Introduction
On-device LLM runtimes are software systems that allow large language models to run directly on local hardware such as smartphones, laptops, edge devices, and embedded systems. Instead of relying on cloud APIs, these runtimes execute models locally, enabling faster responses, offline capability, and stronger privacy guarantees.
This category has become increasingly important as AI shifts toward personal, private, and real-time experiences. Running models on-device reduces dependency on network connectivity, improves latency, and helps organizations meet stricter data privacy requirements. It also unlocks new use cases in mobile assistants, offline copilots, and edge automation systems.
Common use cases include:
- Offline AI assistants on mobile and desktop devices
- Private document summarization without cloud exposure
- Edge-based industrial AI systems
- On-device copilots for productivity apps
- Real-time translation and speech assistance
- Embedded AI in IoT and consumer hardware
What to evaluate when choosing an on-device LLM runtime:
- Model compatibility and quantization support
- Hardware acceleration (CPU, GPU, NPU)
- Memory efficiency and token throughput
- Latency and real-time performance
- Offline capability and caching
- Privacy and local data handling
- Developer tooling and SDK support
- Cross-platform compatibility
- Model switching and optimization flexibility
- Energy efficiency on mobile and edge devices
Best for: mobile developers, edge AI engineers, embedded system builders, and privacy-focused applications in consumer and enterprise environments.
Not ideal for: teams requiring massive multi-model orchestration, heavy cloud-based reasoning workloads, or large-scale distributed inference systems.
What’s Changed in On-Device LLM Runtimes
- Quantized models (4-bit, 8-bit) have become standard for local inference
- NPUs (Neural Processing Units) are widely used for acceleration
- Hybrid inference (local + cloud fallback) is increasingly common
- Small language models are optimized specifically for edge performance
- Token streaming on-device enables real-time conversational UX
- Memory-aware model loading reduces device strain
- Cross-platform runtimes unify mobile, desktop, and embedded systems
- Privacy-first design is now a default expectation
- On-device RAG is emerging using local vector stores
- Energy efficiency optimization is a major design constraint
- Model switching at runtime improves flexibility
- Offline-first AI applications are becoming mainstream
Quick Buyer Checklist (Scan-Friendly)
- Does the runtime support quantized models efficiently?
- Can it leverage GPU/NPU acceleration on target devices?
- How well does it handle memory-constrained environments?
- Does it support offline inference fully?
- Can it integrate with local vector databases for RAG?
- What is the latency for real-time token generation?
- Is model switching supported dynamically?
- Does it offer debugging and observability tools?
- How portable is it across mobile, desktop, and embedded systems?
- What is the energy consumption profile on target hardware?
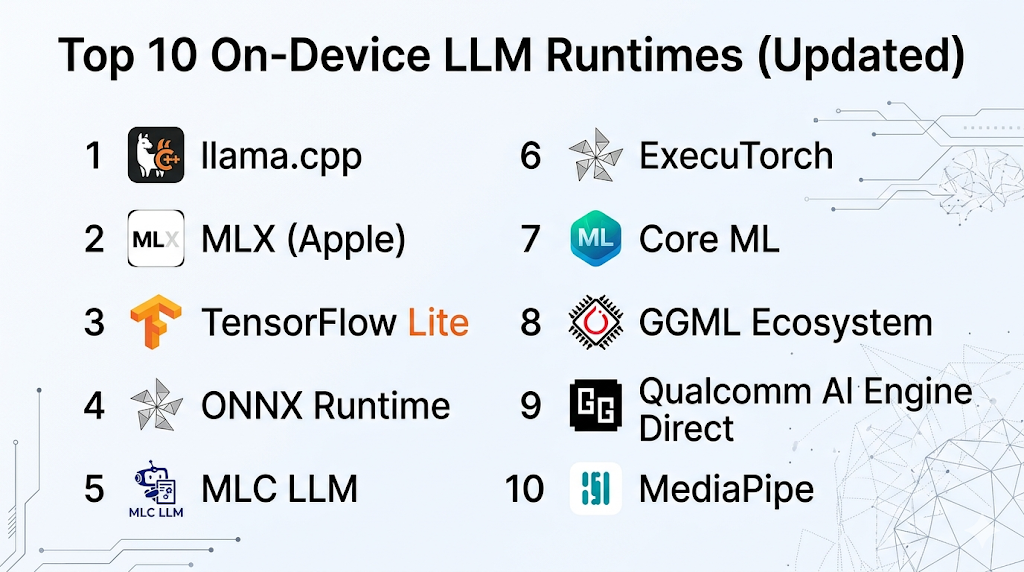
Top 10 On-Device LLM Runtimes
#1 — llama.cpp
One-line verdict: Best for lightweight, highly optimized local inference across CPU-based systems and edge devices.
Short description:
A widely used open-source runtime for running LLMs locally using optimized inference techniques. Popular among developers building offline AI systems.
Standout Capabilities
- Highly optimized CPU inference
- Supports quantized model formats
- Works across desktop and embedded systems
- Minimal dependencies for deployment
- Strong community-driven improvements
- Efficient memory management
- Broad model compatibility
AI-Specific Depth
- Model support: Open-source (GGUF and quantized models)
- RAG / knowledge integration: N/A (external implementations required)
- Evaluation: N/A
- Guardrails: N/A
- Observability: Basic logging only
Pros
- Extremely efficient on CPU-only devices
- Lightweight and portable
- Strong open-source ecosystem
Cons
- No built-in enterprise features
- Limited developer tooling
- Manual optimization required
Security & Compliance
Not publicly stated
Deployment & Platforms
- Linux, Windows, macOS
- Embedded systems
- CPU-first environments
Integrations & Ecosystem
- Model conversion tools
- Python bindings
- Community tooling
- Local inference stacks
Pricing Model
Open-source
Best-Fit Scenarios
- Offline AI applications
- Edge device deployment
- Lightweight assistant systems
#2 — MLX (Apple)
One-line verdict: Best for optimized LLM inference on Apple Silicon devices.
Short description:
A machine learning framework optimized for Apple hardware, enabling efficient local inference on macOS and iOS devices.
Standout Capabilities
- Deep Apple Silicon optimization
- Efficient memory usage
- Native GPU acceleration
- Seamless integration with Apple ecosystem
- Support for quantized models
- Fast local inference pipelines
- Developer-friendly APIs
AI-Specific Depth
- Model support: Open-source + converted models
- RAG / knowledge integration: N/A
- Evaluation: N/A
- Guardrails: N/A
- Observability: Limited
Pros
- Excellent performance on Apple devices
- Energy efficient
- Strong hardware integration
Cons
- Apple ecosystem lock-in
- Limited cross-platform support
- Smaller ecosystem
Security & Compliance
Not publicly stated
Deployment & Platforms
- macOS
- iOS
- Apple Silicon devices
Integrations & Ecosystem
- Swift and Python bindings
- Apple ML ecosystem
- Local model tools
Pricing Model
Open-source
Best-Fit Scenarios
- iOS/macOS AI apps
- On-device copilots
- Privacy-focused applications
#3 — TensorFlow Lite
One-line verdict: Best for production-grade mobile and embedded AI inference at scale.
Short description:
A lightweight ML runtime designed for mobile and edge devices with strong hardware acceleration support.
Standout Capabilities
- Mobile-first optimization
- Hardware acceleration support
- Wide device compatibility
- Model quantization tools
- Production-ready deployment
- Strong tooling ecosystem
- Edge AI support
AI-Specific Depth
- Model support: Open-source models
- RAG / knowledge integration: N/A
- Evaluation: N/A
- Guardrails: N/A
- Observability: Basic
Pros
- Mature and stable
- Broad hardware support
- Strong mobile integration
Cons
- Not LLM-native by default
- Requires optimization effort
- Limited LLM tooling
Security & Compliance
Not publicly stated
Deployment & Platforms
- Android
- Embedded devices
- Edge hardware
Integrations & Ecosystem
- TensorFlow ecosystem
- Mobile SDKs
- Edge accelerators
- Model converters
Pricing Model
Open-source
Best-Fit Scenarios
- Mobile AI apps
- Embedded systems
- Edge inference pipelines
#4 — ONNX Runtime
One-line verdict: Best for cross-platform inference with hardware acceleration flexibility.
Short description:
A high-performance runtime supporting multiple ML frameworks and hardware backends for inference.
Standout Capabilities
- Cross-framework compatibility
- Multi-hardware acceleration
- Optimized inference graphs
- Flexible deployment options
- Broad model support
- Enterprise-grade performance
AI-Specific Depth
- Model support: Multi-framework
- RAG / knowledge integration: N/A
- Evaluation: N/A
- Guardrails: N/A
- Observability: Basic
Pros
- Highly flexible
- Strong performance optimization
- Cross-platform support
Cons
- Complex setup
- Not LLM-specific
- Requires tuning
Security & Compliance
Not publicly stated
Deployment & Platforms
- Windows, Linux, macOS
- Mobile and edge devices
Integrations & Ecosystem
- PyTorch
- TensorFlow
- Azure ML
- Custom pipelines
Pricing Model
Open-source
Best-Fit Scenarios
- Cross-platform AI apps
- Enterprise inference systems
- Multi-device deployments
#5 — MLC LLM
One-line verdict: Best for deploying LLMs directly in web browsers and mobile devices.
Short description:
A runtime focused on compiling and running LLMs efficiently on edge and browser environments.
Standout Capabilities
- Web and mobile inference
- Compiler-based optimization
- GPU acceleration support
- Portable model execution
- Open-source flexibility
- Efficient runtime graph execution
AI-Specific Depth
- Model support: Open-source
- RAG / knowledge integration: N/A
- Evaluation: N/A
- Guardrails: N/A
- Observability: Limited
Pros
- Runs in browser environments
- Highly portable
- Efficient execution
Cons
- Early ecosystem
- Requires technical setup
- Limited tooling
Security & Compliance
Not publicly stated
Deployment & Platforms
- Web browsers
- Mobile
- Edge devices
Integrations & Ecosystem
- WebGPU
- JavaScript SDKs
- Model compilers
- Edge pipelines
Pricing Model
Open-source
Best-Fit Scenarios
- Browser-based AI apps
- Offline web assistants
- Lightweight edge deployments
#6 — ExecuTorch
One-line verdict: Best for production mobile AI inference in PyTorch-based workflows.
Short description:
A lightweight runtime designed to bring PyTorch models to mobile and edge devices efficiently.
Standout Capabilities
- PyTorch-native deployment
- Mobile optimization
- Hardware acceleration support
- Modular runtime design
- Efficient memory usage
- Edge-first architecture
AI-Specific Depth
- Model support: PyTorch-based
- RAG / knowledge integration: N/A
- Evaluation: N/A
- Guardrails: N/A
- Observability: Basic
Pros
- Strong PyTorch integration
- Mobile-first design
- Efficient runtime
Cons
- Early-stage ecosystem
- Limited tooling
- Requires optimization effort
Security & Compliance
Not publicly stated
Deployment & Platforms
- Android
- iOS
- Edge devices
Integrations & Ecosystem
- PyTorch ecosystem
- Mobile SDKs
- Hardware accelerators
Pricing Model
Open-source
Best-Fit Scenarios
- Mobile AI apps
- PyTorch-based deployments
- Edge inference systems
#7 — Core ML
One-line verdict: Best for native Apple ecosystem machine learning inference.
Short description:
Apple’s native framework for running ML models efficiently on-device across iOS and macOS.
Standout Capabilities
- Native Apple integration
- Highly optimized performance
- Secure on-device execution
- Hardware acceleration
- Low latency inference
- Energy efficiency
AI-Specific Depth
- Model support: Converted models
- RAG / knowledge integration: N/A
- Evaluation: N/A
- Guardrails: N/A
- Observability: Limited
Pros
- Excellent performance on Apple devices
- Strong privacy model
- Energy efficient
Cons
- Apple-only ecosystem
- Limited flexibility
- Conversion required
Security & Compliance
Apple-native security model (details beyond scope)
Deployment & Platforms
- iOS
- macOS
Integrations & Ecosystem
- Apple ML tools
- Swift APIs
- On-device frameworks
Pricing Model
Free (system framework)
Best-Fit Scenarios
- iOS AI apps
- On-device assistants
- Privacy-first mobile apps
#8 — GGML Ecosystem
One-line verdict: Best for low-level optimized inference for quantized LLMs on CPU devices.
Short description:
A foundational ecosystem for efficient LLM inference using quantized formats.
Standout Capabilities
- Quantized inference
- CPU optimization
- Lightweight runtime
- Model portability
- Edge suitability
AI-Specific Depth
- Model support: Open-source quantized models
- RAG / knowledge integration: N/A
- Evaluation: N/A
- Guardrails: N/A
- Observability: Basic
Pros
- Extremely lightweight
- Efficient CPU usage
- Flexible deployment
Cons
- Low-level complexity
- Minimal tooling
- Requires expertise
Security & Compliance
Not publicly stated
Deployment & Platforms
- Cross-platform CPU environments
Integrations & Ecosystem
- Model converters
- Inference tools
- Community frameworks
Pricing Model
Open-source
Best-Fit Scenarios
- Edge AI systems
- Research projects
- Lightweight deployments
#9 — Qualcomm AI Engine Direct
One-line verdict: Best for optimized AI inference on mobile and embedded Snapdragon hardware.
Short description:
A runtime optimized for Qualcomm hardware accelerators in mobile and edge devices.
Standout Capabilities
- NPU acceleration
- Mobile optimization
- Low-power inference
- Hardware-aware execution
- Edge AI support
AI-Specific Depth
- Model support: Vendor-optimized models
- RAG / knowledge integration: N/A
- Evaluation: N/A
- Guardrails: N/A
- Observability: Limited
Pros
- High efficiency on Snapdragon devices
- Low power consumption
- Strong mobile performance
Cons
- Hardware dependency
- Limited flexibility
- Vendor-specific tooling
Security & Compliance
Not publicly stated
Deployment & Platforms
- Snapdragon devices
- Mobile and embedded systems
Integrations & Ecosystem
- Qualcomm SDKs
- Mobile frameworks
- Edge pipelines
Pricing Model
Not publicly stated
Best-Fit Scenarios
- Mobile AI apps
- Embedded AI systems
- Edge inference workloads
#10 — MediaPipe
One-line verdict: Best for real-time on-device AI pipelines combining vision and language components.
Short description:
A framework for building multimodal real-time AI systems on mobile and edge devices.
Standout Capabilities
- Real-time processing pipelines
- Multimodal support (vision + language)
- Cross-platform deployment
- Efficient graph execution
- Mobile optimization
- Edge-friendly architecture
AI-Specific Depth
- Model support: Multi-framework
- RAG / knowledge integration: N/A
- Evaluation: N/A
- Guardrails: N/A
- Observability: Basic
Pros
- Real-time performance
- Strong multimodal support
- Cross-platform
Cons
- Not LLM-focused
- Complex setup
- Limited LLM tooling
Security & Compliance
Not publicly stated
Deployment & Platforms
- Android
- iOS
- Web
- Edge devices
Integrations & Ecosystem
- Google ML ecosystem
- Vision pipelines
- Mobile SDKs
Pricing Model
Open-source
Best-Fit Scenarios
- Real-time AI apps
- Mobile vision systems
- Edge multimodal pipelines
Comparison Table (Top 10)
| Tool Name | Best For | Deployment | Model Flexibility | Strength | Watch-Out | Public Rating |
|---|---|---|---|---|---|---|
| llama.cpp | CPU inference | Hybrid | Open-source | Efficiency | Low-level tuning | N/A |
| MLX | Apple devices | On-device | Open-source | Apple optimization | Ecosystem lock-in | N/A |
| TensorFlow Lite | Mobile AI | Edge | Open-source | Production stability | Not LLM-native | N/A |
| ONNX Runtime | Cross-platform | Hybrid | Multi-framework | Flexibility | Complexity | N/A |
| MLC LLM | Browser AI | Edge | Open-source | Web deployment | Early stage | N/A |
| ExecuTorch | PyTorch mobile | Edge | PyTorch | Mobile efficiency | Early ecosystem | N/A |
| Core ML | Apple ecosystem | On-device | Converted models | Native performance | Apple-only | N/A |
| GGML | CPU inference | Edge | Open-source | Lightweight | Technical complexity | N/A |
| Qualcomm AI Engine | Snapdragon devices | Edge | Vendor models | NPU acceleration | Hardware lock-in | N/A |
| MediaPipe | Real-time AI apps | Edge | Multi-framework | Multimodal pipelines | Not LLM-focused | N/A |
Scoring & Evaluation (Transparent Rubric)
The scoring below compares runtime efficiency, flexibility, and production readiness across on-device LLM execution stacks.
| Tool | Core | Reliability/Eval | Guardrails | Integrations | Ease | Perf/Cost | Security/Admin | Support | Weighted Total |
|---|---|---|---|---|---|---|---|---|---|
| llama.cpp | 9 | 6 | 4 | 7 | 8 | 10 | 7 | 8 | 7.9 |
| MLX | 8 | 7 | 4 | 7 | 8 | 9 | 8 | 7 | 7.8 |
| TensorFlow Lite | 9 | 8 | 5 | 9 | 7 | 9 | 8 | 9 | 8.2 |
| ONNX Runtime | 9 | 8 | 5 | 9 | 7 | 9 | 8 | 9 | 8.2 |
| MLC LLM | 8 | 7 | 4 | 7 | 7 | 9 | 7 | 7 | 7.5 |
| ExecuTorch | 8 | 7 | 4 | 8 | 7 | 9 | 7 | 7 | 7.6 |
| Core ML | 8 | 8 | 6 | 8 | 9 | 9 | 9 | 8 | 8.3 |
| GGML | 8 | 6 | 4 | 6 | 7 | 10 | 7 | 7 | 7.4 |
| Qualcomm AI Engine | 8 | 7 | 5 | 7 | 7 | 10 | 8 | 7 | 7.7 |
| MediaPipe | 8 | 7 | 5 | 8 | 8 | 9 | 8 | 8 | 7.9 |
Top 3 for Enterprise: Core ML, TensorFlow Lite, ONNX Runtime
Top 3 for SMB: llama.cpp, MLX, MLC LLM
Top 3 for Developers: llama.cpp, ONNX Runtime, ExecuTorch
Which On-Device LLM Runtime Is Right for You?
Solo / Freelancer
llama.cpp or MLX offer the easiest entry points for experimentation and offline AI tools.
SMB
MLC LLM and ONNX Runtime provide flexibility across platforms without heavy infrastructure.
Mid-Market
TensorFlow Lite and ExecuTorch are strong for scalable mobile deployment pipelines.
Enterprise
Core ML, ONNX Runtime, and TensorFlow Lite offer stability, governance, and hardware optimization.
Regulated industries
Core ML and TensorFlow Lite are strong due to local execution and reduced data exposure.
Budget vs premium
- Budget: llama.cpp, GGML, MLC LLM
- Premium: Core ML, Qualcomm AI Engine Direct
Build vs buy (when to DIY)
Build custom runtimes if you need extreme optimization or embedded control; otherwise use existing runtimes for faster deployment and reliability.
Implementation Playbook (30 / 60 / 90 Days)
30 Days
- Define target hardware (mobile, desktop, edge)
- Benchmark candidate runtimes
- Run small model inference tests
- Validate latency and memory usage
60 Days
- Integrate runtime into app pipeline
- Add model quantization workflows
- Optimize inference performance
- Implement offline capabilities
90 Days
- Scale across devices and environments
- Optimize energy consumption
- Add monitoring and fallback strategies
- Harden production deployment
Common Mistakes & How to Avoid Them
- Ignoring hardware constraints
- Using non-quantized models on edge devices
- Poor memory management
- Overlooking energy consumption
- No fallback to cloud inference
- Lack of benchmarking before deployment
- Choosing incompatible model formats
- Not optimizing token streaming
- Ignoring platform-specific optimization
- Over-engineering early prototypes
- Weak testing on real devices
- Poor cross-platform planning
- Not considering offline UX
FAQs
What is an on-device LLM runtime?
It is software that runs large language models directly on local hardware without relying on cloud servers.
Why run LLMs on-device?
For privacy, low latency, and offline functionality.
Are on-device models accurate?
They are smaller than cloud models, so performance depends on optimization and use case.
Do these runtimes need internet?
No, most support full offline inference.
What hardware is required?
Modern CPUs, GPUs, or NPUs depending on optimization level.
Can I run large models locally?
Yes, but they are usually quantized or compressed.
What is quantization?
A technique that reduces model size and improves speed.
Is GPU required?
Not always—CPU-based runtimes like llama.cpp work well.
Can I switch models dynamically?
Some runtimes support model switching, others require reloads.
Are these secure?
Yes, because data stays on-device, but implementation still matters.
What is the main limitation?
Hardware constraints like memory and compute power.
Are these production-ready?
Many are, especially Core ML, TensorFlow Lite, and ONNX Runtime.
Conclusion
On-device LLM runtimes are a foundational layer for private, fast, and offline AI systems. They enable a new class of applications where intelligence runs directly on user devices instead of relying on cloud infrastructure.
The right runtime depends heavily on your target hardware, performance needs, and ecosystem constraints. Some prioritize extreme efficiency, others focus on developer experience, and some are deeply integrated into specific hardware ecosystems.
Next steps:
- Shortlist runtimes based on target devices
- Benchmark performance with real models
- Validate offline capability, latency, and memory constraints before scaling