Introduction
Modern IT enterprises operate within hyper-complex, multi-cloud architectures. The widespread adoption of cloud-native infrastructure, dynamic microservices, and Kubernetes clusters has changed how software is shipped and maintained. However, this architectural velocity introduces an unprecedented volume of operational noise. Engineering teams find themselves inundated by thousands of decoupled metrics, unstructured log lines, and disparate distributed traces daily. When a critical production incident occurs, identifying the true root cause within an intricate web of dependencies becomes a high-stakes guessing game. Traditional, siloed monitoring frameworks fall short because they rely on static thresholds and manual intervention. This operational gridlock highlights the urgent need for intelligent, automated, and predictive IT management strategies. To close this operational gap, AIOpsSchool provides targeted training and authoritative resources designed to equip professionals with advanced automated operations skills. By embedding machine learning, statistical anomaly detection, and natural language processing into the core of the infrastructure lifecycle, Artificial Intelligence for IT Operations (AIOps) shifts engineering teams from reactive firefighting to proactive, autonomous system management.
What Is AIOps?
AIOps, or Artificial Intelligence for IT Operations, is the application of machine learning, big data analytics, and automation to IT operations. It aggregates large-scale logs, metrics, and traces across distributed infrastructure to automatically isolate anomalies, correlate related events, determine root causes, and initiate automated self-healing workflows in real time.
Understanding AIOps
What Is Artificial Intelligence for IT Operations?
At its core, AIOps represents the convergence of big data analytics, machine learning algorithms, and traditional IT operational practices. It introduces algorithmic intelligence directly into the monitoring and observability pipeline. Instead of relying on manual investigation, an AIOps layer ingests continuous operational telemetry, learns the behavioral baseline of the infrastructure, and isolates underlying system degradations before they impact end users.
In Simple Terms
Imagine an IT infrastructure as a massive, bustling international airport. Traditional operations rely on a few human security guards looking at hundreds of video screens simultaneously to spot a problem. AIOps acts like an advanced AI assistant that instantly monitors every camera, sensor, and boarding pass scanner at the same time, immediately flagging suspicious patterns and fixing gate bottlenecks before a line even forms.
Real-World Example
An enterprise e-commerce platform undergoes a sudden database CPU spike. Instead of page alerts firing across five distinct engineering teams, the AIOps platform identifies that the database load was triggered by a bad code deployment upstream. It automatically traces the dependency, links the specific Git commit hash to the infrastructure degradation, and surfaces a single, contextual incident ticket to the deployment team.
Why It Matters
As distributed environments grow, the volume of telemetry data outpaces human cognitive capacity. AIOps bridges this gap by converting petabytes of unorganized operational noise into structured, actionable insights. This directly protects corporate revenue by reducing systemic downtime and freeing skilled engineers to focus on product feature delivery rather than repetitive firefighting.
Key Takeaways
- Connects big data and machine learning to optimize infrastructure maintenance.
- Shifts operational posture from reactive firefighting to predictive remediation.
- Simplifies vast, noisy monitoring streams into highly contextualized incidents.
Why Traditional IT Operations Are No Longer Enough
Traditional IT operations rely heavily on deterministic rules and static thresholds—such as triggering a high-priority alert when a server’s CPU usage reaches 85%. In a dynamic, containerized environment where microservices scale up and down continuously, these rigid thresholds break down. They create massive alert fatigue, mask transient faults, and fail to account for complex multi-system dependencies where no single component breaches a limit, yet the collective user experience degrades.
How AI and Machine Learning Improve Operations
By utilizing unsupervised machine learning models, time-series anomaly detection, and natural language processing (NLP), AIOps platforms analyze historic behavior to establish dynamic baselines. The system learns what “normal” looks like for every hour of the week, taking seasonal traffic into account. When a telemetry metric deviates from this calculated variance, the AI flags it, correlates it with concurrent network changes, and evaluates historical patterns to recommend the most effective remediation script.
Evolution from Monitoring to Intelligent Operations
Monitoring tells an engineer when a specific component is broken. Observability allows an engineer to infer why a complex system is misbehaving by exploring raw telemetry. AIOps represents the next evolutionary milestone: it automatically parses that observability data, determines the root cause, and orchestrates an autonomous response to fix the issue without human intervention.
| Traditional Operations | AIOps-Driven Operations |
| Relies on static thresholds (e.g., CPU > 80%). | Utilizes dynamic, machine-learned baselines. |
| Fragmented tools create disconnected operational silos. | Centralized data platform correlates multi-source telemetry. |
| Manual root cause analysis across multiple teams. | Automated root cause isolation powered by ML. |
| High volume of redundant, un-correlated alerts. | Algorithmic event deduplication and correlation. |
| Reactive response after service interruption occurs. | Predictive anomaly detection before failures happen. |
Why AIOps Skills Are Becoming Essential
Growth of Cloud-Native Infrastructure
Cloud-native infrastructure relies on ephemeral components that live for hours or minutes. Managing these workloads requires real-time algorithmic analysis. Engineers must know how to configure systems that interpret transient failures without triggering unnecessary emergency responses.
Rise of Distributed Systems
Microservice patterns mean a single user request can pass through dozens of services, API gateways, and databases. When a latency spike happens, tracing the exact microservice responsible requires sophisticated AI correlation engines. Professionals need specialized training to deploy and calibrate these tracing models.
Demand for Reliability Engineering
Organizations are shifting away from classic sysadmin models toward Site Reliability Engineering (SRE). SRE principles demand that operational tasks be treated as software engineering problems. AIOps skills provide the automation and data science foundations required to implement programmatic reliability at scale.
Automation of Incident Management
The modern incident lifecycle requires machine-speed containment. Understanding how to wire AIOps engines into automated runbooks allows teams to trigger self-healing protocols—like restarting pods or purging edge caches—the moment an anomaly is verified, dropping mean time to resolution (MTTR) significantly.
Future of Autonomous Operations
We are moving steadily toward the era of the self-healing data center. The engineers who understand how to train, govern, and audit these autonomous loops will be the ones designing and leading enterprise platform architectures over the next decade.
AIOps Certification Explained
What Is an AIOps Certification?
An AIOps Certification is a professional credential that validates an engineer’s competence in blending data science with system operations. It certifies that a practitioner can design data ingestion pipelines, apply machine learning models to infrastructure telemetry, configure automated event correlation engines, and build closed-loop remediation frameworks.
In Simple Terms
Think of it like an advanced pilot’s license designed specifically for flying automated commercial jets. It proves to an employer that you don’t just know how to manually steer the plane when things are smooth; you deeply understand how the automated navigation systems think, how to configure them, and exactly how to take control or reprogram them if the system hits an unexpected storm.
Real-World Example
An enterprise bank is modernizing its central transaction processing network. To ensure operational stability, the HR and engineering departments specifically mandate that the Lead Platform Architect hold an active AIOps Engineer Certification. This certification ensures the architect can confidently integrate unsupervised anomaly detection engines into their high-compliance payment gateways without risking false-positive service blocks.
Why It Matters
For individuals, certification provides a structured path to mastering an emerging domain and signals high-value technical capability to the global job market. For enterprises, employing certified professionals mitigates the risk of failed implementation initiatives and ensures that advanced operations tools are configured according to industry-standard architecture frameworks.
Key Takeaways
- Formalizes the cross-disciplinary skills of data science and systems engineering.
- Validates an individual’s ability to implement complex machine learning pipelines.
- Assures organizations that their automation infrastructure is robust and compliant.
Benefits of Professional Certification
- Career Differentiation: Separates your profile from standard cloud administrators by showcasing specialized AI-driven automation capabilities.
- Structured Learning Curve: Eliminates fragmented knowledge by offering a clear path from data ingestion fundamentals to advanced closed-loop automation.
- Command Higher Compensation: Industry data indicates certified automation and AIOps engineers command a significant premium over traditional operations personnel.
- Organizational Velocity: Certified teams deploy operational AI models faster, reducing proof-of-concept failure rates by adhering to vetted blueprints.
Skills Validated Through Certification
An enterprise-grade certification program tests across multiple disciplines:
- Mathematical foundations of anomaly detection and time-series forecasting.
- Multi-source telemetry ingestion across distributed hybrid-cloud topologies.
- Advanced configuration of event deduplication and topological correlation matrices.
- Secure design of automated self-healing workflows and declarative runbook policies.
Who Should Pursue AIOps Certification?
- DevOps Engineers: Looking to augment standard CI/CD and infrastructure-as-code routines with predictive deployment health checking.
- SRE Engineers: Seeking to eliminate systemic toil and build highly advanced, algorithmically driven error-budget alerting frameworks.
- Cloud & Platform Engineers: Tasked with building and maintaining stable, automated internal developer platforms (IDPs).
- Monitoring Specialists: Evolving their careers from building static dashboards to managing enterprise-wide intelligent observability systems.
- IT Managers & Directors: Wanting to deeply understand the underlying engineering realities of AI implementation to effectively guide corporate digital transformations.
AIOps Training and Courses
What Learners Typically Study
[Telemetry Ingestion] ---> [Algorithmic Processing] ---> [Automated Action]
(Metrics, Logs, Traces) (ML Correlation & RCA) (Self-Healing/Alert)
Machine Learning for IT Operations
Learners explore the distinct types of machine learning algorithms applicable to operations. This includes studying unsupervised clustering models for grouping related logs, supervised classification for identifying known error patterns, and regression modeling to accurately forecast future system capacity exhaustion.
Event Correlation
This domain covers how to combine hundreds of isolated notifications into a handful of actionable incidents. Students master how to configure topological correlation (using network and infrastructure maps) and temporal correlation (grouping events that occur within identical time windows) to isolate systemic root causes.
Intelligent Alerting
Traditional alerts create overwhelming noise. Training focuses on building context-aware alerting systems that evaluate the health of an entire system rather than isolated metrics, ensuring engineers are only woke up for verified, business-critical system degradations.
Root Cause Analysis
Participants study how graph databases and causal inference models map dependencies across multi-tier applications. This allows the AIOps engine to automatically traverse dependency nodes during an incident and pinpoint the specific microservice or bad database query that initiated a cascading failure.
Predictive Analytics
This module covers forecasting infrastructure trends. Engineers learn to analyze long-term disk utilization, memory leaks, and application usage patterns to accurately predict when a system will run out of resources weeks before it happens.
Incident Automation
Students dive into closed-loop remediation. They learn how to safely link AIOps platform outputs to API endpoints, automation servers, and configuration managers to execute precise self-healing actions without needing manual operator approval.
Observability
This topic explores the paradigm shift from basic external system monitoring to deep structural observability. It focuses on engineering applications to surface their internal state transparently, providing high-cardinality data for machine learning models to analyze.
OpenTelemetry
As the open industry standard for telemetry collection, extensive time is spent learning how to deploy the OpenTelemetry Collector, instrument application code with vendor-neutral SDKs, and efficiently manage the transport of metrics, logs, and distributed traces.
Monitoring Automation
Learners study how to programmatically deploy and configure monitoring agents at scale. By using tools like Terraform and Ansible alongside AIOps platforms, monitoring configurations dynamically scale up or down as new infrastructure components are provisioned.
AIOps Engineer Certification Path
To build authentic expertise, engineers should follow a structured progression model that systematically moves from foundational infrastructure monitoring to advanced autonomous platform engineering.
| Level | Skills | Outcome |
| Beginner | Core Linux administration, basic networking, cloud platform essentials, static monitoring with PromQL, and basic log aggregation techniques. | Capable of deploying monitoring agents, building infrastructure dashboards, and managing basic alert configurations. |
| Intermediate | OpenTelemetry instrumentation, distributed tracing architecture, python programming, intermediate statistics, and time-series anomaly detection. | Able to implement end-to-end system observability and construct basic algorithmic alert correlation pipelines. |
| Advanced | Machine learning model training, deep causal graph analysis, building closed-loop automated self-healing infrastructure, and enterprise AI governance. | Qualified to architect full enterprise AIOps platforms, design autonomous runbooks, and lead operational transformations. |
AIOps Engineer Career Roadmap
Required Technical Skills
Linux
The foundation of modern enterprise infrastructure. A professional must understand kernel parameters, file system tuning, systemd process management, and how to query low-level OS performance metrics directly.
Networking
Distributed systems live and die by the network. Deep knowledge of TCP/IP, HTTP/2, gRPC protocols, DNS routing, load balancing mechanics, and service mesh patterns (like Istio) is mandatory for troubleshooting modern distributed application bottlenecks.
Cloud Platforms
Proficiency in handling large-scale public and hybrid cloud environments (AWS, Azure, GCP). This includes understanding their respective managed telemetry solutions, identity governance structures, and scalable compute platforms.
Kubernetes
As the standard execution layer for cloud-native software, an AIOps engineer must understand container orchestration deeply. This includes scheduling mechanics, custom resource definitions (CRDs), operators, and internal cluster networking.
Monitoring Tools
Practical experience with standard open-source tools and enterprise platforms (such as Prometheus, Grafana, Datadog, or Dynatrace). Knowing how to deploy these platforms and extract value from them is a prerequisite for layering on AI capabilities.
Automation
Fluency with Infrastructure as Code (IaC) tools like Terraform and config automation engines like Ansible. Engineers must know how to programmatic alter infrastructure configurations in response to algorithmic insights.
Python
The primary language of data science and automation scripting. AIOps practitioners use Python to clean dirty telemetry data, interact with machine learning APIs, and build custom integration scripts between systems.
Observability
A clear understanding of high-cardinality and high-dimensionality data structures. Practitioners must know how to enrich telemetry data with context tags, allowing analytical models to quickly slice and dice information during major outages.
Learning Sequence
- Master Systems and Networking Basics: Build a rock-solid foundation in Linux administration, network transport protocols, and standard public cloud operations.
- Implement Core Monitoring and Aggregation: Learn to configure standard Prometheus monitoring, collect logs via FluentBit, and visualize patterns using Grafana dashboards.
- Transition to Advanced Observability: Adopt OpenTelemetry standards. Instrument custom applications to output distributed traces and map end-to-end request flows.
- Learn Practical Scripting and Data Manipulation: Develop intermediate Python skills, focusing on data libraries like Pandas and NumPy to manipulate and analyze time-series metrics.
- Apply Algorithmic Processing and AIOps Platforms: Study machine learning pipelines. Learn to connect telemetry streams to AIOps platforms to configure event correlation and automated root cause analysis.
- Design and Implement Closed-Loop Automation: Learn to safely connect AI outputs to automated runbooks, turning predictive insights into reliable self-healing infrastructure actions.
AI Observability Training
What Is AI Observability?
AI Observability represents the application of artificial intelligence to modern multi-dimensional telemetry data. While classic monitoring tracks whether a system is running or stopped, AI Observability evaluates the complex internal states of distributed components. It maps dependencies in real time, automatically isolating hidden degradation patterns across complex application landscapes.
In Simple Terms
Standard monitoring is like checking a patient’s temperature with a basic thermometer; it tells you if they have a fever, but not why. AI Observability is equivalent to an advanced, continuous MRI scan combined with an AI medical assistant. It analyzes blood flow, organ performance, and neurological patterns in real time, pinpointing exactly which minor internal imbalance is causing the temperature spike.
Real-World Example
During a peak traffic event, an international shipping platform encounters random checkout slowdowns. Standard tools show normal CPU and memory usage across all web servers. AI Observability analyzes the distributed traces and surfaces an anomaly: a minor database lock contention is occurring deep within a third-party inventory microservice, impacting only a specific subset of international orders.
Why It Matters
Modern applications fail in complex, unexpected ways that static dashboards cannot predict. AI Observability training teaches engineers how to surface deep structural system metrics. This allows machine learning engines to quickly pinpoint the actual cause of multi-system failures, replacing prolonged war-room guessing sessions with precise data visualization.
Key Takeaways
- Evaluates complex internal system behavior instead of relying on external status checks.
- Automatically surfaces hidden dependency patterns across distributed microservices.
- Provides the high-context telemetry data required to feed machine learning models.
Why Observability Matters
Without deep observability, AI engines are blind. An AIOps platform requires rich, highly contextualized telemetry data to accurately learn patterns and avoid generating false alerts. Training engineers in observability ensures that enterprise systems output clean, high-quality data.
Logs, Metrics, Traces, and Events
These represent the core pillars of telemetry:
- Metrics: Numerical values measured over intervals (e.g., memory utilization trends).
- Logs: Timestamped text records generated when specific code paths execute.
- Traces: End-to-end journeys of individual requests as they travel through a distributed system.
- Events: Higher-level structured records of critical operational milestones (e.g., code deployments, cloud auto-scaling actions).
OpenTelemetry Fundamentals
OpenTelemetry (OTel) provides a unified, vendor-neutral framework for collecting and exporting telemetry. Training focuses on deploying OTel collectors, configuring processors to scrub sensitive data, and standardizing telemetry schemas so they can be consumed by any enterprise AIOps platform.
Intelligent Monitoring Systems
Intelligent monitoring scales beyond classic, static warning thresholds. It applies seasonal tracking and anomaly detection algorithms directly to metric streams, ensuring the system naturally adapts to normal business cycles—like high traffic on Friday afternoons—without triggering false alarms.
| Monitoring | Observability |
| Focuses on tracking known failure modes (“Is the disk full?”). | Enables exploration of unknown failure modes (“Why is this request slow?”). |
| Relies on static alerts and simple dashboards. | Leverages high-cardinality data for deep querying. |
| Provides a siloed, component-by-component view of infrastructure. | Delivers a unified, end-to-end understanding of request lifecycles. |
| Informs you that a specific system component is currently broken. | Explains why a complex, distributed system is misbehaving. |
AIOps for SRE and DevOps Engineers
How AIOps Supports SRE Practices
Site Reliability Engineering centers on balancing velocity with system reliability. AIOps supports this balance by automating the collection of reliability metrics and tracking error budgets in real time. This gives SRE teams the predictive insights needed to decide exactly when to freeze deployments before an actual service level objective (SLO) breach occurs.
In Simple Terms
Think of an SRE team as the maintenance crew for a high-speed bullet train. DevOps engineers are busy building faster train cars, while SREs ensure the tracks don’t fail. AIOps acts like an automated track sensor system that constantly scans miles ahead, detecting tiny track misalignments and instantly informing the crew exactly where and when to make adjustments before the train ever encounters a bump.
Real-World Example
A global streaming platform rolls out a new recommendation engine. The AIOps platform monitors the canary deployment, analyzing millions of log lines and user trace structures. Within three minutes, it notes a 0.04% increase in microservice latency that indicates an underlying memory leak, automatically triggering an immediate rollback before any end-users notice a delay.
Why It Matters
SRE and DevOps teams are frequently overwhelmed by operational maintenance (“toil”). Implementing AIOps automates repetitive diagnostic tasks, allowing engineering teams to scale their infrastructure footprint sustainably without requiring a linear increase in operations headcount.
Key Takeaways
- Shields error budgets by identifying and calling out system regressions early.
- Automates manual data collection during major infrastructure incidents.
- Allows engineering teams to manage massive infrastructure scale without scaling burnout.
Reducing Alert Fatigue
By using algorithmic deduplication and temporal clustering, AIOps platforms condense thousands of scattered infrastructure alerts into a single, cohesive incident ticket. This stops on-call engineers from being overwhelmed by notification storms during an outage, letting them focus entirely on applying the fix.
Improving Incident Response
When an outage happens, the AIOps engine immediately generates a summary detailing when the anomaly started, which systems are affected, and what changes occurred concurrently. This eliminates long discovery cycles and slashes the Mean Time to Repair (MTTR) from hours to minutes.
Enhancing Reliability Engineering
AIOps shifts reliability teams from reacting to post-mortem data to proactively hardening systems. By identifying weak points and minor structural anomalies before they cascade into outages, engineers can systematically reinforce infrastructure resilience.
Supporting Continuous Delivery
By integrating AIOps into CI/CD pipelines, deployment tools can run automated, algorithmic health checks on new code versions. If the AI detects anomalous application performance during a canary release, it safely automates a rollback, ensuring production stability.
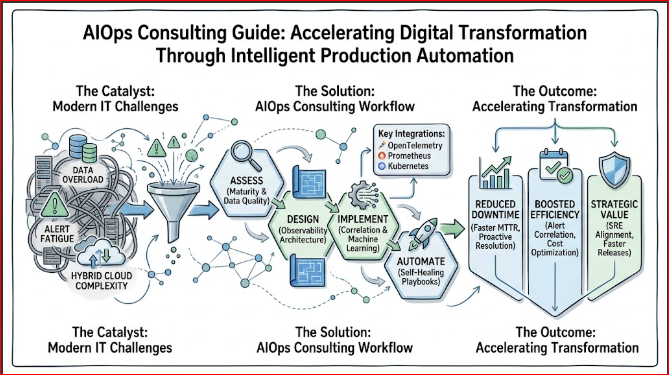
Enterprise AIOps Consulting
Why Organizations Need AIOps Consulting
Deploying an enterprise-grade AIOps platform is more than just installing software; it requires a well-planned operational transformation. Enterprise consulting ensures companies select the right tools, architect efficient data ingestion pipelines, align their team workflows, and avoid costly implementation mistakes.
In Simple Terms
Buying an AIOps platform without expert consulting is like purchasing a state-of-the-art automated factory system, having it delivered in crates, and trying to set it up without blueprints. An AIOps consultant serves as the master industrial engineer who designs the factory floor layout, wires the machines together safely, and trains your team to run the control room efficiently.
Real-World Example
A multinational financial institution spent millions on top-tier AIOps tooling but saw no reduction in downtime because their teams configured it to mimic their old static alerts. A specialist consulting team stepped in, re-architected their telemetry pipeline, implemented proper topological correlation, and trained their engineers, successfully reducing false alerts by 82% within 90 days.
Why It Matters
Without expert guidance, enterprise AIOps initiatives often turn into expensive dashboard migration projects that fail to deliver real automation. Strategic consulting aligns your business objectives, team culture, and technology stack to ensure a measurable return on your automation investments.
Key Takeaways
- Prevents costly tool misconfigurations and failed enterprise adoptions.
- Aligns multi-department workflows to support automated operational actions.
- Focuses on shifting company culture from reactive fixing to trusted automation.
Assessing Operational Maturity
Consultants evaluate an organization’s existing capabilities before deploying tools. This assessment grades data cleanlines, current monitoring coverage, and operational workflows to ensure the team is ready to successfully adopt AI-driven automation.
Tool Selection Strategies
The AIOps tool landscape includes open-source frameworks, platform-native additions, and comprehensive enterprise suites. Consulting helps organizations select technologies that match their existing stack, scaling requirements, compliance standards, and long-term engineering budgets.
Building AIOps Roadmaps
A successful corporate rollout follows a stepped phase approach. Consultants build tailored execution roadmaps that prioritize quick, high-value wins—like deduplicating noisy alerts—before moving on to complex goals like automated self-healing workflows.
Change Management Considerations
Shifting operations teams from manual intervention to trusting automated AI insights requires intentional cultural change. Consulting provides clear strategies to retrain staff, redefine team roles, and build organizational confidence in automated system remediation.
AIOps Implementation Services
Implementing an enterprise-grade AIOps platform requires a structured, multi-phase lifecycle to ensure data integrity, operational reliability, and scalable automation.
+--------------+ +------------+ +----------------+ +---------------+
| Assessment | --> | Design | --> | Tool Selection | --> | Integration |
+--------------+ +------------+ +----------------+ +---------------+
|
+--------------+ +------------+ +----------------+ |
| Optimization | <-- | Automation | <-- | Optimization | <-----------+
+--------------+ +------------+ +----------------+
Assessment
Engineers analyze the existing infrastructure stack, mapping all data sources, tool sets, logging standards, and current incident management workflows to establish an operational baseline.
Design
Architects create the formal data-flow blueprints. This phase defines how logs, metrics, and traces will be ingested, where enrichment will occur, and how the machine learning correlation engines will sit alongside production environments.
Tool Selection
Selecting the specific platform components, agents, and data storage systems that fit the enterprise’s architectural footprint, long-term scaling targets, and regulatory compliance constraints.
Integration
Deploying telemetry collectors across the infrastructure, establishing centralized data pipelines, and connecting the AIOps platform to existing ticketing systems and communication channels.
Automation
Configuring event deduplication policies, building topological correlation models, and creating verified self-healing runbooks that connect to orchestrators to fix common issues automatically.
Optimization
Continuously refining the machine learning models. Engineers analyze data patterns, adjust anomaly thresholds, and tune correlation rules to eliminate false alerts and improve root cause accuracy.
Continuous Improvement
Regularly auditing the AIOps ecosystem to integrate new infrastructure components, update automation scripts, and ensure the platform scales smoothly alongside changing business requirements.
Real-World Enterprise Use Cases
Banking and Financial Services
- Operational Challenge: A major retail banking network suffered intermittent mobile login failures during peak morning hours. Their disconnected monitoring tools generated isolated alerts across database, network, and application teams, resulting in an average of 4 hours to locate the issue.
- AIOps Solution: The bank implemented a centralized AIOps engine that integrated real-time application metrics and database query logs, mapping their relationships topologically.
- Business Outcome: The platform automatically linked login failures to a specific microservice configuration error during peak loads, dropping their MTTR from 4 hours to under 4 minutes.
Healthcare Platforms
- Operational Challenge: A large telemedicine provider experienced unpredictable alert storms across its patient video infrastructure, overwhelming on-call medical IT teams with duplicate notifications and slowing down system support.
- AIOps Solution: They deployed AI observability training patterns and automated event correlation to deduplicate identical alerts coming from identical server pools.
- Business Outcome: Reduced overall alert volume by 75%, allowing the core platform engineering team to focus on maintaining stable video consult uptimes.
SaaS Companies
- Operational Challenge: A fast-growing B2B software company struggled with memory leak degradations that regularly crashed customer container environments during new software rollouts.
- AIOps Solution: They built time-series predictive analytics directly into their Kubernetes deployment pipelines.
- Business Outcome: The AIOps engine automatically flags anomalous memory consumption trends within minutes of a rollout, safely triggering self-correcting container restarts and automated code rollbacks.
Telecommunications
- Operational Challenge: Core routing hardware faults routinely triggered cascading network alert storms across thousands of connected downstream cell towers, making root cause identification impossible for human operators.
- AIOps Solution: They implemented temporal and spatial network topology correlation models to instantly group regional alerts.
- Business Outcome: Isolated the specific faulty physical switch instantly, allowing field engineers to be dispatched immediately and protecting regional service SLAs.
E-Commerce Platforms
- Operational Challenge: Flash sale traffic surges caused unexpected microservice latency bottlenecks that dropped checkout conversion rates without breaching any traditional static monitoring thresholds.
- AIOps Solution: They deployed dynamic baseline modeling to track shifting checkout transaction patterns during high-volume sales.
- Business Outcome: The platform detects minor variance trends early, automatically scaling up specific microservice instances before users experience any visible checkout lag.
Benefits of AIOps Adoption
- Reduced Downtime: Identifying and mitigating underlying infrastructure risks before they cascade into user-facing outages keeps critical business platforms online.
- Faster Root Cause Analysis: Algorithmic dependency mapping traces paths in seconds, pinpointing the exact cause of complex incidents and replacing long manual root cause analysis.
- Better User Experience: Proactively fixing latency issues, system bugs, and regional resource constraints ensures end users experience snappy, reliable application performance.
- Reduced Operational Costs: Minimizing time spent on manual firefighting and avoiding critical outages directly reduces engineering costs and protects corporate revenue.
- Improved Reliability: Shifting from reactive incident response to predictive automated remediation raises the overall baseline stability of enterprise systems.
- Smarter Decision-Making: Replacing guesswork with clear, data-driven machine learning insights helps leadership teams allocate cloud spend and engineering resources efficiently.
Common Challenges in AIOps Adoption
- Data Quality Issues: Machine learning models require clean, well-structured data. Missing telemetry fields and disorganized log formats can lead to inaccurate alerts.
- Solution: Standardize data ingestion using OpenTelemetry schemas and validate log formats at the application level.
- Tool Integration Challenges: Legacy IT tools and newer cloud-native software often use disconnected data structures that are difficult to centralize.
- Solution: Use dedicated integration layers and unified data collectors to normalize telemetry before sending it to the AI engine.
- Skills Gap: Traditional operations teams often lack the software engineering and data science fundamentals needed to run complex AIOps platforms.
- Solution: Invest in structured training pipelines and hands-on professional certification programs.
- Organizational Resistance: Engineers are often skeptical of automated actions and can be hesitant to trust an AI engine to manage production environments.
- Solution: Start with read-only AI insights, and transition to automated self-healing workflows only after proving model accuracy.
- Lack of Observability Maturity: Trying to implement advanced AIOps models on top of systems that lack basic log, metric, and trace data leads to poor results.
- Solution: Focus on building out core system observability frameworks before enabling advanced machine learning layers.
Common Mistakes Professionals Make
- Focusing Only on Tools: Assuming that simply buying an expensive platform license will automatically solve underlying organizational and process issues.
- Ignoring Observability Fundamentals: Attempting to build predictive AI models without first ensuring their systems emit high-quality, structured telemetry data.
- Poor Data Collection: Ingesting raw, unfiltered data logs into AI platforms, which bloats storage costs and slows down analytical processing engines.
- Skipping Automation Strategy: Failing to design clear rules and safety boundaries for automated runbooks, rendering AI insights non-actionable.
- Lack of Continuous Learning: Neglecting to continuously update operational skills as machine learning models and cloud-native platforms evolve.
Future of AIOps
Autonomous Operations
The long-term future of IT operations points toward fully autonomous, self-governing infrastructure systems. These platforms will continually evaluate their own health, update their underlying code parameters, and optimize resource performance without needing human intervention.
AI-Driven Incident Management
We will see incident response move entirely to machine speeds. AI platforms will handle the entire lifecycle—from initial anomaly detection and cross-team communication to root cause isolation and final automated resolution—in fractions of a second.
Predictive Reliability Engineering
Instead of investigating incidents after they occur, SRE teams will focus on analyzing predictive simulations. AI engines will continuously run simulated stress tests against production digital twins, fixing hidden failure risks before they can manifest in real life.
Intelligent Capacity Planning
Cloud infrastructure will dynamically adjust its footprint based on highly accurate future usage forecasts. AI engines will coordinate multi-cloud resource use in real time, shifting workloads globally to take advantage of low energy costs and optimal performance zones.
Self-Healing Infrastructure
Declarative infrastructure code will be paired with active self-healing loops. If a component degrades or a security vulnerability is identified, the system will automatically rewrite its own configuration files, test the fix, and safely deploy the update.
AI-Powered Observability
Telemetry collection will become entirely automated. Applications will feature native self-instrumentation capabilities, dynamically adjusting the depth of metrics, logs, and traces they output based on the real-time operational context of the system.
Why Learn with AIOpsSchool
As modern IT systems grow in complexity, classic monitoring approaches are no longer sufficient to maintain operational stability. Professionals who master the intersection of cloud architecture, data analytics, and automated operations will lead the next wave of enterprise platform engineering.
AIOpsSchool addresses this critical industry skills gap directly. By offering an industry-focused curriculum, hands-on labs, and formal certification paths, the platform provides engineers and technology leaders with the practical skills required to deploy robust AI observability frameworks and automated incident remediation systems.
Whether you are looking to advance your personal technical career or looking to guide an enterprise digital transformation, mastering these automated operations skills is the clearest path to building resilient, scalable, and self-healing infrastructure for the future.
FAQ SECTION
1. What is AIOps Certification?
An AIOps Certification is an industry credential that validates an engineer’s ability to integrate machine learning and big data automation into IT operations. It proves you know how to ingest telemetry, build correlation models, and design automated self-healing workflows.
2. Who should learn AIOps?
DevOps engineers, Site Reliability Engineers (SREs), systems administrators, cloud architects, and technology managers who want to automate manual operations and manage large-scale cloud-native infrastructure efficiently should learn AIOps.
3. What skills are required for AIOps Engineers?
AIOps engineers need a mix of core systems administration (Linux, networking), cloud orchestration (Kubernetes), programming (Python), data processing (statistics, time-series analysis), and familiarity with modern observability frameworks (OpenTelemetry).
4. How does AIOps help DevOps teams?
AIOps assists DevOps teams by automating the analysis of deployment health, reducing alert fatigue through event deduplication, identifying root causes instantly, and executing automated code rollbacks when production performance deviates from normal baselines.
5. What is AI Observability?
AI Observability is the practice of using machine learning models to analyze high-cardinality systems data (metrics, logs, and traces). It allows teams to understand complex, unpredictable internal system behavior instead of simply tracking whether a component is active.
6. What is OpenTelemetry?
OpenTelemetry is an open-source, vendor-neutral framework designed to standardize how applications generate, collect, and export telemetry data (metrics, logs, and traces), providing clean data streams for AIOps engines to analyze.
7. How long does it take to learn AIOps?
For professionals with an existing background in DevOps or systems engineering, mastering foundational AIOps concepts and tool workflows typically takes 3 to 6 months of structured, hands-on study.
8. What are AIOps Implementation Services?
AIOps Implementation Services are specialized enterprise consulting engagements that guide organizations through assessing maturity, choosing tools, building ingestion pipelines, configuring correlation algorithms, and safely deploying automated runbooks.
9. Is AIOps a good career choice?
Yes, AIOps is a highly lucrative and rapidly growing career track. As multi-cloud architectures grow more complex, enterprises are heavily prioritizing hiring engineers who can implement intelligent automation over traditional manual support roles.
10. What is the future of AIOps?
The future of AIOps centers on fully autonomous, self-healing infrastructure. Systems will shift from simply alerting teams about anomalies to independently running diagnostics and repairing complex operational faults without human intervention.
FINAL SUMMARY
Navigating the velocity of modern cloud-native systems requires shifting away from manual, threshold-based monitoring. As application footprints expand, utilizing machine learning to analyze telemetry noise is the only sustainable path to protecting system uptime. Organizations that implement formal AIOps training pathways and certifications ensure their engineering teams possess the skills needed to design clean observability pipelines, configure accurate event correlation engines, and deploy trusted automation. For the individual professional, acquiring specialized AIOps expertise provides a clear competitive edge in a rapidly evolving job market.