-planned specifications.
Common Challenges in Legacy IT Environments
The biggest bottleneck in legacy infrastructure management is the fragmentation of data. Because every team uses its own distinct vendor tools, information remains locked inside isolated software applications.
The network engineers look at one dashboard, the storage team tracks another, and the application developers use completely separate tracing software.
When a complex cross-domain failure occurs, engineers lack a single cohesive source of truth. This fragmentation leads to prolonged finger-pointing during critical outages.
Furthermore, because these systems cannot correlate events automatically, teams spend hours trying to piece together a coherent timeline of events while the business loses revenue.
Manual Monitoring and Reactive Problem Solving
Legacy monitoring relies almost completely on static thresholds. An administrator might configure an alert stating: “If server CPU utilization exceeds 85% for more than five minutes, send an email to the on-call engineer.”
While this sounds logical on paper, it creates massive problems in practice. If a cluster of one hundred servers experiences a temporary, harmless spike in traffic, the system will fire off one hundred distinct emails simultaneously.
This operational approach is inherently reactive. The infrastructure monitoring system only alerts the engineering team after a metric crosses a pre-set threshold.
Consequently, the operational workflow is constantly playing catch-up, forcing engineers to act as firefighters dealing with active emergencies rather than proactively optimizing system reliability.
Understanding AIOps
What is AIOps?
AIOps stands for Artificial Intelligence for IT Operations. The term describes the strategic integration of big data analytics, machine learning algorithms, and automation frameworks into corporate technology infrastructure.
Instead of waiting for human operators to write manual rules, an AIOps platform continuously ingests massive streams of operational data from every single layer of the enterprise ecosystem.
The platform evaluates this information in real time, automatically establishing a dynamic baseline of normal operational behavior. By applying advanced algorithmic analysis, it can detect subtle deviations, uncover hidden data correlations, and initiate automated scripts to resolve system anomalies without human intervention.
Core Components of AIOps Platforms
A modern AIOps architecture is built upon a foundation of three interconnected layers:
- Data Collection and Ingestion: This component acts as a centralized data vacuum. It continually gathers structured and unstructured information across the entire organization, pulling in API logs, operating system metrics, network packets, user clickstreams, and support ticket descriptions.
- Machine Learning Analytics: This analytical engine processes the ingested data. It filters out normal background system noise, links related events together across disparate systems, and flags suspicious performance dips.
- Automation and Orchestration: The action layer connects directly to configuration engines and cloud APIs. Once the machine learning engine confirms a root cause, this component executes automated workflows to repair the problem instantly.
Machine Learning and Automation in IT Operations
At the heart of an AIOps platform are sophisticated mathematical models trained on historical infrastructure telemetry. These algorithms use unsupervised learning to study how applications interact with underlying hardware under various real-world conditions.
For instance, if an enterprise application experiences a massive surge in user log-ins every payday morning, a traditional system might trigger critical alerts due to high CPU usage.
An AIOps platform recognizes this recurring cyclical pattern from historical data. It suppresses unnecessary alarms and proactively commands cloud APIs to provision more container instances ahead of the surge.
Real-Time Monitoring and Predictive Analytics
AIOps transforms enterprise monitoring from a reactive historical review into a forward-looking predictive system. It analyzes live streams of telemetry data sequentially, evaluating thousands of variables simultaneously to identify early indicators of impending hardware or software degradation.
Instead of notifying an operator that a database disk drive has filled up and crashed the application, an AIOps platform detects that a log file is expanding at an abnormal mathematical velocity.
It predicts that the disk will run out of space in exactly forty-two minutes, flags the precise process causing the issue, and expands the cloud storage volume automatically before any operational failure can occur.
AIOps vs Traditional IT Operations — Major Differences
Monitoring Approach
Traditional IT operations relies on fragmented, point-in-time monitoring. Each component is viewed as an independent island, requiring separate specialized tools to track status.
In sharp contrast, AIOps uses holistic, continuous observability. It unites all infrastructure data inside a unified big data lake, allowing the platform to observe the health of the entire enterprise ecosystem through a single cohesive viewport.
Incident Detection Speed
Legacy environments depend entirely on human speed. When something goes wrong, the system waits for a static metric to break, generates an incident ticket, and drops it into a queue for an engineer to review.
An AIOps approach utilizes real-time algorithmic inspection. It catches micro-anomalies the moment they deviate from standard mathematical baselines, flashing early warnings hours before a legacy threshold would ever be breached.
Root Cause Analysis
When a major app failure strikes a traditional IT setup, engineers must manually log into individual servers, download text files, and cross-reference timestamps across different time zones to figure out what went wrong.
An AIOps platform accomplishes this instantly. By using graph analytics and event correlation, it automatically links related symptoms together, tracing the path of destruction back to the single upstream code deployment or bad configuration change that triggered the mess.
Automation Capabilities
Automation in traditional environments is limited, static, and script-dependent. A human operator must manually trigger a custom script after a problem has been found.
AIOps introduces closed-loop, intelligent orchestration. The platform not only diagnoses the system failure but can also automatically execute complex diagnostic routines and run corrective playbooks to fix the issue end-to-end without needing a human to click a button.
Scalability and Cloud Readiness
As corporate networks scale up by adding thousands of temporary microservices and cloud containers, traditional configuration models break down entirely. Human teams simply cannot write manual rules fast enough to keep pace with modern auto-scaling infrastructure.
AIOps platforms are natively built for cloud-scale operations. They discover new computing nodes the moment they are provisioned, automatically applying machine learning models to them without requiring any manual configuration.
Data Processing and Alert Management
Legacy systems easily suffer from alert fatigue. Because they evaluate metrics in total isolation, a single network switch failure can set off thousands of distinct alarms across every single connected server and application.
AIOps filters out this overwhelming operational background noise. It groups those thousands of separate alarms into a single, comprehensive incident case file, showing engineers exactly how the switch failure impacted downstream business processes.
Operational Efficiency
Traditional environments tie operational productivity directly to human headcounts. If your infrastructure doubles in size, you typically have to double the number of triage engineers just to manage the incoming ticket volume.
AIOps breaks this dependency. By automating the routine work of log analysis and basic troubleshooting, a lean operations team can easily manage thousands of distributed applications simultaneously.
Infrastructure Visibility
Traditional operations offers limited visibility across modern complex enterprise architectures, leaving teams blind to how different infrastructure layers interact.
AIOps establishes deep end-to-end observability. It maps the complex hidden dependencies between web fronts, background databases, container networks, and third-party APIs, giving teams full structural visibility across the entire enterprise ecosystem.
Human Dependency vs Intelligent Automation
In a traditional IT operational model, system uptime is entirely dependent on the continuous presence of highly specialized human experts. If the key database engineer goes on vacation, an outage can drag on for hours.
AIOps shifts this dynamic toward intelligent automation. The system captures institutional operational knowledge within its machine learning models, allowing the software itself to handle routine triage and complex system restorations.
Key Benefits of AIOps Over Traditional IT Operations
Faster Incident Response
By stripping manual validation out of the incident management lifecycle, AIOps dramatically cuts down your Mean Time to Resolution (MTTR). The platform intercepts anomalies in real time, correlates the data instantly, and identifies the core problem in seconds rather than hours.
According to data from the Mean Time to Resolution (MTTR) research studies across global enterprise infrastructures, implementing machine learning data correlation can reduce the time spent identifying the root cause of an outage from hours down to under three minutes.
Reduced Alert Fatigue
Alert fatigue is an incredibly dangerous problem in modern enterprise command centers. When engineers receive hundreds of low-priority alarms every hour, they naturally start ignoring them, which eventually causes them to miss critical warnings.
AIOps solves this by compressing high-volume alert streams into a handful of actionable insights. It squashes the background noise so your engineering teams can focus their full attention on genuine system emergencies.
Improved System Reliability
Because AIOps operates continuously without getting tired, it catches early infrastructure vulnerabilities long before they snowball into critical site outages. This constant vigilance keeps your digital business platforms highly stable and resilient.
For instance, an e-commerce platform can keep its check-out systems running flawlessly during peak holiday shopping surges because the underlying software automatically balances database connections ahead of traffic spikes.
Predictive Issue Detection
Moving from reactive troubleshooting to predictive prevention completely changes how operations teams work. AIOps allows you to fix infrastructure vulnerabilities before they impact your paying customers.
Instead of dealing with an emergency call about an active outage, your on-call engineers receive a predictive notice explaining that a specific memory leak will cause a service interruption in two hours if left unpatched, allowing them to fix it calmly during regular business hours.
Better Resource Optimization
Corporate cloud budgets can spiral out of control when teams over-provision virtual instances just to handle occasional traffic spikes safely.
AIOps platforms continuously analyze actual system performance requirements over time. The platform pinpoints under-utilized computing nodes and suggests precise down-sizing configurations, helping companies maximize their infrastructure utilization and cut unnecessary cloud spending.
Enhanced Customer Experience
In our modern digital economy, application downtime directly translates into lost corporate revenue and damaged brand reputation. If an online application is slow or unresponsive, users will simply leave and go to a competitor.
By identifying performance drops and resolving application bottlenecks behind the scenes, AIOps ensures that your customers always enjoy a fast, reliable, and smooth digital experience.
Improved Operational Scalability
As companies grow through mergers, acquisitions, and rapid global expansion, their underlying technology infrastructure naturally becomes incredibly complex.
AIOps provides the foundational architecture needed to scale up smoothly. Because the platform uses intelligent algorithms rather than manual oversight to monitor your systems, your business can scale its infrastructure indefinitely without being held back by manual operations.
Challenges of Traditional IT Operations
Manual Workloads
Legacy IT teams spend the vast majority of their working hours dealing with repetitive, low-value manual tasks. They spend their days manually cleaning out full disk drives, restarting stuck software services, tracking down missing logs, and filling out identical incident reports.
This heavy manual workload drains team productivity and leaves engineers with very little time to work on valuable system upgrades or strategic infrastructure improvements.
Siloed Teams and Systems
When an enterprise runs its operations within isolated technical silos, collaboration completely breaks down. Each team guards its own data closely and uses different vendor tools, creating major communication barriers.
When a multi-layer system failure occurs, this lack of visibility leads to defensive blame-shifting on bridge calls, extending application downtime while teams argue over whose dashboard is showing the correct data.
Slow Root Cause Identification
Without automated cross-domain data correlation, finding the true root cause of an enterprise outage is like trying to find a needle in a haystack. Engineers have to manually scan through millions of lines of text logs across dozens of separate machines.
This slow process means that even if a fix takes only two minutes to deploy, the team might spend four hours just trying to find out where the broken line of code is located.
Limited Visibility Across Infrastructure
Legacy monitoring systems are completely blind to the modern dynamic interactions that happen within containerized software clusters and hybrid clouds. They can tell you if a specific bare-metal server is turned on, but they cannot track how a containerized microservice is communicating across distributed cloud regions.
This lack of visibility creates massive blind spots, making it incredibly difficult to find and fix intermittent performance drops.
Difficulty Managing Hybrid and Cloud Environments
Modern enterprise architectures rely heavily on a complex mix of on-premise hardware, private virtualization layers, and multiple public cloud providers. Legacy operational tools were never designed to handle these highly fluid environments.
They struggle to track cloud resources that scale up and down dynamically, leaving managers with an inaccurate view of their live environment and exposed to hidden security vulnerabilities.
Real-World Use Cases of AIOps
AIOps in Cloud Infrastructure
In a massive hybrid cloud deployment running tens of thousands of automated microservices, an AIOps platform acts as an intelligent traffic controller. For instance, a cloud operations team receiving thousands of alerts daily can use AIOps to reduce alert fatigue.
The platform continuously monitors container orchestrators like Kubernetes, tracking microsecond variations in network latency and memory usage.
If a specific container node begins to fail, the AIOps platform flags the anomaly, diverts live user traffic to a healthy zone, and spins down the damaged container to launch a fresh copy without any manual help.
AIOps for Cybersecurity Monitoring
Modern cyber threats move far too quickly for traditional security log tools to catch. An AIOps platform acts as an intelligent security layer by analyzing user behavior patterns across all enterprise systems simultaneously.
For example, if an employee account logs in from New York and then attempts to download an unusual volume of database files from an IP address in Europe just ten minutes later, the platform spots this anomaly.
It links the network logs with application access records, identifies the potential credential theft, and suspends the account permissions instantly to prevent a data breach.
AIOps in Fintech Systems
Imagine a banking application processing millions of transactions where downtime directly impacts customer trust and regulatory compliance. In these high-stakes financial environments, even a slight delay in transaction processing can cost millions of dollars.
An AIOps platform monitors the complete transaction path, tracking data from the mobile user interface through security mainframes down to core accounting ledgers.
If an database lock slows down transactions by even a few milliseconds, the platform detects the bottleneck, traces it back to a stuck query, and safely switches resources to optimize transaction speeds.
AIOps for E-Commerce Platforms
During major online flash sales, e-commerce websites experience massive spikes in user traffic that can easily crush standard server infrastructures. An AIOps platform continually watches user behavior trends, shopping cart creations, and payment check-out success rates.
If the system detects that a surge in user traffic is beginning to slow down page load times on the checkout page, the machine learning engine dynamically provisions extra web servers ahead of time, ensuring a smooth shopping experience for every customer.
AI-Based Incident Correlation in Enterprise IT
For a large global corporation running distributed offices across multiple continents, a single core power failure at a regional data center can trigger an absolute nightmare of overlapping incident tickets.
An AIOps platform uses advanced language processing and topological data mapping to analyze this flood of alerts as it hits the helpdesk.
The platform instantly recognizes that the hundreds of seemingly separate issues—like disconnected office phones, failed VPN connections, and offline local email servers—are all downstream symptoms of the main data center power failure, automatically grouping them into a single parent ticket for the core infrastructure team.
Important Technologies Behind AIOps
Artificial Intelligence
Artificial Intelligence provides the high-level reasoning framework that allows an operational platform to understand complex context and make smart system decisions.
Instead of blindly following rigid, pre-written rules, the AI engine evaluates data inputs from multiple angles, evaluates potential risks, and chooses the absolute best path to fix system issues based on the business priorities of the enterprise.
Machine Learning
Machine Learning forms the analytical muscle of the platform, utilizing both supervised and unsupervised mathematical algorithms.
These mathematical models study historical system performance over weeks and months, mapping out normal behavior patterns for every day of the year. This continuous learning allows the platform to adjust its alert thresholds automatically as the business grows, completely eliminating the need for manual tuning.
Big Data Analytics
Because modern enterprises generate massive quantities of operations data every day, an AIOps platform requires a powerful big data engine to store and process this information.
Using high-performance data technologies, the platform easily streams, indexes, and analyzes petabytes of log entries, metric counters, and network traces simultaneously, turning messy raw data into clear operational insights.
Observability Platforms
Observability goes far beyond basic system monitoring by analyzing the internal states of an application based entirely on its external outputs.
By tracking the “three pillars of observability”—metrics, logs, and distributed traces—AIOps platforms get a deep, crystal-clear understanding of exactly how data flows through complex, multi-layered enterprise application architectures.
Automation and Orchestration
The automation engine acts as the hands of the AIOps platform, turning insights into real-world action.
By connecting with modern configuration management tools, infrastructure-as-code deployment engines, and cloud network APIs, this component safely executes complex recovery scripts, modifies network configurations, and builds new infrastructure components on the fly.
Predictive Monitoring
Predictive monitoring uses advanced statistical analysis and time-series forecasting to look into the future of your infrastructure health.
By calculating mathematical trends from current usage data, these algorithms can project exactly when a system will run out of space, run out of memory, or hit a performance bottleneck, letting engineers fix vulnerabilities long before they cause problems.
Common Misconceptions About AIOps
AIOps Replaces IT Teams
A very common myth is that adopting AIOps will immediately lead to mass layoffs within IT infrastructure departments. This is simply not true.
In reality, AIOps platforms are designed to assist human engineers, not replace them. The software takes care of the exhausting, repetitive tasks like filtering out noise and digging through logs, freeing up your human experts to focus on high-value projects like building resilient architectures and driving technology innovation.
AIOps is Only for Large Enterprises
Many mid-sized companies believe that AIOps is an overly expensive, hyper-complex technology that is only useful for massive global corporations.
While large enterprises certainly benefit from it, modern cloud-based AIOps tools make this technology accessible to growing businesses as well. Any company managing hybrid infrastructure or running customer-facing web apps can use AI tools to improve their uptime and boost team efficiency.
Automation Removes Human Control
Some infrastructure managers worry that letting an AI platform run automated scripts will lead to unpredictable system behavior or accidental outages.
In practice, AIOps implementations give you total control over automation boundaries. Teams configure the platform to run under strict guidelines, often setting it up to require a human engineer to review and approve major system changes before they go live.
AIOps is Difficult to Implement
There is a common misconception that adopting AIOps requires a complete, risky, top-to-bottom replacement of your entire existing technology stack.
The reality is that AIOps platforms are built to connect smoothly with your current infrastructure. They ingest data directly from the monitoring tools, cloud accounts, and ticketing databases you already use, allowing you to roll out intelligent capabilities step by step without any business disruption.
AIOps Implementation Best Practices
Start with Observability
You cannot analyze data that you aren’t actually collecting. Before you try to roll out advanced machine learning models, make sure your infrastructure has solid, comprehensive telemetry coverage.
Ensure that all of your core applications, distributed database engines, and network channels are actively exporting clean logs, granular metrics, and distributed traces into a central repository.
Centralize Operational Data
To break down the data silos that cripple legacy operations teams, you must bring all of your operational data into a single unified location.
Route every single data stream—including infrastructure alarms, application performance traces, security logs, and even helpdesk change tickets—into a centralized data lake so your AI engine can easily find hidden connections across different domains.
Define Clear Automation Goals
When you begin rolling out automated actions, start with small, well-defined use cases rather than trying to automate your entire operational workflow overnight.
Look for high-volume, simple, repetitive issues that frequently take up your on-call engineers’ time, such as clearing temporary caches or restarting a specific non-critical service, and automate those low-risk tasks first to build confidence across your team.
Train Teams for AI-Driven Operations
Moving to an AIOps model requires a shift in team culture and skills, not just upgrading your software tools. Engineers need to learn how to manage machine learning alerts, configure automated playbooks, and trust algorithmic insights.
Investing in high-quality training ensures your team can easily shift from manual troubleshooting to managing intelligent, automated cloud systems.
Continuously Improve Monitoring Pipelines
An enterprise technology environment is constantly evolving as developers push new features and cloud architectures scale out. Your AIOps models need to evolve right along with them.
Set up a regular schedule to review your automation rules, update data definitions, and retrain your machine learning models, ensuring your platform stays highly accurate and well-tuned over time.
Essential Tools Used in Modern AIOps Environments
Monitoring and Observability Platforms
Modern observability tools form the core data foundation for any successful AIOps architecture. Platforms like Dynatrace, Datadog, and New Relic deploy smart, lightweight agents across your entire infrastructure stack.
These agents automatically discover applications and continuously capture deep performance traces, system metrics, and log data, feeding clean data streams directly into your AI analytics engine.
Incident Management Systems
To handle incidents intelligently, an AIOps platform needs to connect directly with enterprise workflow tools like PagerDuty and ServiceNow.
When the machine learning engine discovers a system anomaly, it passes the correlated data straight into these incident systems, which automatically builds a detailed ticket, assigns it to the right team, and updates the status in real time as automated playbooks run.
Automation Tools
The actual hands-on repair work within an AIOps pipeline is handled by flexible automation and configuration frameworks like Ansible, Terraform, and custom execution engines.
Once the AI platform pinpoints the true root cause of a system drop, it triggers these orchestration tools to safely run configuration playbooks, redeploy healthy cloud infrastructure, or apply security patches instantly.
Cloud Monitoring Technologies
As companies rely more and more on major cloud hyperscalers, native cloud-tracking tools like AWS CloudWatch, Azure Monitor, and Google Cloud Monitoring have become absolutely vital.
These native tools track the live performance of cloud-managed services, serverless compute functions, and virtual networks, passing this valuable cloud data straight to the centralized AIOps platform.
AI-Based Analytics Platforms
Dedicated AI analytics platforms like Splunk IT Service Intelligence (ITSI) and BigPanda act as the centralized brain for your entire operations infrastructure.
These platforms ingest raw data from all of your different monitoring tools, apply advanced machine learning algorithms to filter out background noise, group related events together, and give engineers a clear, single view of the health of your business services.
Career Opportunities in AIOps
Skills Required for AIOps Engineers
To thrive as a modern AIOps engineer, you need a balanced mix of traditional systems administration experience and modern data science skills.
Engineers must understand core infrastructure concepts like Linux operating systems, networking protocols, and containerization.
Additionally, you need a solid grasp of data analytics, including writing Python scripts for data manipulation, understanding how machine learning algorithms identify patterns, and mastering big data query languages.
Career Path for IT Professionals
For traditional IT professionals like system administrators, network engineers, and helpdesk managers, learning AIOps opens up an incredible path toward high-paying, future-proof roles.
As manual operations work disappears, engineers who understand how to build and manage automated, AI-driven monitoring platforms are in high demand, moving into lucrative roles like Site Reliability Engineer (SRE), Cloud Operations Architect, or Enterprise Systems Optimizer.
Certifications and Learning Resources
Validating your technical expertise through recognized industry certifications is an excellent way to stand out in this competitive job market.
Engineers should consider pursuing specialized certifications from major cloud providers and observability vendors, such as the AWS Certified DevOps Engineer, the Splunk Core Certified Advanced Power User, or dedicated enterprise observability certifications.
Learning AIOps with AIOpsSchool.com
Mastering the complex world of automated infrastructure operations requires a structured, hands-on learning approach.
By taking courses with industry-focused training providers like AIOpsSchool.com, engineers gain direct, practical experience working with real-world enterprise architectures, advanced machine learning tools, and modern automated playbooks.
These comprehensive learning programs bridge the gap between legacy IT concepts and modern, AI-driven development strategies, giving you the exact technical skills needed to lead large-scale enterprise operations transformations.
Future of IT Operations with AIOps
AI-Driven Infrastructure Management
The future of enterprise IT operations is moving rapidly toward total automated management, where human engineers will no longer need to manually configure infrastructure components.
Advanced AI systems will continuously analyze live business performance requirements, automatically designing, scaling, and optimizing distributed cloud systems across multiple global regions to match actual user demand in real time.
Self-Healing Systems
We are quickly moving toward an era of true self-healing technology infrastructure.
When software bugs, database locks, or hardware failures inevitably occur, the underlying operations platform will immediately isolate the broken components, analyze the problem using machine learning models, and apply precise, permanent fixes automatically, keeping systems running smoothly without ever needing human intervention.
Predictive Operations
As predictive analytics algorithms become more advanced, the concept of unexpected application downtime will become a thing of the past.
Future operations platforms will identify potential system bugs, capacity bottlenecks, and security vulnerabilities days in advance, scheduling and executing automated optimizations entirely behind the scenes during the quietest hours of the night.
Intelligent Cloud Monitoring
As multi-cloud and edge computing networks grow larger and more complex, AI platforms will become the primary way businesses manage these highly distributed environments.
These intelligent platforms will continuously track performance metrics and cloud pricing across different providers, dynamically moving application workloads from one cloud to another in real time to guarantee the absolute best performance at the lowest possible cost.
Autonomous Incident Resolution
In the future, the entire incident management lifecycle will be completely autonomous.
From the absolute first second an operational anomaly is detected to the final root-cause analysis and system repair, the software platform will handle the entire process independently, generating automated update summaries for human managers and completely eliminating the need for emergency late-night bridge calls.
FAQ Section
- What is the difference between monitoring and observability?
Monitoring focuses on tracking specific pre-defined metrics to see if a system component is working or broken based on static rules. Observability goes much deeper by analyzing all system outputs—like logs, metrics, and distributed traces—to help engineers understand exactly why a complex system is behaving a certain way under real-world conditions.
2. Does implementing AIOps require changing existing IT systems?
No, AIOps platforms do not require you to rip and replace your current technology stack. They are designed to connect smoothly with your existing ecosystem, ingesting data directly from the infrastructure tools, cloud providers, and helpdesk systems you already use.
3. How does machine learning reduce alert noise in enterprise systems?
Machine learning algorithms analyze huge volumes of alerts over time, identifying patterns and grouping related warnings into a single comprehensive incident file. The platform automatically filters out normal system noise and duplicate alerts, letting teams focus on the true root cause of a problem.
4. Can small businesses benefit from adopting AIOps platforms?
Yes, small and mid-sized businesses can absolutely benefit from AIOps. Many modern tools offer flexible, cloud-based models that allow growing companies to deploy intelligent monitoring and automation capabilities without needing a massive budget or a giant team of data scientists.
5. What is the role of a human engineer in an AIOps environment?
In an AIOps setup, human engineers shift away from exhausting, reactive firefighting and manual log analysis. Instead, they act as strategic architects who design resilient system structures, set automation boundaries, train machine learning models, and focus on driving technology innovation for the business.
6. How long does it typically take to see results from an AIOps rollout?
Many organizations start seeing valuable results, like reduced alert noise and better system visibility, within just a few weeks of connecting their core data streams. As the platform’s machine learning models ingest more historical data over months, its predictive alerts and automated fixes become increasingly accurate and powerful.
Conclusion
The transition from legacy, manual IT management to data-driven, intelligent infrastructure automation marks a massive turning point for modern enterprise operations. Relying on isolated data silos, rigid static thresholds, and stressful, reactive firefighting is no longer sustainable in our fast-paced, cloud-scale digital world. Traditional IT operational methods create major bottlenecks that slow down incident response, exhaust engineering teams with alert fatigue, and expose businesses to costly application outages. By adopting an AIOps model, organizations gain deep, end-to-end visibility across their entire infrastructure, allowing them to transform data into clear, actionable insights. Using the power of big data analytics, machine learning algorithms, and automated workflows, companies can easily catch system anomalies early, pinpoint root causes in seconds, and resolve complex issues before they ever impact the customer experience. This intelligent shift boosts team productivity, lowers operational costs, and ensures maximum application reliability. As hybrid cloud networks and distributed applications continue to grow more complex, mastering automated operations has become an absolute necessity for modern technology organizations and IT professionals alike.