Introduction
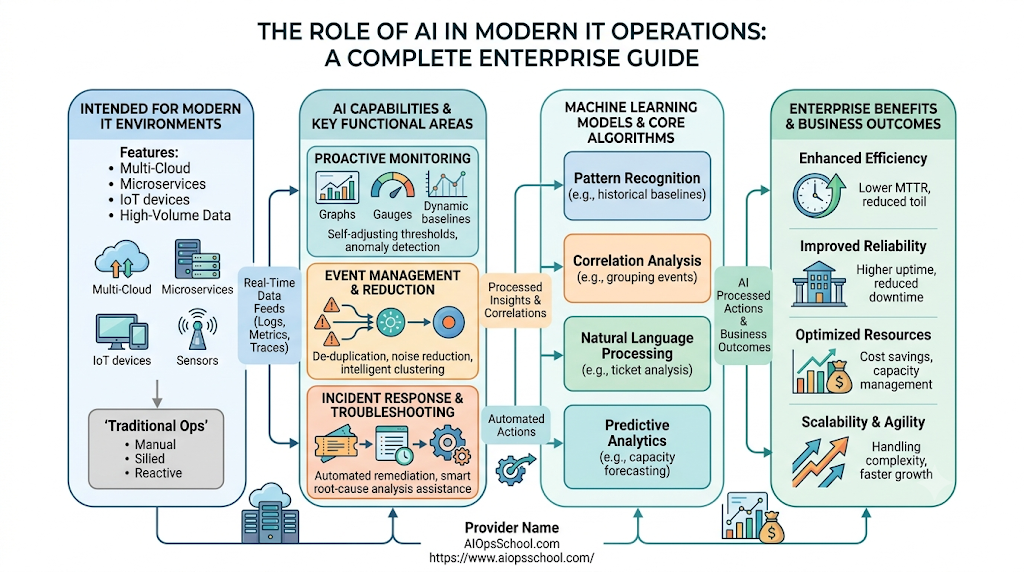
Modern corporate systems are growing faster than human teams can keep up. The move to multi-cloud setups, microservices, and container networks creates millions of data points every second. Traditional monitoring methods simply cannot process this massive influx of information. Historically, IT operations management relied on static thresholds and manual alerts. When a database slow-down triggered an alert, engineers spent hours sifting through logs to find the root cause. This manual approach creates a continuous cycle of firefighting, high downtime, and severe alert fatigue. Artificial intelligence provides a way out of this cycle. By acting as the central nervous system for technology infrastructure, AI turns raw data into actionable insights. It shifts the burden of sorting through noise from human engineers to intelligent algorithms, allowing systems to anticipate issues before they cause service disruptions. To help professionals adapt to this new environment, resources like AIOpsSchool.com offer targeted educational paths. This platform helps teams close the skills gap and adopt advanced machine learning techniques for systems engineering.
3. What Is AI in Modern IT Operations?
Featured Snippet Definition: AI in Modern IT Operations (AIOps) is the application of machine learning, natural language processing, and advanced analytics to automate the ingestion, correlation, and resolution of enterprise IT infrastructure data in real time.
[Raw IT Data: Logs, Metrics, Traces]
│
▼
┌──────────────────────────────────────────────┐
│ AI / Machine Learning Engine │
│ (Anomaly Detection & Event Correlation) │
└──────────────────────────────────────────────┘
│
▼
[Actionable Insights / Automated Self-Healing]
The primary objectives of intelligent IT operations are simple:
- Centralize disparate data streams into a single source of truth.
- Isolate real system failures from harmless background noise.
- Automate repetitive resolution steps without manual intervention.
- Predict future resource constraints based on historical patterns.
The discipline has evolved significantly over the past few decades. IT management started with manual oversight, where engineers watched screens for blinking lights. It then moved to rule-based automation, which quickly failed when cloud environments began scaling dynamically. Today, we rely on algorithmic observability—systems that learn normal operating baselines on their own and adapt without manual rule updates.
Organizations are adopting AI-powered IT management because modern application complexity has surpassed human cognitive limits. An enterprise app running across hundreds of distributed microservices generates far too many metrics for traditional dashboards to trace effectively.
4. Fundamentals of Modern IT Operations
Before deploying machine learning models, IT teams must understand the foundational pillars of infrastructure management that AI aims to optimize.
Infrastructure Monitoring
Monitoring involves tracking the physical and virtual assets powering an enterprise. This includes checking CPU utilization on virtual machines, monitoring network packet transfers, and tracking storage array capacities.
Event Management
Systems generate thousands of operational events every minute. Event management involves capturing these status changes, filtering out meaningless noise, and logging meaningful alerts for the engineering team.
Incident Response
When an asset fails or a service degrades, incident response begins. This is the structural lifecycle of acknowledging a ticket, triaging the failure, finding the cause, and deploying a patch to restore standard service levels.
Performance Optimization
Performance management ensures applications run efficiently. Teams monitor application response times, database query execution speeds, and memory allocation to prevent latency spikes for the end user.
Capacity Planning
Engineers analyze compute use trends over long periods to forecast when the business will need to purchase more hardware or allocate additional cloud budget.
Service Reliability
Reliability engineering balances speed and stability. It tracks system performance against internal targets to guarantee applications remain stable and accessible to customers.
5. The Role of AI in Modern IT Operations
AI improves baseline IT functions by replacing manual processes with scalable, algorithmic decision-making.
Intelligent Monitoring
Traditional monitoring uses fixed alert thresholds, such as flagging a server when CPU use hits 85%. However, this rule fails if a server normally runs at 90% during Friday afternoon batch processing. AI looks at historical data to build dynamic baselines, recognizing that 90% on Friday is fine, but 90% on Sunday morning indicates a major issue.
Event Correlation
When a core network switch drops offline, hundreds of downstream servers will throw errors simultaneously. This creates an “alert storm” that floods engineers with notifications. AI groups these related alerts into a single incident, showing that the switch failure caused the secondary server alerts.
Anomaly Detection
Machine learning algorithms monitor streaming data to find unusual patterns that do not match standard operations. For example, if an internal API suddenly sees an uncommon influx of requests from a rare geographic region, the AI flags this behavior immediately for security evaluation.
Predictive Analytics
By evaluating historical consumption metrics, predictive IT operations forecast exactly when storage arrays will fill up.
Storage Capacity (%)
100% | / [Predicted Exhaustion Point]
80% | /
60% | / ─ ─ ─ ─
40% | / ─ ─ ─ ─ ┘
20% | ─ ─ ─ ─ ─ ─┘
└──────────────────────────────────────────► Time
Instead of alerting teams when a disk is 99% full, the system warns them three weeks in advance that a specific log directory is growing too fast.
Automated Root Cause Analysis
When an outage happens, the AI model reviews log files, configuration changes, and code updates across the entire infrastructure stack. It pinpoints the exact change that triggered the failure, reducing troubleshooting time from hours to seconds.
Intelligent Incident Response
AI automatically routes incoming incident tickets to the exact engineering team best suited to fix the problem. It looks at the issue text, finds the responsible microservice, checks historical shift schedules, and assigns the ticket with recommended troubleshooting steps.
Self-Healing Infrastructure
When a known, repeatable issue occurs—like an application running out of memory—the AI engine triggers an automated script to spin up a fresh container instance and safely drain traffic away from the failing host. This resolves the issue without requiring an engineer to wake up in the middle of the night.
6. AIOpsSchool.com Guide to AI in Modern IT Operations
Implementing AI requires a structured approach to learning and deployment. This guide breaks down the essential steps for successfully adopting enterprise AIOps.
Building Intelligent IT Operations
Begin by centralizing your telemetry data into a unified platform. Machine learning models require clean, un-siloed logs, metrics, and traces to generate accurate predictions.
Improving Service Reliability
Use machine learning models to track your system stability metrics. Shift your focus from fixing broken servers to proactively tracking early signs of performance degradation.
Automating Operational Workflows
Identify your top five most common manual alerts. Build automated response playbooks that allow your AI platform to trigger remediation scripts automatically when those specific alerts occur.
Reducing Operational Complexity
Reduce alert noise by turning on algorithmic event deduplication. Group redundant alerts together so your on-call engineers can focus on fixing problems instead of clearing identical notifications.
Preparing for Enterprise AIOps Adoption
Prepare your organization for change by upskilling your workforce. Use educational platforms like AIOpsSchool.com to train traditional system administrators in data analysis, model retraining, and modern observability frameworks.
7. Benefits of AI in IT Operations
- Faster Incident Detection: Machine learning spots micro-anomalies and early system degradation long before traditional monitoring thresholds trip.
- Reduced Downtime: Automated root cause analysis and self-healing scripts resolve technical issues quickly, keeping consumer-facing systems online.
- Better Resource Utilization: Predictive analytics prevent over-provisioning, allowing teams to scale down idle cloud nodes and reduce infrastructure spending.
- Improved Customer Experience: Catching bugs and performance slow-downs before they affect production keeps application interfaces fast and responsive.
- Increased Operational Efficiency: Shifting Tier-1 triage to automated platforms frees engineers to focus on building new features instead of fixing routine bugs.
- Smarter Decision-Making: Executive teams gain access to clean, long-term performance trends and capacity forecasts, removing guesswork from budget planning.
8. Real-World Industry Applications
Banking and Financial Services
A global retail bank uses AI-powered IT management to monitor its payment processing gateways. The AI engine spots microsecond anomalies in transactional latency, automatically routing traffic away from failing cloud zones to prevent interrupted ATM or credit card transactions.
Healthcare
Hospital networks deploy AI for IT operations to protect electronic health record platforms. If an underlying database cluster experiences unusual access delays, the AI system fixes the issue automatically, ensuring doctors can access patient charts without delay during critical procedures.
Telecommunications
Telecom operators use enterprise AIOps to monitor thousands of cell towers. The system predicts hardware failures based on temperature readings and weather patterns, scheduling maintenance crews before local communities lose cellular coverage.
E-Commerce
Digital retailers rely on intelligent IT operations during major holiday shopping rushes. The AI engine predicts capacity demands by looking at real-time checkout metrics, automatically scaling web servers to prevent slow loading times or dropped carts during high-traffic sales events.
Manufacturing
Smart factories connect their assembly line control systems to AI monitoring platforms. The software tracks IoT gateway performance data, isolating network drops that could stop automated assembly machinery.
Cloud Service Providers
Large-scale hosting companies use AI infrastructure management to rebalance workloads across global data centers. The platform shifts virtual machines away from aging server racks onto optimal hardware with zero service interruption.
9. Traditional IT Operations vs. AI-Powered IT Operations
| Feature | Traditional IT Operations | AI-Powered IT Operations |
| Monitoring | Manual dashboards and static thresholds | Intelligent observability across all data streams |
| Event Analysis | Rule-based filtering that requires constant tuning | AI-driven correlation of related events |
| Incident Detection | Reactive alerts sent after a system fails | Predictive modeling that spots early issues |
| Root Cause Analysis | Manual log digging and emergency war rooms | Automated insights pointing to the exact cause |
| Automation | Limited to basic, hardcoded scripts | Intelligent workflow automation that adapts to context |
10. Common Challenges
Legacy Infrastructure
Older monolithic applications often lack the modern API hooks needed to stream high-quality telemetry data out to AI engines.
Recommendation: Wrap legacy applications in modern exporter tools or collect system-level metrics via lightweight host agents to gather useful telemetry without rewriting core code.
Data Quality Issues
Machine learning models produce inaccurate results if they are trained on incomplete, messy, or siloed log collections.
Recommendation: Standardize data collection formats across all development teams before training your AI models.
Tool Integration
Enterprises often use multiple isolated monitoring systems that refuse to share telemetry with a centralized AI collector.
Recommendation: Deploy a central observability plane that integrates with existing platforms via standard webhooks and open APIs.
Skills Gap
Traditional IT teams frequently lack the data science and automation skills required to manage machine learning models.
Recommendation: Use structured training sites like AIOpsSchool.com to train your engineers in basic scripting, model tuning, and automated workflows.
Organizational Change
Engineers are sometimes hesitant to trust automated scripts to make changes to live production infrastructure.
Recommendation: Start by running your AI system in “advisory mode,” where it suggests fixes for human approval. Once it builds trust, you can safely turn on automated resolution.
11. Best Practices
- Build centralized observability: Bring all logs, infrastructure metrics, and traces into a single platform so your AI models have full visibility into the environment.
- Automate repetitive IT operations: Start by automating low-risk, frequent tasks—such as clearing disk space or restarting frozen background services—before moving to complex tasks.
- Continuously monitor AI performance: Regularly review your machine learning models to ensure they adapt as your underlying application code and architecture change.
- Improve collaboration across teams: Break down the walls between development, security, and operations groups so everyone works from the same AI-driven data.
- Measure operational outcomes regularly: Track concrete business metrics, like reduced incident counts and dollar savings from cloud efficiency, to prove the value of your AIOps investment.
12. Key Performance Metrics
Mean Time to Detect (MTTD)
The average number of minutes it takes an operational team to notice a system failure after it begins. AI lowers this metric significantly by recognizing anomalies before they trigger standard customer complaints.
Mean Time to Resolve (MTTR)
The average duration from when an incident is first logged until the system returns to normal operations. Automated root cause diagnosis drastically cuts down this timeline.
Incident Reduction Rate
The percentage drop in total open trouble tickets achieved by deduplicating redundant alerts and grouping related events together.
Service Availability
The overall uptime percentage of core business systems. AI helps teams meet their service level agreements by identifying and preventing risks early.
Alert Accuracy
The ratio of actionable alerts to total notifications received. High alert accuracy means fewer false alarms and less alert fatigue for engineers.
Automation Success Rate
The percentage of alerts successfully resolved by automated playbooks without requiring any manual human intervention.
13. Career Opportunities
- AIOps Engineer: Focuses on designing, building, and maintaining machine learning pipelines dedicated to monitoring enterprise infrastructure data.
- IT Operations Engineer: Keeps infrastructure stable by using AI dashboards to track system health and manage daily deployments.
- Site Reliability Engineer: Combines software engineering with system operations to build resilient, automated cloud infrastructure.
- Cloud Operations Engineer: Manages dynamic cloud environments, using machine learning tools to optimize compute costs and resource allocation.
- DevOps Engineer: Coordinates development and operations workflows, embedding automated testing and AI monitoring directly into the software release cycle.
- Observability Engineer: Designs data paths and collection agents across enterprise systems to provide clean data streams for AI platforms.
14. Future of AI in IT Operations
The future point of enterprise technology is fully autonomous IT operations. We are moving away from dashboards that require human monitoring toward self-directed platforms that maintain their own system health targets.
Next-generation AIOps platforms will integrate deeply with large language models, allowing engineers to query complex cluster behaviors using simple conversational English.
AI-driven observability will expand to automatically optimize application code in real time, tweaking configuration settings on the fly to maximize efficiency.
As self-healing infrastructure matures, systems will automatically spot and patch security vulnerabilities and misconfigurations without requiring manual review.
Hyperautomation will connect business data directly with infrastructure operations, allowing systems to dynamically provision global data center resources ahead of major marketing campaigns.
15. Common Misconceptions
AI Will Replace IT Professionals
AI shifts the nature of IT work rather than eliminating it. The technology handles repetitive triage, allowing human engineers to focus on higher-level architecture design and system optimization.
AIOps Is Only for Large Enterprises
While large corporations pioneered the space, mid-sized businesses can easily adopt modular, cloud-based AI monitoring tools to scale their support operations without massively expanding their engineering headcount.
AI Solves Every IT Problem Automatically
An AI tool is only as good as the infrastructure data it receives. If underlying tracking setups are poorly configured, the machine learning models will output inaccurate recommendations.
Automation Eliminates Human Oversight
Automated guardrails and policies are designed by humans. High-risk actions still require engineering approval, keeping humans firmly in control of critical deployment decisions.
16. FAQ Section
- What is the difference between traditional monitoring and AIOps?
Traditional monitoring uses fixed, manual thresholds to alert teams after a system fails. AIOps uses machine learning to dynamically learn normal system behavior, group related alerts together, and predict potential failures before they affect users. - How does AI help reduce alert fatigue for DevOps teams?
AI analyzes thousands of raw incoming system events and automatically deduplicates redundant alerts. It groups related issues into a single actionable incident, stopping downstream “alert storms” from flooding engineers’ inboxes. - Can small businesses benefit from using AI in IT operations?
Yes, small businesses can use modern cloud-based AI tools to scale their operations. These platforms handle routine system monitoring and automated triage, allowing small teams to manage complex cloud footprints without hiring an army of administrators. - What types of data does an AIOps platform collect?
AIOps engines ingest three main types of data: log files (system history records), metrics (real-time performance data like CPU or memory usage), and traces (the end-to-end path a request takes through microservices). - Will implementing AI in IT operations require replacing our existing monitoring tools?
No, you do not need to replace your current setup. Most enterprise AIOps platforms act as a central intelligence layer, connecting to your existing monitoring tools via APIs and webhooks to consolidate data into a single pane of glass. - What is automated root cause analysis?
Automated root cause analysis is a feature where the AI engine instantly reviews system logs, configuration changes, and deployment histories during an outage. It isolates the exact change that triggered the failure, saving engineers from hours of manual troubleshooting. - How does self-healing infrastructure work in practice?
When an AI platform spots a familiar, predictable issue—like an app server running out of memory—it triggers a pre-built automation script. The script safely spins up a new server instance and shuts down the old one, resolving the issue without manual intervention. - What skills do engineers need to learn to remain competitive in an AIOps world?
Engineers should focus on building skills in data engineering, telemetry collection standards, basic Python scripting, and automation workflow design. Learning resources like AIOpsSchool.com provide great structured training pathways for these skills. - How does machine learning predict future IT infrastructure capacity needs?
The AI reviews long-term compute, memory, and storage utilization trends. By identifying growth patterns and business cycles, it projects exactly when you will run out of space, allowing you to plan your infrastructure budgets accurately. - Is human approval still required when using automated IT systems?
Yes, human oversight remains vital. While routine fixes can be fully automated, high-risk actions—like altering core database structures or modifying global routing tables—are typically configured to require an engineer’s sign-off.
Final Summary
The role of AI in modern IT operations is transforming infrastructure management from a reactive, firefighting chore into a proactive, predictable business asset. By combining intelligent observability, automated root cause analysis, and self-healing systems, AIOps allows engineering teams to keep up with the scale of modern cloud-native systems. As systems grow more complex, success will belong to organizations that move away from manual monitoring and embrace algorithmic automation. Keeping your skills sharp and understanding these modern automation frameworks is essential for anyone working in enterprise technology today.