Introduction
In the modern world of software, speed is important, but reliability is everything. If your app is fast but crashes when ten thousand users join, you don’t have a product; you have a problem.I have spent two decades in the trenches of IT operations and software development. I’ve seen the “old ways” of manual patching and the “new ways” of automated cloud clusters. The most important lesson I have learned is that you cannot “hope” for a stable system. You have to engineer it. Site Reliability Engineering (SRE) is the bridge between building code and keeping it alive. This guide explains the Site Reliability Engineering Certified Professional (SRECP) program—the definitive path for anyone who wants to master the art of building systems that simply don’t break.
Why SRE is the Secret to Modern Business Success
The traditional wall between “Developers” and “Operations” has caused more outages than any bug ever could. Developers want to push features fast. Operations want to keep things stable by changing nothing. SRE fixes this conflict by making operations a software problem.
By becoming an SRECP, you stop being a “firefighter” and start being an architect of stability. You use data, automation, and engineering principles to ensure that your services are always available, scalable, and secure. This is exactly how giants like Google and Amazon handle billions of requests without blinking.
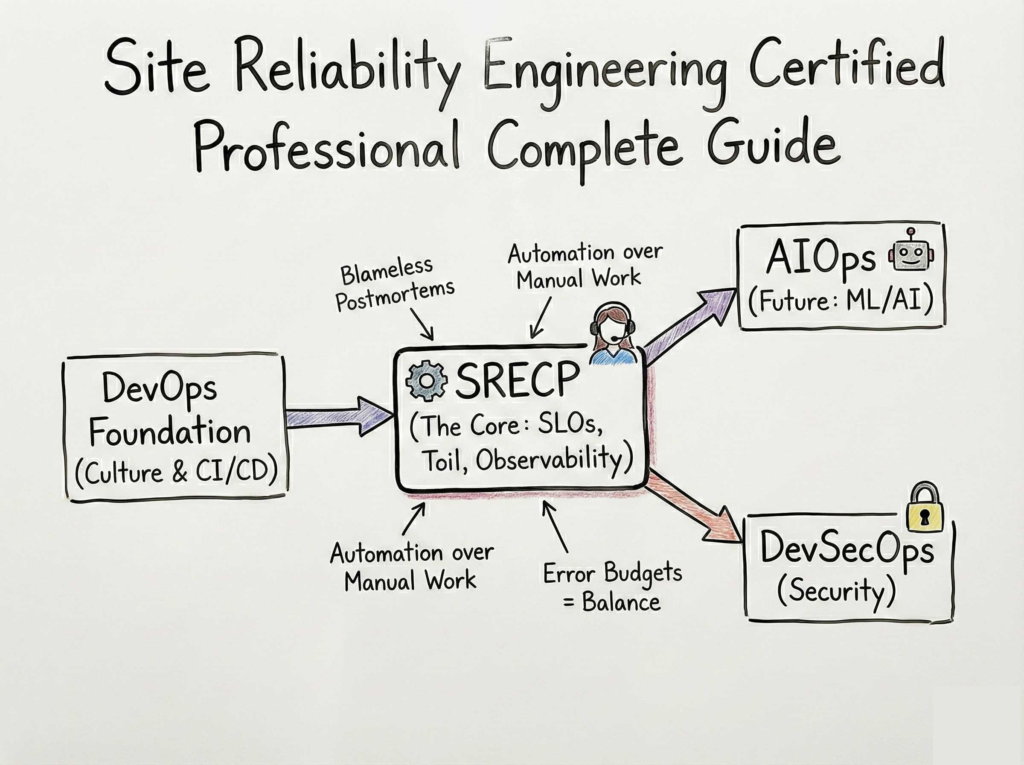
Site Reliability Engineering Certified Professional (SRECP)
What it is
The SRECP is a master-level certification that validates your ability to scale critical services reliably and economically. It focuses on the technical methods needed to ensure that applications work efficiently in complex, high-traffic production environments. It is more than just a certificate; it is a validation of your ability to handle “un-killable” systems.
Who should take it
- Software Engineers who want to understand the production lifecycle.
- DevOps Engineers looking to specialize in high-availability and observability.
- Platform Engineers building internal tools for developer teams.
- Engineering Managers who need to balance feature speed with system safety.
- System Administrators transitioning into modern, automation-first roles.
Skills you’ll gain
- Advanced Observability: Master the “Four Golden Signals” (Latency, Traffic, Errors, and Saturation) to see exactly how your system feels.
- Error Budgeting: Learn the math of how much downtime your business can afford to take while still innovating.
- Toil Reduction: Identify manual, repetitive tasks and write the code necessary to delete them from your daily routine.
- Incident Response: Learn to lead a team during a major outage with a calm, structured, and blameless approach.
- Chaos Engineering: Proactively break your own systems in a controlled way to find weaknesses before your users do.
Real-world projects you should be able to do
- Design a Global SLO Dashboard: Create a live view of system health that stakeholders actually care about.
- Automate Incident Healing: Write scripts that automatically fix common server errors without a human ever waking up at 3 AM.
- Blameless Postmortem Reports: Write a report after a failure that finds the “why” without pointing fingers at a person.
- Capacity Planning Models: Use data to predict when you need more servers months before you actually run out of space.
Preparation plan
- 7–14 Days (The Expert Sprint): Focus on core SRE concepts like SLIs, SLOs, and Error Budgets. Read through real-world case studies of outages and learn how they were solved.
- 30 Days (The Professional Path): Spend two weeks on theory and two weeks in hands-on labs. You must get comfortable with tools like Prometheus and Grafana.
- 60 Days (The Deep Dive): Ideal for those shifting from non-coding roles. Spend the first 30 days mastering Linux and basic Python before diving into the SRE automation modules.
Common mistakes
- Aiming for 100% Reliability: 100% is the wrong target. It is too expensive and slows you down too much. SRE is about finding the right level of reliability.
- Buying Tools, Not Culture: A shiny dashboard won’t save a team that blames each other for mistakes. Blameless culture is the “engine” of SRE.
- Ignoring the “S” in SRE: Many people forget the “Site” part. You must understand the networking and infrastructure that your software sits on.
Best next certification after this
Once you have mastered SRECP, the AIOps Certified Professional (AIOCP) is the best follow-up to learn how Machine Learning can predict failures before they happen.
Comprehensive Certification List
| Track | Level | Who it’s for | Prerequisites | Skills Covered | Order |
| SRE | Professional | Engineers, Managers | DevOps Knowledge | SLIs/SLOs, Toil, Observability | 1 |
| DevOps | Professional | Software/Ops Eng | IT Basics | CI/CD, Git, Automation | 1 |
| DevSecOps | Professional | Security/SRE | DevOps Basics | Security Automation, Vault | 2 |
| AIOps | Advanced | SREs, Data Eng | SRE Knowledge | ML for Ops, Anomaly Detection | 3 |
| DataOps | Professional | Data Engineers | SQL Basics | Data Pipelines, Data Quality | 2 |
| FinOps | Professional | Cloud/Finance | Cloud Basics | Cost Optimization, Cloud Bills | 2 |
Choose Your Path: 6 Learning Journeys
Every engineer’s path is unique. Choose the journey that aligns with what you want to build:
1. The DevOps Path
Focuses on Speed and Culture. This is the foundation for everyone. You learn how to move code from a developer’s laptop to production as fast as possible without human intervention.
2. The DevSecOps Path
Focuses on Security. If you enjoy finding holes in systems and building “shields” through code, this path integrates security into the automated pipeline.
3. The SRE Path
Focuses on Stability. You are the “guardian” of the production environment. You ensure the systems are scalable, reliable, and always available for the user.
4. The AIOps/MLOps Path
Focuses on Intelligence. You use AI and Machine Learning to manage the massive scale of modern data. You build systems that learn from past mistakes and fix themselves.
5. The DataOps Path
Focuses on Data Flow. In the age of Big Data, getting information from point A to point B correctly and quickly is a massive engineering challenge.
6. The FinOps Path
Focuses on Efficiency. Cloud costs can get out of control quickly. This path teaches you how to keep the systems fast while keeping the cloud bill as low as possible.
Role → Recommended Certifications
| If your role is… | You should take… |
| DevOps Engineer | DevOps Certified Professional (DCP) |
| SRE | SRE Certified Professional (SRECP) |
| Platform Engineer | SRECP + Kubernetes Specialist |
| Cloud Engineer | SRECP + Cloud Specific (AWS/Azure) |
| Security Engineer | DevSecOps Certified Professional (DSOCP) |
| Data Engineer | DataOps Certified Professional (DOCP) |
| FinOps Practitioner | FinOps Certified Professional |
| Engineering Manager | SRECP + DevOps Manager Certification |
Next Certifications to Take
Once you have your SRECP, you should not stop. The field moves fast, and you must stay ahead. Here are your three best directions:
- Same Track (Deep Dive): Look into Chaos Engineering or Advanced Observability. Mastering the deep “internals” of your platform is key to becoming a Principal SRE.
- Cross-Track (Broaden): Take the DevSecOps Certified Professional (DSOCP). Reliability is useless if your system is hacked. Adding security to your SRE skills makes you a rare and valuable asset.
- Leadership (Growth): If you want to move into Director or VP roles, the Certified DevOps Manager (CDM) is essential. It teaches you how to change company culture, which is often harder than changing code.
Top Institutions for SRECP Support
Choosing where to learn is as important as what you learn. These institutions provide the best training and support for the SRECP program:
- DevOpsSchool: The global leader in SRE training. They provide a massive 72-hour curriculum that is entirely hands-on. Their trainers are real-world experts, and they offer lifetime technical support, which is invaluable when you encounter a real problem at work.
- Cotocus: Known for high-level consulting and training for large corporations. They specialize in helping teams move from traditional “Ops” to an “SRE” model at a massive scale.
- Scmgalaxy: A great resource for those who want deep technical insights and community support. They have an incredible library of tutorials that cover almost every SRE tool in existence.
- BestDevOps: They offer intensive bootcamps focused on making you “job-ready.” If you need to learn the skills quickly and start applying them tomorrow, this is a solid choice.
- devsecopsschool: The best place to learn the intersection of security and reliability. They ensure your SRE skills are built on a foundation of “security-first” thinking.
- sreschool: A niche institution that focuses 100% on SRE. They live and breathe reliability engineering and offer very targeted, deep-dive courses.
- aiopsschool: Prepares you for the future. As systems get more complex, we need AI to help us manage them. This school teaches you exactly how to do that.
- dataopsschool: Focuses on the reliability of data. If your company depends on real-time data for decisions, this institution will teach you how to keep those pipelines stable.
- finopsschool: Teaches you how to manage the financial side of the cloud. It is the perfect place for an SRE to learn how to save their company millions in cloud costs.
FAQs (General)
- How hard is the SRECP exam?
It is a professional-level exam. If you understand the core principles and have done the hands-on labs, you will pass. It tests your “thinking” as much as your “doing.” - How much time do I need to study?
Most people find that 30 to 45 days is the “sweet spot” to learn the material and practice the labs. - What are the prerequisites?
There are no strict mandates, but it is easier if you have 1–2 years of experience in IT or a basic understanding of DevOps. - In what order should I take these?
Start with DevOps, then SRECP, then AIOps. This builds a perfect ladder of skills. - Is this certification valued globally?
Yes. SRE is one of the highest-paid and most respected roles in tech from Silicon Valley to Bangalore. - Will this help me get a higher salary?
SREs typically earn 20–30% more than traditional system administrators or standard software developers. - Is the exam online or offline?
Most providers offer online proctored exams so you can take them from the comfort of your home. - Does the certification expire?
It is usually valid for 2–3 years. This ensures that you stay up to date with the latest technologies. - Can a manager take this course?
Yes. Managers need to understand SRE so they can set fair targets for their teams and reduce engineer burnout. - Do I need to be a coding expert?
You don’t need to build the next Facebook, but you should be comfortable with basic scripting (like Python or Go) to automate tasks. - What is a passing score?
Typically, a passing score is around 70%. - Are labs included in the training?
Yes, institutions like DevOpsSchool provide dedicated lab environments where you can break and fix things safely.
FAQs on SRECP
- What is the core focus of SRECP?
It is about engineering reliability into the system using automation and observability, rather than just waiting for things to break. - Does SRECP cover Kubernetes?
Yes. Kubernetes is the standard for modern scaling, and mastering it is a core part of the SRECP journey. - What is the difference between SRE and DevOps?
Think of DevOps as a philosophy and SRE as a specific way to implement that philosophy using engineering. - Will I learn about on-call rotations?
Yes. SRECP teaches you how to manage on-call duties in a way that is healthy and sustainable for the team. - What tools will I learn?
You will gain proficiency in concepts that apply to tools like Prometheus, Grafana, ELK Stack, and Ansible. - Can I take this if I am a pure developer?
Yes. It will make you a much stronger developer because you will understand how to write code that survives the “real world.” - What are SLIs and SLOs?
Service Level Indicators (what you measure) and Service Level Objectives (the target you want to hit). They are the “GPS” of SRE. - How does SRECP help in a career?
It moves you from being a “reactive” worker who waits for tickets to a “proactive” engineer who designs systems to be un-killable.
Conclusion
In the tech industry, tools come and go, but the need for stable, scalable systems is permanent. The Site Reliability Engineering Certified Professional (SRECP) is more than just a credential; it is a signal that you have mastered the engineering discipline required to keep modern businesses online. By following the roadmap laid out in this guide, you are doing more than just preparing for an exam—you are preparing for the next decade of your career. The shift from “fixing outages” to “engineering reliability” is what separates amateurs from true professionals.
The distinction made here between traditional SysAdmin work and modern SRE practices, specifically regarding ‘Toil Reduction’ and ‘Error Budgets,’ is spot on. Many organizations struggle with the cultural shift of accepting that 100% uptime isn’t always the goal, so highlighting that as a common mistake is very valuable for anyone looking to take the SRECP.