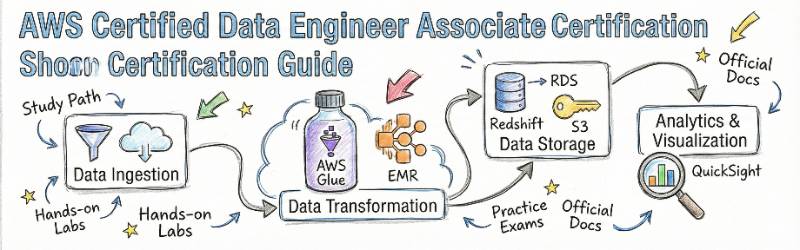
Introduction
Most companies today do not struggle because they “lack data.” They struggle because their data is late, messy, hard to trust, or too expensive to run at scale. A modern data engineer is expected to fix that end-to-end: ingest data, store it properly, transform it safely, apply governance, keep it secure, and make it useful for analytics teams and business users. AWS Certified Data Engineer – Associate is built for this real job. It validates your ability to design and operate data pipelines and analytics solutions on AWS, with strong focus on ingestion, storage, processing, orchestration, data quality, governance, security, and monitoring.
Who this guide is for
This master guide is written for:
- Working engineers who want a clear plan to prepare and pass
- Managers who want to understand what skills this certification proves
- Software engineers moving into data engineering or cloud data roles
- Data engineers who want stronger AWS platform depth
What this certification covers
AWS Certified Data Engineer – Associate focuses on the practical skills needed to build reliable, scalable data platforms on AWS. The training outline highlights the same major areas you see in real projects:
- Data ingestion and streaming (batch + real-time)
- Data storage and lakehouse design
- ETL/ELT and processing workflows
- Data warehousing and analytics
- Governance, security, and data quality
- Monitoring, performance, and cost optimization
(Reference: certification page agenda and overview)
In short: it is not only about services. It is about decisions, trade-offs, and operating pipelines like production systems.
Why AWS Data Engineer skills matter (for engineers and managers)
For engineers
- You learn how to build pipelines that do not break every week.
- You learn how to design storage so queries run faster and cost less.
- You learn how to add quality checks so teams trust dashboards again.
- You learn how to secure data properly without blocking productivity.
For managers
- You get a common language to review data platform architecture.
- You can assess whether the team is building “quick demos” or “real systems.”
- You can reduce delivery risk by pushing good governance early.
- You can control cloud spend by making cost-aware design a habit.
Certification overview (based on the provided reference page)
The reference page frames this certification as validating your ability to:
- Design and implement ingestion, transformation, and orchestration workflows
- Build data lakes, warehouses, and analytics solutions using AWS services
- Implement quality, lineage-style thinking, and governance controls
- Secure data at rest and in transit with encryption and access controls
- Monitor pipelines, optimize performance, and manage cost
(Reference: course overview and “It validates an examinee’s ability to…” section)
Table: AWS certifications map and recommended order
You asked for a table listing “every certification” with a link. Your rule allows only the provided official certification links, so the Link column is only filled for AWS Certified Data Engineer – Associate. Others are marked as Not provided (rule).
| Certification | Track | Level | Who it’s for | Prerequisites | Skills covered | Recommended order |
|---|---|---|---|---|---|---|
| AWS Certified Cloud Practitioner | Cloud Fundamentals | Foundational | Beginners, managers, non-technical | None | AWS basics, billing, cloud concepts | 1 |
| AWS Certified Solutions Architect – Associate | Architecture | Associate | Cloud engineers, architects | Basic AWS exposure | Design patterns, reliability, cost-aware design | 2 |
| AWS Certified Developer – Associate | Development | Associate | App developers | Coding + AWS basics | AWS app services, deployment patterns | 2 |
| AWS Certified CloudOps Engineer – Associate | Operations | Associate | Ops, SRE, CloudOps | AWS basics + operations mindset | Monitoring, ops workflows, reliability | 2 |
| AWS Certified Data Engineer – Associate | Data Engineering | Associate | Data engineers, analytics engineers, cloud data roles | ETL/ELT basics, AWS data familiarity helps | Ingestion, lakehouse, ETL/processing, warehousing, governance, monitoring, cost | 2–3 |
| AWS Certified DevOps Engineer – Professional | DevOps | Professional | Senior DevOps/Platform | Strong AWS + delivery automation | CI/CD, automation, governance at scale | 4 |
| AWS Certified Solutions Architect – Professional | Architecture | Professional | Senior architects | Strong architecture experience | Complex systems, multi-account patterns | 4 |
| AWS Certified Security – Specialty | Security | Specialty | Security and platform security | AWS security experience | IAM, encryption, governance, logging | 4 |
| AWS Certified Data Analytics – Specialty | Analytics | Specialty | Analytics specialists | Strong analytics exposure | Warehousing, analytics architecture | 4 |
| AWS Certified Machine Learning (Associate/Specialty) | AI/ML | Associate/Specialty | ML engineers | ML basics + AWS | ML systems, MLOps patterns | 3–4 |
About AWS Certified Data Engineer – Associate
What it is
AWS Certified Data Engineer – Associate validates the skills required to design, build, and operate data pipelines and analytics solutions on AWS. It focuses on data ingestion, storage, processing, orchestration, data quality, and governance across modern AWS data platforms.
(Reference: “About” section + certification focus section on the provided page)
Who should take it
You should consider this certification if you do (or want to do) work like:
- Building batch or streaming ingestion pipelines
- Managing a data lake / lakehouse or analytics platform
- Running ETL/ELT workflows and owning reliability
- Supporting analytics teams with trusted curated datasets
- Handling governance requirements like access control and audit readiness
- Controlling performance and cost for large data workloads
(Reference: intended roles and training audience on the page)
Skills you’ll gain
- Batch ingestion patterns and safe movement of data into a lake
- Streaming ingestion patterns and handling high-volume event data
- Lakehouse storage design (partitioning, compression, formats)
- ETL/ELT patterns for data transformation and preparation
- Orchestration patterns (retries, error handling, reliable execution)
- Warehouse design and analytics delivery approach
- Security and governance practices (permissions, encryption, policies)
- Data quality checks and reliability thinking
- Monitoring, performance tuning, and cost optimization
(Reference: agenda outline and domain bullet list on the page)
Real-world projects you should be able to do after it
These are realistic “work-style” projects that mirror what teams actually build.
- Batch ingestion pipeline: replicate data from a database into a lake, with validation and backfill support
- Streaming ingestion pipeline: ingest events continuously and store them in a query-ready form
- Lakehouse foundation: set up a curated storage layout that supports fast analytics and clean governance
- ETL/ELT pipeline with orchestration: transform raw data into curated layers with retries and failure handling
- Analytics delivery: query a data lake or warehouse, tune performance, and publish datasets for reporting
- Governance setup: implement permissions, access policies, and encryption for sensitive datasets
- Monitoring and reliability: build dashboards/alerts for pipeline health, failures, and cost spikes
(Reference: lab/project focus areas and monitoring/governance sections)
What you will actually learn
Data ingestion and streaming
You will learn how to design both batch and real-time pipelines. That includes:
- How to move data reliably from sources to storage
- How to handle schema changes without breaking downstream jobs
- How to validate data early so quality issues do not spread
This matters because ingestion is where most pipeline failures start. If ingestion is weak, everything downstream becomes firefighting.
Data storage and lakehouse architecture
You will learn how to design a lakehouse approach with:
- Proper cataloging so data is discoverable
- Partitioning so queries do not scan everything
- Compression and file formats so cost and speed remain under control
This matters because storage design is the “hidden lever” behind both performance and monthly cloud bills.
ETL/ELT and data processing
You will learn to:
- Transform data safely and repeatedly
- Build jobs that can retry without corrupting outputs
- Orchestrate workflows end-to-end with clear dependencies
This matters because real pipelines fail. A mature pipeline design expects failures and recovers cleanly.
Data warehousing and analytics
You will learn how to:
- Design warehouse tables and distribution patterns for performance
- Query data lakes efficiently
- Provide reliable datasets for dashboards and business reporting
This matters because “analytics is the product.” If users cannot get answers quickly and reliably, the platform fails even if pipelines run.
Governance, security, and data quality
You will learn practical governance controls like:
- Access control policies that match teams and roles
- Encryption strategies
- Data masking style thinking for sensitive fields
- Quality checks, auditability, and lineage-style discipline
This matters because governance is not optional anymore. Without it, teams either block access or create risky shortcuts.
Monitoring, reliability, performance, and cost optimization
You will learn to:
- Monitor pipelines and detect failures early
- Tune performance when query speed drops
- Reduce cost by fixing design issues (not only “adding more compute”)
This matters because the best data engineers do not only build pipelines—they operate them.
(Reference for all sections: agenda list and “Monitoring, Performance & Cost Optimization” and related bullets on the provided page)
Preparation plan
7–14 days plan (fast-track for experienced engineers)
This plan is only realistic if you already build pipelines and know AWS basics.
- Days 1–2: Map the exam topics to your work
- List your strong areas: ingestion, storage, ETL, governance, monitoring
- Identify gaps: maybe lakehouse design, cataloging, or cost patterns
- Days 3–6: Build one end-to-end pipeline
- Source → ingestion → storage → transform → analytics
- Keep notes: why you chose each design decision
- Days 7–10: Add production behaviors
- Retries, alerting, monitoring
- Data quality checks
- Access control + encryption strategy
- Days 11–14: Practice and review
- Focus on scenario-style reasoning
- Fix weak topics by re-building small labs
30 days plan (best for most professionals)
- Week 1: Foundations + ingestion
- Learn ingestion patterns and validation
- Build a small batch and streaming example
- Week 2: Storage + lakehouse
- Practice partitioning and file format decisions
- Understand cataloging and discovery
- Week 3: ETL/ELT + orchestration
- Practice job reliability: idempotency, retries, backfill
- Add orchestration and operational controls
- Week 4: Governance + monitoring + optimization
- Build access policies
- Add encryption
- Add monitoring dashboards
- Review performance and cost habits
60 days plan (for beginners to AWS data platforms)
- Weeks 1–2: AWS + data foundations
- Focus on clear concepts, not speed
- Build small labs to gain confidence
- Weeks 3–6: Build one “portfolio project”
- A real end-to-end pipeline
- Add governance, monitoring, and cost awareness
- Weeks 7–8: Practice and refine
- Review mistakes
- Rebuild weak parts from scratch
- Keep a short revision notebook
Common mistakes (practical, and easy to fix)
- Building pipelines without re-run safety
If a job runs twice, does it create duplicates or wrong results? Reliable pipelines must be safe to re-run. - Ignoring file formats and partitions early
Many teams store data “however it arrives” and later pay huge query costs. Good design early saves months later. - No data quality checks
If you do not test data, dashboards become untrusted. Add simple checks early: null checks, ranges, row counts. - Over-permissioning access
Teams often give broad access “for speed.” Later, audits and incidents become painful. Use least privilege early. - No monitoring until stakeholders complain
By the time business users notice, damage is already done. You need pipeline health signals and alerts. - Treating cost as a finance problem
Cost is a design problem. Storage layout and query patterns decide most of the spend. - Optimizing too early in the wrong area
First make it correct and reliable. Then make it fast and cost-efficient. Otherwise you optimize failures.
Best next certification after this
Your “next certification” should match your job direction.
- If you want deeper data and analytics specialization
Choose a data analytics focused certification next. This helps when your role is heavy on warehousing, BI performance, and analytics architecture. - If you want broader cloud architecture leadership
Choose an architecture professional level certification next. This helps if you design platforms across teams and accounts. - If you want stronger security and governance ownership
Choose a security specialty certification next. This is very useful for data platforms because governance and compliance are always growing.
Choose your path (6 learning paths)
1) DevOps path
If you work in DevOps, you already know automation, reliability, and repeatable delivery. Data engineering becomes easier when you apply the same discipline:
- Version control for pipeline code and configs
- Repeatable deployments of pipelines and environments
- Monitoring and incident readiness for data services
This certification helps you bring DevOps-style maturity into data workloads.
2) DevSecOps path
If you care about compliance and risk reduction, this certification gives you a strong base:
- Access control thinking for datasets and teams
- Encryption and audit-readiness habits
- Governance-first design instead of last-minute patching
Data platforms often become compliance hotspots. DevSecOps thinking prevents future rework.
3) SRE path
For SRE, the key is operating data pipelines like production services:
- Define what “healthy” means for each pipeline
- Track failures, retries, and on-time delivery
- Build alerting and recovery playbooks
This certification supports the monitoring and reliability skills that data platforms demand.
4) AIOps/MLOps path
ML systems are data systems first. If the pipeline is weak, ML outcomes suffer:
- You need reliable ingestion and clean features
- You need monitoring for drift-like data changes
- You need governance for sensitive training data
This certification helps you build the strong data foundation that MLOps depends on.
5) DataOps path
DataOps is about making data delivery predictable:
- Automated tests for data quality
- Repeatable transformations and curated layers
- Clear SLAs for data availability
This certification aligns well because it focuses on end-to-end pipelines and operational maturity.
6) FinOps path
Data workloads can become a top cloud cost driver. FinOps needs engineers who can reduce waste:
- Reduce query scans with better partitions and formats
- Choose cost-efficient processing patterns
- Track and control pipeline cost growth
This certification helps you learn cost-aware habits in data engineering design.
Role → Recommended certifications (expanded mapping)
This mapping is designed for working professionals. It is not about “collecting badges.” It is about building job-ready capability in the right order.
| Role | Recommended certifications (sequence and why) |
|---|---|
| DevOps Engineer | Solutions Architect – Associate (architecture basics) → Data Engineer – Associate (data platform skills) → DevOps Engineer – Professional (delivery automation at scale) |
| SRE | CloudOps Engineer – Associate (ops discipline) → Data Engineer – Associate (operate pipelines reliably) → DevOps Engineer – Professional (advanced automation) |
| Platform Engineer | Solutions Architect – Associate (platform design) → Data Engineer – Associate (data platform foundation) → Security – Specialty (governance and platform controls) |
| Cloud Engineer | Solutions Architect – Associate (broad AWS design) → Data Engineer – Associate (data services depth) → Solutions Architect – Professional (enterprise architecture) |
| Security Engineer | Security – Specialty (core security depth) → Data Engineer – Associate (secure data platforms) → Networking – Specialty (advanced network security patterns) |
| Data Engineer | Data Engineer – Associate (core) → Data Analytics – Specialty (depth) → Solutions Architect – Professional (lead architecture decisions) |
| FinOps Practitioner | Cloud Practitioner (basics) → Data Engineer – Associate (cost drivers in data) → Solutions Architect – Associate (cost-aware cloud design habits) |
| Engineering Manager | Cloud Practitioner (shared language) → Data Engineer – Associate (review data platform decisions) → Solutions Architect – Professional (lead multi-team architecture) |
Next certifications to take (3 options)
Same track (stay data-focused)
Choose a data analytics specialty certification next if your daily work is analytics performance, warehousing, and BI enablement.
Cross-track (broaden impact)
Choose an architecture professional certification if you want to lead design across multiple systems, teams, and cloud accounts.
Leadership track (governance and platform ownership)
Choose a security specialty certification if you want to own governance, encryption standards, auditing readiness, and risk controls for data platforms.
Top institutions that help with Training cum Certifications (3–4 lines each)
DevOpsSchool
DevOpsSchool provides instructor-led training with guided labs and real-world scenarios aligned to the certification scope. The program emphasizes ingestion, lakehouse design, ETL/ELT workflows, governance, monitoring, and cost optimization—so learners can build reliable data platforms end-to-end. It is designed for working professionals who want practical confidence, not only theory.
Cotocus
Cotocus is useful for learners who prefer practical support while building job-aligned skills. It can help you structure your learning with hands-on implementation and clearer execution steps. The best results come when you build one complete pipeline project and keep improving it week by week.
ScmGalaxy
ScmGalaxy works well for learners who want guided progression from basics to applied practice. It can help you follow a structured plan and stay consistent during preparation. Pair the training with repeated labs so the concepts become natural under exam pressure.
BestDevOps
BestDevOps is often chosen by learners who want focused preparation and practice-based learning. It can be helpful if you learn better with guided tasks and real-world style examples. A strong approach is to treat preparation like a delivery project with milestones.
DevSecOpsSchool
DevSecOpsSchool is valuable if your role includes compliance, governance, or sensitive data handling. It helps you build security-first habits that map well to data platform needs like access control, encryption, and auditing. This becomes very useful when your pipelines handle customer or regulated data.
SRESchool
SRESchool supports an operations-first approach. It helps engineers learn reliability patterns like monitoring, alerting, incident response, and stable delivery. This is important because data pipelines are production systems and must meet availability and freshness expectations.
AIOpsSchool
AIOpsSchool is useful if your team wants smarter operations and faster troubleshooting at scale. It helps you think about monitoring signals, noise reduction, and automated response. This aligns with data engineering when you run many pipelines and need operational efficiency.
DataOpsSchool
DataOpsSchool aligns closely with data engineering maturity: tests, automation, repeatability, and trust in outputs. It helps you build quality gates and strong delivery discipline. This is especially helpful when multiple teams depend on the same datasets and SLAs matter.
FinOpsSchool
FinOpsSchool helps engineers connect technical choices to cloud cost outcomes. Data platforms can become expensive due to storage scans and processing patterns. This training mindset helps you build cost-aware pipelines and keep spending stable as data grows.
FAQs on AWS Certified Data Engineer – Associate
1) How difficult is AWS Certified Data Engineer – Associate?
It is moderately challenging. It is not only memory-based. It tests how you think in real scenarios: ingestion choices, storage layout, transformation reliability, governance, and monitoring. If you build pipelines today, it feels practical. If you are new, you must practice hands-on to make it easier.
2) How much time do I need to prepare?
Most working professionals do well with a 30–60 day plan. If you already work on AWS data pipelines, a 7–14 day fast revision plan can work. If you are new to AWS data services, take 60 days and focus on building one full project.
3) What prerequisites should I have before starting?
Helpful prerequisites include ETL/ELT basics, data modeling awareness, and a basic understanding of AWS storage and security concepts. Familiarity with monitoring and pipeline reliability helps a lot. The reference page also lists prerequisites like hands-on experience with data pipelines and basic security/governance understanding.
4) Do I need strong programming skills?
You do not need advanced software engineering, but you must be comfortable with basic programming concepts used in pipeline logic and orchestration. You should also be comfortable with data transformations and basic SQL-style thinking.
5) Should I do Solutions Architect – Associate before this?
If you are completely new to AWS, doing an architecture associate certification first can help. It builds broader cloud understanding. If your job is already data engineering and you know AWS basics, you can start directly with Data Engineer – Associate.
6) What career outcomes can this certification support?
It can support roles like Data Engineer, Analytics Engineer, Cloud Data Specialist, Platform Engineer (data platforms), and even Engineering Manager oversight for data platforms. The biggest benefit is that you can explain and defend your design decisions clearly.
7) Is this certification useful for managers?
Yes, if you manage data teams or data-heavy products. It helps you review designs with confidence, ask better questions about governance and reliability, and reduce risk in delivery timelines.
8) What is the best way to study without feeling overwhelmed?
Do not try to learn everything in isolation. Build one end-to-end pipeline project and map every topic to that project. Each time you learn a concept, apply it. This keeps learning simple and makes recall easier in the exam.
9) What is the smartest certification sequence for a pure Data Engineer?
A practical sequence is: Data Engineer – Associate → data-focused specialty certification → architecture professional certification. This gives both depth and leadership-level design skill.
10) What common mistake causes most failures?
The biggest mistake is weak hands-on practice. Many learners read concepts but do not build pipelines. Scenario questions become hard if you have never designed retries, monitoring, governance, or cost controls.
11) Can I prepare in 30 days with a full-time job?
Yes, if you stay consistent. Study in small daily blocks, and build a simple pipeline in week 1–2. Then expand it with governance and monitoring in week 3–4. Consistency is more important than long weekend sessions.
12) What is the best next certification after passing?
Pick based on your goal:
- Data depth: analytics-focused specialty
- Broad design: architecture professional
- Governance leadership: security specialty
Choose the next one that matches your job direction, not only popularity.
FAQs on AWS Certified Data Engineer – Associate
1) How challenging is the AWS Certified Data Engineer – Associate exam?
The AWS Certified Data Engineer – Associate exam is considered moderately challenging. It is designed to test your practical skills in building and managing data pipelines, as well as your ability to use AWS services to store, process, and analyze data. It’s less about memorization and more about applying concepts in real-world scenarios, so having hands-on experience with AWS data services will make the exam easier.
2) How much preparation time do I need for this certification?
The preparation time depends on your experience. For those who are already familiar with AWS data services, 30–45 days should be sufficient with regular practice. If you are new to AWS, you may need 60 days to fully understand the concepts, gain hands-on experience, and feel ready for the exam.
3) What skills or knowledge should I have before starting this certification?
To get the most out of your preparation, you should be comfortable with the following:
- Basic cloud concepts (especially AWS services such as EC2, S3, IAM)
- Data concepts like ETL, databases, and data structures
- Basic SQL skills for data querying and manipulation
- Familiarity with services like AWS Lambda, Redshift, Glue, Kinesis, S3, and Data Pipeline is helpful.
These prerequisites will set you up for success, but you don’t need to be an expert before you begin.
4) Do I need to be proficient in coding to pass this exam?
No, you don’t need advanced coding skills. However, you should be familiar with basic scripting (e.g., Python or SQL) since you will work with data processing tools like AWS Lambda and Glue. Having the ability to write and understand simple code is important for building reliable data pipelines, but you won’t be asked to write complex algorithms or programs for the exam.
5) Should I take the Solutions Architect certification first?
While it’s not mandatory, taking the AWS Certified Solutions Architect – Associate first can help you understand the AWS ecosystem better. It provides a foundational knowledge of AWS services, which is helpful when you dive into data engineering. However, if you’re already familiar with cloud services and AWS, you can go straight into the Data Engineer – Associate certification.
6) What is the best sequence of certifications to follow for a career in data engineering?
For a strong career in data engineering, consider this progression:
- AWS Certified Cloud Practitioner (optional for cloud basics)
- AWS Certified Data Engineer – Associate (core data engineering skills)
- AWS Certified Data Analytics – Specialty (for deep analytics expertise)
- AWS Certified Solutions Architect – Professional (for architectural depth)
- AWS Certified Machine Learning – Specialty (if you’re interested in integrating ML into data pipelines)
This sequence will help you build a solid foundation, enhance your specialization, and ultimately lead to more senior roles in data and cloud architecture.
7) How valuable is this certification for career growth?
The AWS Certified Data Engineer – Associate is highly valuable if you’re aiming for a role in data engineering, cloud data engineering, or platform engineering. It validates your ability to work with AWS tools to design, implement, and manage scalable data pipelines, making you a highly sought-after candidate in the growing field of cloud-based data services.
8) What types of job roles will this certification help me pursue?
This certification will help you secure roles like:
- Data Engineer: Building and maintaining data pipelines and storage solutions.
- Cloud Data Engineer: Working specifically with AWS data services to design scalable platforms.
- Analytics Engineer: Building data models and pipelines to support business intelligence and analytics teams.
- Platform Engineer (data): Designing and managing cloud-based platforms that handle data ingestion, processing, and analytics.
- Cloud Architect: Designing cloud infrastructure with a focus on data storage and processing.
It also opens opportunities for more advanced roles such as Lead Data Engineer or Cloud Data Architect once you gain more experience.
Conclusion
AWS Certified Data Engineer – Associate is a strong certification if you want to build real data pipelines that teams can trust. The biggest value is not the badge. The value is the mindset you gain: design ingestion carefully, store data in a query-friendly way, transform it reliably, apply governance early, secure sensitive fields, and monitor everything like a production system. If you prepare by building one complete end-to-end pipeline and then improving it with retries, quality checks, access controls, and cost tuning, you will be ready for both the exam and real project work. After passing, choose your next step based on your path—data depth, cross-track architecture growth, or leadership through security and governance.
Very useful AWS Data Engineer guide! Clear and structured explanation that makes certification prep simple and focused. Great for building strong cloud data skills!