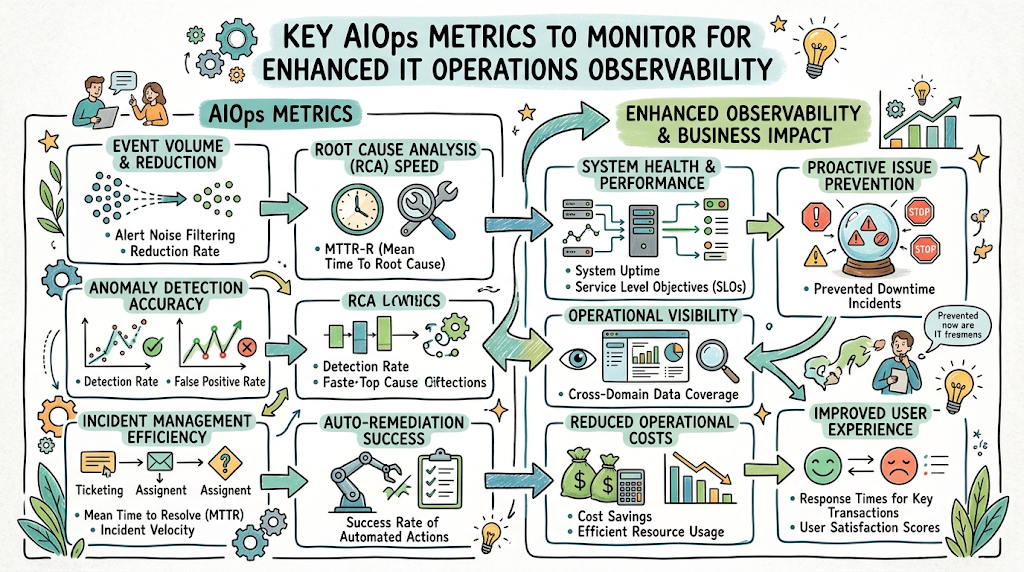
Introduction
Modern enterprise IT environments are expanding at a breakneck pace. Microservices architectures, multi-cloud deployments, and ephemeral Kubernetes clusters generate hundreds of thousands of data points every second. For IT operations teams, managing this scale manually has become impossible. This is where Artificial Intelligence for IT Operations shifts the paradigm. By applying machine learning, mathematical pattern recognition, and statistical modeling to operational data, systems can learn what normal behavior looks like without human intervention. To build a truly resilient, automated infrastructure, teams must shift from basic telemetry aggregation to intelligent data analysis. Understanding and tracking the right foundational data points is the first step toward operational maturity. For comprehensive training on these methodologies, AIOpsSchool provides deep-dive educational tracks designed to help engineers master modern enterprise observability.
What Are AIOps Metrics?
In modern enterprise architectures, operational tracking data is the fundamental unit of observational intelligence. Unlike raw events or textual system messages, these numerical values represent quantitative measurements gathered over uniform intervals of time. They act as the vital signs of your digital ecosystem, tracking resource consumption, system velocity, and error rates.
To understand their unique value, we must differentiate them from other core observability pillars: logs and traces.
- Logs: These are discrete, text-based records of specific events that occurred at a precise point in time. A log entry tells you exactly what happened, such as a database connection timeout or a failed user login attempt. However, logs are computationally expensive to store and index at scale.
- Traces: These map the end-to-end journey of a single request as it travels through a distributed system of microservices. Traces show the continuous execution path and isolate precisely where a delay or failure occurred along a complex chain of internal components.
- Metrics: These provide a continuous, high-level structural overview of system performance over time. Because they are structured numerical data points, they are incredibly efficient to store, aggregate, and analyze mathematically. While a log records a singular system error, a metric measures the overall frequency of those errors per second across a ten-minute window.
An intelligent processing framework ingests these continuous numeric streams and passes them through statistical machine learning models. Instead of looking at a data point in isolation, the system evaluates it against historical patterns, behavioral baselines, and cross-component dependencies. By doing so, the platform transforms raw numerical telemetry into predictive insights and actionable incident contexts.
In Simple Terms:
Think of your IT infrastructure as a human body. A log is a specific record of an event, like a cough. A trace is a detailed medical scan showing how food moves through the digestive system. A metric is a continuous vital sign like heart rate or blood pressure, showing the overall state of health at any given moment.
Key Takeaways
- Metrics provide the computational foundation for mathematical baseline modeling and scalable anomaly detection.
- While logs detail specific events and traces map distributed paths, metrics track continuous system health efficiently.
- Advanced operational tools process numerical streams to understand historical normality and uncover hidden architectural dependencies.
Infrastructure Performance Metrics
CPU Utilization
- Definition: The percentage of an infrastructure compute node’s processing capacity that is currently being executed by the operating system and running applications.
- Why it Matters: Computing power is the core engine of any digital workload. Uncontrolled spikes in compute consumption mean a system is running out of processing headroom, which rapidly leads to application degradation and cascading system failures.
- Real-World Example: During an enterprise end-of-month financial reconciliation, an unoptimized database query forces a multi-core processor to run at 99% capacity for hours, blocking all incoming customer transactions.
- Common Problem When Ignored: Extreme system lag, unresponsive user interfaces, and the complete freezing of the underlying operating system kernel.
- How AIOps Helps Solve It: Machine learning models track historical seasonality to differentiate between a normal, predictable batch-processing compute spike and an irregular, anomalous consumption pattern caused by a runaway code loop.
Memory Usage
- Definition: The amount of random-access memory (RAM) consumed by active system processes, measured as a percentage of total available volatile storage.
- Why it Matters: Applications require dedicated volatile memory blocks to execute instructions and hold temporary data structures. If memory is entirely depleted, operating systems will forcibly terminate running processes to save the system from crashing.
- Real-World Example: A newly deployed microservice contains a software bug that reserves memory space but fails to release it back to the operating system after processing a request.
- Common Problem When Ignored: The Linux Out-of-Memory killer activates, randomly terminating critical background application components and causing sudden, unexplained service outages.
- How AIOps Helps Solve It: Linear regression algorithms analyze the long-term trend line of memory consumption, detecting slow, subtle memory leaks weeks before they reach critical system thresholds.
Disk Performance
- Definition: The evaluation of storage sub-system efficiency, measured through Input/Output Operations Per Second (IOPS), read/write throughput, and disk queue length.
- Why it Matters: Applications must constantly read data from and write data to persistent storage. If the storage subsystem becomes a bottleneck, the entire application stack stalls while waiting for data operations to complete.
- Real-World Example: An enterprise analytics tool attempts to write millions of small logs to a standard hard drive array, completely saturating the disk’s input capability and stalling user logins.
- Common Problem When Ignored: Severe application timeout errors, corrupted data blocks, and complete transactional backlogs across the entire architecture.
- How AIOps Helps Solve It: Multivariate correlation engines connect spikes in disk queue lengths with concurrent application response delays, proving that storage degradation is the true root cause of a poor user experience.
Network Throughput
- Definition: The total volume of digital data successfully transmitted across a network interface over a specified period, typically calculated in gigabits per second.
- Why it Matters: Digital systems depend entirely on data exchange. If network traffic approaches the physical limits of the infrastructure routing hardware, data packets begin to back up, restricting overall system capacity.
- Real-World Example: A backup automation script misfires during peak business hours, attempting to transfer multi-terabyte database copies across the primary corporate network backbone.
- Common Problem When Ignored: Saturated data pipelines, dropped connections, and the inability of external users to access hosted services.
- How AIOps Helps Solve It: Historical baseline models automatically learn the normal data distribution schedules of an enterprise, instantly flagging unusual outbound data movements that could indicate a massive data exfiltration security breach.
Network Latency
- Definition: The time delay measured in milliseconds for a data packet to travel from its source destination to its target across a network path and return.
- Why it Matters: High data transmission delays directly degrade application performance, especially in modern distributed microservice architectures where a single user click requires dozens of internal network calls.
- Real-World Example: A physical fiber-optic telecommunications line is damaged, forcing network traffic to reroute along a longer, less efficient backup path across continents.
- Common Problem When Ignored: Slow webpage loading speeds, broken API connections, and broken real-time data syncs between distributed database nodes.
- How AIOps Helps Solve It: Network topology mapping engines automatically correlate localized latency spikes with downstream application delays, showing engineers exactly which physical or virtual network segment is causing the problem.
In Simple Terms:
Monitoring infrastructure performance is like keeping an eye on a delivery truck. CPU is how hard the engine is working, memory is the size of the truck bed, disk performance is how fast you can load and unload packages, throughput is the number of trucks on the road, and latency is the time it takes a single truck to complete its round trip.
Key Takeaways
- Infrastructure telemetry tracks the physical and virtual resource limits of computing systems.
- Ignoring low-level hardware or virtualization metrics leads directly to catastrophic OS level panics and service drops.
- Advanced analytics replaces static infrastructure thresholds with dynamic baselines that adjust for natural traffic patterns.
Application Performance Metrics
Modern application performance monitoring focuses on understanding the internal health of software execution stacks. These metrics directly reflect the stability of the digital products your customers interact with.
| Metric | Primary Operational Focus | Target Enterprise Threshold |
| Response Time | Measures total end-to-end transaction duration from user to backend and back. | Less than 200 milliseconds for standard web transactions. |
| Request Latency | Tracks server-side processing delays isolated from network transit time. | Less than 50 milliseconds for internal microservice APIs. |
| Throughput | Quantifies total transaction volume or requests processed per second (RPS). | Variable based on infrastructure size and peak historical load. |
| Error Rate | Measures percentage of failed requests relative to total incoming traffic. | Hard operational target of less than 0.01% of all calls. |
| Transaction Success Rate | Tracks successful business outcomes, like completed checkouts. | Closely aligned to 100% execution for critical monetary pipelines. |
Response Time
To analyze application response time through an analytical lens, let us break down its operational lifecycle:
- Definition: The total duration of time elapsed between a user initiating an digital action and the application delivering the complete visual result back to the client interface.
- Why it Matters: This is the primary indicator of user experience. When response times swell, users abandon platforms, conversion rates plummet, and business revenue drops.
- Real-World Example: An enterprise human resources platform takes 14 seconds to load the employee directory page during morning login hours, frustrating staff and stalling internal operations.
- Common Problem When Ignored: Massive drops in user retention, negative brand perception, and an influx of low-priority support tickets that overwhelm helpdesk teams.
- How AIOps Helps Solve It: Distributed tracing analytics engines automatically break down the total response time into component segments, instantly pinpointing whether the delay is caused by slow database queries, unoptimized application code, or third-party API dependencies.
Request Latency
- Definition: The precise time window a hosting application server spends processing a specific backend computational request, excluding external network transit delays.
- Why it Matters: In microservice frameworks, a single user click can trigger a chain of dozens of synchronous service-to-service calls. If one internal service adds even small latency delays, it ripples down the line, stalling the entire application.
- Real-World Example: An authentication microservice takes 800 milliseconds to validate user credentials because it uses an inefficient cryptographic hashing implementation.
- Common Problem When Ignored: Thread exhaustion on application web servers, where all available workers are locked up waiting for stalled microservices to respond.
- How AIOps Helps Solve It: Graph-based dependency algorithms automatically build a living map of microservice interactions, highlighting the exact node in the call chain responsible for causing upstream latency amplification.
Throughput
- Definition: The total number of application requests, transactions, or operational data units processed by a system within a specific time increment, typically expressed as Requests Per Second (RPS).
- Why it Matters: Throughput validates the total load processing capacity of your application. A sudden, unexpected drop in throughput often indicates an upstream blocking error or a major network access failure.
- Real-World Example: A media streaming site experiences a sudden drop from 50000 requests per second to 1000 requests per second immediately following a faulty code deployment.
- Common Problem When Ignored: Unnoticed service disconnects where systems appear online because error rates are low, but they are actually completely inaccessible to external traffic.
- How AIOps Helps Solve It: Seasonality-aware forecasting models continuously project expected throughput based on historical days and times, triggering an immediate alert the moment actual traffic drops below statistical expectations.
Error Rate
- Definition: The mathematical percentage of failed application calls or HTTP error status responses (such as 5xx server errors) relative to the total volume of incoming requests.
- Why it Matters: Errors represent broken software functionality. High error rates mean your application is failing to perform its core business duties, directly breaking user workflows.
- Real-World Example: A banking application introduces an database schema mismatch, causing 35% of transfer fund attempts to fail with internal server errors.
- Common Problem When Ignored: Total failure of business operations, widespread data corruption, and severe breaches of customer service agreements.
- How AIOps Helps Solve It: Clustering algorithms analyze thousands of raw error logs, grouping them into distinct root cause patterns so engineers see a single clean alert explaining the core issue rather than thousands of raw stack traces.
Transaction Success Rate
- Definition: The ratio of business-critical workflows completed successfully without technical interruptions, compared to the total number of initiated workflows.
- Why it Matters: This metric bridges the gap between pure technical telemetry and business realities, focusing directly on the successful execution of critical user journeys.
- Real-World Example: An airline website experiences a technical issue where users can browse flights and add items to their carts, but the final payment gateway fails during credit card authorization.
- Common Problem When Ignored: Severe financial loss, abandoned checkout carts, and an inability to detect silent application failures that do not throw explicit system errors.
- How AIOps Helps Solve It: Business-to-technical correlation engines map technical performance metrics directly to business outcomes, automatically alerting operations teams when checkout completions drop even if underlying servers report normal health.
In Simple Terms:
Tracking application performance is like running a busy restaurant kitchen. Response time is how long a guest waits for their food, latency is the time the chef spends prepping a single dish, throughput is the total number of meals served per hour, error rate is the percentage of burned dishes sent back, and transaction success rate is the number of customers who happily pay for their meal.
Key Takeaways
- Application tracking data measures the direct software execution efficiency experienced by the end-user.
- High response times and internal latency create cascading failures in modern microservice architectures.
- Intelligent diagnostic systems automatically trace distributed software execution paths to separate application bugs from underlying hardware resource limits.
Incident Management Metrics
Incident management focuses on how efficiently an enterprise IT team detects, acknowledges, investigates, and remedies unexpected operational outages.
Mean Time to Detect (MTTD)
- Definition: The average duration of time that elapses from the exact moment an operational anomaly or outage occurs in the infrastructure to the moment the organization’s monitoring platform flags the problem.
- Why it Matters: You cannot fix a problem you do not know exists. A high detection time means systems are degraded for long periods before engineers even begin investigating, compounding business damage.
- Real-World Example: A hard disk failure occurs on a critical database server at midnight, but the legacy monitoring platform fails to trigger an alarm until a human operator checks a dashboard at 7:00 AM.
- Common Problem When Ignored: Prolonged, silent outages that severely damage brand reputation and result in clients discovering system failures before the internal engineering team does.
- How AIOps Helps Solve It: Unsupervised anomaly detection algorithms continuously analyze system data in real time, reducing detection delays from hours to seconds by catching early structural indicators of failure.
Mean Time to Acknowledge (MTTA)
- Definition: The average time window between the monitoring platform generating an incident alert and an on-call engineer explicitly claiming ownership of that alert to begin resolution.
- Why it Matters: Even instantaneous detection is useless if alerts sit ignored in an inbox. High acknowledgment times indicate alert fatigue, broken paging workflows, or an engineering team overwhelmed by noise.
- Real-World Example: An on-call engineer receives 80 automated alert pages during their shift, misses a critical database failure notification because it looks identical to low-priority alerts, and delays response by 45 minutes.
- Common Problem When Ignored: Incidents remain unaddressed, escalations stall, and critical recovery time is lost while severe issues sit unattended in unmonitored queues.
- How AIOps Helps Solve It: Intelligent alert routing and escalation systems automatically deduplicate related alerts, categorize incident severity with high accuracy, and directly page the exact on-call specialist needed, dramatically shortening acknowledgment windows.
Mean Time to Resolve (MTTR)
- Definition: The average time it takes an IT organization to successfully repair a degraded system and restore full, normal operational service after an incident has been officially detected.
- Why it Matters: This is the ultimate metric for measuring operational resilience. Every single minute spent in resolution phase directly increases downtime costs and compounds user frustration.
- Real-World Example: A massive cloud infrastructure outage knocks an enterprise logistics platform offline, requiring five hours of manual log parsing across fifty servers to find a corrupted configuration file.
- Common Problem When Ignored: Extended outages, severe financial penalties from missing availability agreements, and major customer churn.
- How AIOps Helps Solve It: Automated root cause analysis engines instantly correlate timelines across layers, suggesting the exact broken file or deployment step responsible for the outage, while automated runbooks trigger self-healing scripts to restore service immediately.
+---------------------------------------------------------------------------------------+
| INCIDENT LIFECYCLE TIMELINE |
+---------------------------------------------------------------------------------------+
| |
| Incident Occurs Alert Triggered Engineer Responds Restored |
| │ │ │ │ |
| ▼ ▼ ▼ ▼ |
| ├───────────────────────────┼───────────────────────────┼──────────────────┤ |
| │◄────────── MTTD ─────────►│◄────────── MTTA ─────────►│◄───── MTTR ─────►│ |
| │ │ |
| └────────────────────────────── Total Downtime ───────────────────────────┘ |
+---------------------------------------------------------------------------------------+
Incident Frequency
- Definition: The total volume of discrete, service-disrupting incidents that occur within a specified tracking window, such as weekly or monthly.
- Why it Matters: High incident volume indicates unstable software, unreliable underlying infrastructure, or poor engineering deployment standards. It drains team morale and stalls product innovation.
- Real-World Example: A software company rolls out daily code deployments without automated testing, leading to fifteen distinct production outages over a single month.
- Common Problem When Ignored: Engineering teams burn out completely from constant on-call firefighting, leaving zero time for valuable architectural improvements or feature work.
- How AIOps Helps Solve It: Predictive trend analysis engines monitor cross-system health scores, highlighting unstable architectural components before they fail so platform teams can proactively reinforce weak links.
Recurring Incidents
- Definition: The total count of identical or closely related operational incidents that happen repeatedly over time due to a failure to address the true root cause.
- Why it Matters: Experiencing the exact same failure repeatedly means an organization is applying temporary fixes rather than solving underlying architectural problems, wasting engineering hours and indicating a weak root cause analysis process.
- Real-World Example: A server constantly crashes due to disk space exhaustion. The operations team manually clears temporary files every three days to temporarily fix the issue, but never investigates why the files are accumulating so quickly.
- Common Problem When Ignored: Long-term architectural degradation, complete loss of trust from stakeholders, and inefficient use of engineering talent on easily preventable tasks.
- How AIOps Helps Solve It: Machine learning text-clustering models match incoming incident signatures against historical post-mortem records, alerting the team that a current outage is an exact match to a past event and pointing them directly to the permanent architectural solution.
In Simple Terms:
Response tracking is like an emergency medical response. MTTD is how fast the hospital learns a patient is hurt, MTTA is how long it takes an ambulance crew to accept the call, MTTR is the time spent treating the patient until they are well, incident frequency is how often people get hurt, and recurring incidents are how often the same person returns with the exact same injury because the underlying health issue was never truly resolved.
Key Takeaways
- Incident response performance determines the actual business cost and duration of system outages.
- High MTTR is almost always driven by long root cause investigation windows, not the time it takes to apply a fix.
- Intelligent automation cuts down resolution times by instantly identifying the true root cause and executing automated recovery steps.
Alert and Event Intelligence Metrics
Modern operations centers are flooded with automated notifications. Alert intelligence metrics help measure a team’s ability to filter out distracting noise and focus exclusively on genuine infrastructure emergencies.
Alert Volume
- Definition: The total number of raw, unfiltered alert notifications generated by an infrastructure monitoring ecosystem across a given timeframe.
- Why it Matters: High alert volume creates cognitive overload. When monitoring systems send tens of thousands of notifications daily, human engineers lose the ability to effectively process information.
- Real-World Example: A massive enterprise network environment generates 85000 individual system alerts over a single 24-hour period, overwhelming the center’s dashboard displays.
- Common Problem When Ignored: Complete paralysis of operational teams, missed system critical failures, and a breakdown of response protocols.
- How AIOps Helps Solve It: Event deduplication engines automatically intercept raw notification streams at the ingestion layer, grouping thousands of redundant alerts into clean, manageable operational events.
Alert Noise Ratio
- Definition: The mathematical proportion of low-priority, redundant, or unactionable alert notifications compared to the total volume of alerts generated by the system.
- Why it Matters: This metric evaluates the signal-to-noise ratio of your monitoring strategy. A high noise ratio means your engineering team spends valuable time acknowledging notifications that require no action.
- Real-World Example: An operations center discovers that 92% of their daily alerts are simple warnings about brief CPU spikes that resolve themselves without intervention.
- Common Problem When Ignored: Severe alert fatigue, where exhausted engineers begin ignoring critical production notifications because they assume they are just more harmless noise.
- How AIOps Helps Solve It: Intelligent scoring engines analyze how engineers interact with past notifications, automatically lowering the priority of or silencing alerts that historical workflows prove require no human response.
False Positive Rate
- Definition: The mathematical percentage of generated alerts that indicate a system failure or anomaly when the underlying application or infrastructure is actually operating perfectly normally.
- Why it Matters: False alarms waste valuable engineering hours, disrupt sleep schedules for on-call personnel, and erode trust in the monitoring tools themselves.
- Real-World Example: A legacy monitoring tool fires a critical alert because a server’s disk space hits 90%, but the disk is actually dedicated to a secure, fixed-size database that will never expand further.
- Common Problem When Ignored: Engineers lose faith in the monitoring system entirely, often disabling alerts manually and leaving systems unprotected against real failures.
- How AIOps Helps Solve It: Dynamic baseline models learn the unique operational context of every system component, replacing rigid static thresholds with flexible, context-aware boundaries that significantly reduce false alarms.
+---------------------------------------------------------------------------------------+
| INTELLIGENT ALERT SUPPRESSION |
+---------------------------------------------------------------------------------------+
| |
| [ Raw Alert Stream ] ──► 10,000 Unfiltered Alerts / Hour |
| │ |
| ▼ |
| ┌─────────────────────────────┐ |
| │ AIOps Correlation Engine │ |
| └─────────────────────────────┘ |
| │ |
| ┌───────────────────────┴───────────────────────┐ |
| ▼ ▼ |
| [ Suppressed Noise ] [ Actionable Incidents ] |
| 9,950 Duplicate / Informational Alerts 5 Context-Rich Events Paged |
| |
+---------------------------------------------------------------------------------------+
Event Correlation Accuracy
- Definition: The percentage of instances where an intelligent event engine correctly groups separate, distributed alert notifications into a single, cohesive incident ticket based on structural relationships.
- Why it Matters: High correlation accuracy ensures that instead of seeing hundreds of separate issues across network, database, and application layers, teams see one single problem timeline.
- Real-World Example: A core network switch fails, causing 40 downstream servers to lose connectivity. The correlation engine successfully groups all 40 resulting server alerts under the single switch failure incident.
- Common Problem When Ignored: Multiple engineering teams waste time investigating the same root cause independently from different angles, creating confusion and delaying recovery.
- How AIOps Helps Solve It: Advanced graph neural networks and time-series clustering models analyze topology maps and historical alert sequences to maximize correlation accuracy and keep response teams aligned.
Alert Suppression Efficiency
- Definition: The percentage of redundant, non-actionable, or duplicate notifications that are automatically filtered out and silenced by the platform before they can reach an engineer.
- Why it Matters: This metric tracks the efficiency of your automated filtering layers. Higher suppression efficiency directly correlates with a quieter, more focused operations center.
- Real-World Example: During a major database migration, an automated rule silences 1500 expected downstream replication delay warnings, preventing on-call engineers from being overwhelmed by non-urgent alerts.
- Common Problem When Ignored: Severe system alerts get lost in a sea of routine, low-priority informational updates, delaying response to actual emergencies.
- How AIOps Helps Solve It: Automated policy engines continuously evaluate real-time infrastructure conditions, dynamically suppressing entire classes of downstream alerts when a known upstream root cause event is already being actively resolved.
In Simple Terms:
Alert intelligence is like a home security system. Alert volume is every single sound detected by the system, noise ratio is the rustling of trees outside, a false positive is the alarm firing because a pet walked past a sensor, correlation accuracy is the system connecting a broken window sensor and a motion sensor into a single break-in event, and suppression efficiency is the system’s ability to automatically ignore the wind so you only wake up for real emergencies.
Key Takeaways
- Alert volume and noise ratios measure the overall efficiency and health of an enterprise operations center.
- Alert fatigue caused by poor thresholds and high false positive rates is a leading cause of missed production outages.
- Advanced event engines use topology data to group thousands of raw alerts into singular, context-rich incident tickets.
Predictive Analytics Metrics
Predictive analytics shifts IT operations from reacting to past failures to proactively identifying and preventing issues before they disrupt services.
Anomaly Detection Accuracy
- Definition: The statistical precision and recall of machine learning algorithms in successfully identifying true behavioral anomalies while ignoring normal, expected performance fluctuations.
- Why it Matters: High anomaly accuracy ensures that operations teams are alerted only to genuinely unusual and potentially dangerous system behaviors, preventing wasted effort on normal operational spikes.
- Real-World Example: A streaming platform experience a 300% traffic surge because a highly anticipated video launches. An accurate anomaly model recognizes this as a valid, expected user trend rather than a malicious attack.
- Common Problem When Ignored: Frequent false alarms during normal business growth or, conversely, a complete failure to detect subtle, slow-moving system failures before they turn into major outages.
- How AIOps Helps Solve It: Unsupervised machine learning algorithms continually update internal mathematical baseline bounds, adjusting for time-of-day, day-of-week, and holiday operational patterns to maximize detection accuracy.
Forecast Accuracy
- Definition: The statistical variance between predicted future system performance trends calculated by machine learning models and the actual measured real-world metrics over that same timeframe.
- Why it Matters: Accurate forecasting allows enterprises to make dependable long-term decisions regarding infrastructure scaling, budget allocation, and system capacity planning.
- Real-World Example: An enterprise resource planning system accurately forecasts that database storage requirements will exceed existing physical capacity in exactly 45 days, giving teams plenty of time to provision resources.
- Common Problem When Ignored: Sudden, critical resource exhaustion outages that force reactive, emergency hardware purchases at premium costs.
- How AIOps Helps Solve It: Autoregressive time-series models analyze long-term operational trends and growth rates, providing highly accurate projections of future infrastructure needs.
Capacity Prediction Metrics
- Definition: Numerical estimates calculated by predictive models that specify the exact number of days remaining until a physical or virtual infrastructure resource (such as disk storage, memory, or network bandwidth) becomes completely exhausted.
- Why it Matters: These metrics replace guesswork with hard data, enabling procurement and platform engineering teams to scale infrastructure proactively and maintain system stability.
- Real-World Example: A cloud storage pool tracks its historical consumption trends to calculate a “Days-to-Exhaustion” metric, warning administrators when storage is projected to run out within 30 days.
- Common Problem When Ignored: Systems crash unexpectedly due to running completely out of storage space, causing prolonged downtime and potential data corruption.
- How AIOps Helps Solve It: Trend analysis and capacity forecasting engines monitor resource utilization patterns, automatically triggering automated infrastructure expansion workflows weeks before storage thresholds are reached.
Risk Prediction Indicators
- Definition: Early warning scores calculated by analyzing patterns across multiple system layers to estimate the mathematical probability of an imminent infrastructure failure or severe performance drop.
- Why it Matters: These risk indicators act as an early warning system for your environment, allowing teams to patch or fix vulnerable infrastructure before users experience any visible service degradation.
- Real-World Example: A complex machine learning model detects a concurrent rise in memory fragmentation, micro-packet loss, and database lock times, generating a high risk score for an enterprise payment gateway.
- Common Problem When Ignored: Teams remain blind to hidden system instabilities, leaving them completely vulnerable to large, unexpected outages that could have been prevented with early intervention.
- How AIOps Helps Solve It: Multivariate pattern matching engines continuously scan your entire infrastructure ecosystem, identifying subtle combinations of minor issues that historically lead to major system failures and alerting engineers to step in early.
In Simple Terms:
Predictive analytics is like advanced weather forecasting for your IT systems. Anomaly detection is realizing a cloud pattern looks unseasonal, forecast accuracy is how well the weather model predicts tomorrow’s rainfall, capacity prediction is estimating how many days of dry weather are left before a reservoir empties, and risk indicators are warnings that atmospheric conditions are perfect for a storm to form.
Key Takeaways
- Predictive indicators allow enterprise IT teams to transform from reactive firefighters into proactive optimization engineers.
- Accurate resource forecasting prevents emergency infrastructure costs by providing clear, early visibility into future storage and compute needs.
- Early risk scoring highlights complex, hidden system instabilities before they can impact end-users.
Cloud & Kubernetes Metrics
Cloud-native architectures and container orchestration systems like Kubernetes introduce dynamic scaling complexities that require highly specialized monitoring metrics.
+---------------------------------------------------------------------------------------+
| KUBERNETES LAYER OBSERVABILITY |
+---------------------------------------------------------------------------------------+
| |
| [ Cluster Availability ] ──► Total Health of All Control Planes & Nodes |
| |
| ├── [ Node Utilization ] ──► Physical Host CPU / RAM Capacity |
| |
| ├── [ Pod Performance ] ──► Grouped Application Allocations |
| |
| └── [ Container Health ] ──► Raw Process Restarts & OOM Drops |
| |
+---------------------------------------------------------------------------------------+
Container Health
- Definition: Telemetry tracking the operational integrity of individual application containers, focusing on restart frequencies, exit codes, and liveness probe failures.
- Why it Matters: Containers are designed to be short-lived, but frequent, unexpected container crashes indicate underlying application bugs, configuration errors, or severe resource constraints.
- Real-World Example: An application container crashes and restarts 150 times in an hour because a database password configuration was entered incorrectly during deployment.
- Common Problem When Ignored: Extended periods of degraded application performance, broken user sessions, and high resource overhead spent constantly restarting broken containers.
- How AIOps Helps Solve It: Root-cause engine models analyze container exit statuses alongside recent deployment logs, immediately flagging the exact configuration error causing a crash loop.
Pod Performance
- Definition: The aggregated evaluation of resource utilization, network health, and storage volumes across a collection of co-located containers managed as a single Kubernetes Pod.
- Why it Matters: In Kubernetes, the Pod is the basic execution unit. Monitoring Pod performance ensures that application groups have the necessary resources to process workloads efficiently.
- Real-World Example: A critical API pod experiences severe internal network throttle issues because it was placed on an over-allocated network route.
- Common Problem When Ignored: Slow API responses, dropped user connections, and localized application outages within specific container groups.
- How AIOps Helps Solve It: Network topology visualization engines map internal pod-to-pod communications, instantly exposing architectural bottlenecks and congested internal network paths.
Node Utilization
- Definition: The combined measurement of compute, memory, and storage usage across a physical or virtual machine host that runs Kubernetes container workloads.
- Why it Matters: If an underlying host node becomes over-allocated, all application pods running on that host will suffer from resource starvation, leading to widespread performance drops.
- Real-World Example: Three host nodes in an enterprise cluster reach 98% memory utilization, forcing Kubernetes to evict multiple critical application pods simultaneously.
- Common Problem When Ignored: Cascading cluster failures, where the collapse of one over-allocated host node overloads remaining nodes, taking down the entire cluster.
- How AIOps Helps Solve It: Predictive load balancing algorithms analyze historical resource trends across nodes, automatically moving pods around to balance workloads before any single node reaches a critical limit.
Auto-Scaling Efficiency
- Definition: The measure of how quickly and accurately a cluster adjusts its running container capacity (scaling up or down) in response to real-time changes in user workload demand.
- Why it Matters: Poor scaling efficiency means either provisioning too few resources (causing performance slowdowns) or provisioning too many (resulting in wasted cloud spend).
- Real-World Example: A retail cluster scales up its container count thirty minutes after a morning traffic peak has already passed, failing to protect users from slowdowns and wasting budget on idle resources.
- Common Problem When Ignored: Severe system lag during sudden traffic spikes, combined with high cloud infrastructure bills from over-provisioning resources during low-traffic periods.
- How AIOps Helps Solve It: Proactive auto-scaling models predict incoming demand changes based on historical traffic patterns, triggering scaling actions ahead of time so infrastructure is ready before the traffic arrives.
Cluster Availability
- Definition: The percentage of time that a Kubernetes cluster’s control planes, API services, and worker nodes are fully functional, responsive, and capable of orchestrating workloads.
- Why it Matters: The cluster is the foundation of your containerized architecture. If the cluster control plane fails, your entire application orchestration ecosystem goes down.
- Real-World Example: A cloud provider experiences an outage in a specific geographic zone, knocking out a cluster’s primary control plane and rendering management APIs inaccessible.
- Common Problem When Ignored: Complete, unrecoverable application downtime across all hosted services, resulting in severe violations of service level agreements.
- How AIOps Helps Solve It: Cross-regional health monitoring engines continuously evaluate control plane response times, automatically rerouting traffic to healthy backup clusters in different zones the moment a core control plane stops responding.
In Simple Terms:
Managing a Kubernetes cluster is like managing a fleet of delivery cargo ships. Container health is checking if individual boxes on a ship are intact, pod performance is evaluating the status of a specific stack of boxes, node utilization is measuring how deep a ship sits in the water from its total cargo weight, auto-scaling efficiency is how fast you can add or remove ships as cargo volume changes, and cluster availability is ensuring the port itself remains open and functional.
Key Takeaways
- Containerized ecosystems require specialized metrics to track the health of highly dynamic, short-lived infrastructure components.
- Host node exhaustion can trigger cascading failures that impact dozens of independent application workloads simultaneously.
- Predictive auto-scaling reduces cloud costs while ensuring systems scale up before user traffic peaks arrive.
Service Reliability Metrics
Service reliability metrics quantify structural system stability using framework indicators that directly align engineering goals with user expectations.
SLA Metrics
- Definition: Service Level Agreements (SLAs) are formal, legally binding commitments made between a technology service provider and an end customer regarding system availability, performance, and operational uptime.
- Why it Matters: Missing SLA targets results in direct financial penalties, legal liabilities, contractual obligations to return service fees, and severe damage to customer relationships.
- Real-World Example: A SaaS enterprise promises 99.9% platform availability per month but suffers a catastrophic seven-hour outage, violating contracts and requiring them to issue financial credits to all clients.
- Common Problem When Ignored: Direct financial loss from penalty fees, legal disputes with major clients, and a decline in market reputation.
- How AIOps Helps Solve It: Real-time risk modeling engines track monthly uptime trends, alerting engineering leadership early when a series of minor issues puts the company at risk of violating customer commitments.
SLO Metrics
- Definition: Service Level Objectives (SLOs) are internal target metrics set by engineering teams to define the acceptable level of performance and reliability a service must maintain.
- Why it Matters: SLOs act as an operational compass for engineering teams, balancing the need to ship new features quickly with the absolute necessity of maintaining system stability.
- Real-World Example: An engineering organization sets an internal target stating that 99.5% of all incoming API requests must return a successful response over a rolling 30-day window.
- Common Problem When Ignored: Development teams continue shipping unstable features without a mechanism to prioritize reliability, leading to long-term system instability.
- How AIOps Helps Solve It: Automated error budget trackers continuously calculate remaining reliability margins, providing clear data on when teams need to freeze new feature deployments and focus exclusively on architectural stabilization.
SLI Metrics
- Definition: Service Level Indicators (SLIs) are the specific, quantitative measurements used to track compliance with an internal Service Level Objective, such as error rates or response latencies.
- Why it Matters: SLIs provide the factual, raw data required to evaluate service health against your reliability targets.
- Real-World Example: An operations team selects the latency of a user profile lookup API as a core indicator, tracking the percentage of requests that complete in under 100 milliseconds.
- Common Problem When Ignored: Teams lack clear, objective metrics to measure performance, leading to subjective arguments about whether a system is truly healthy or degraded.
- How AIOps Helps Solve It: Telemetry aggregation tools automatically calculate and track complex SLIs across thousands of distributed microservices, keeping teams aligned around identical, objective data points.
Service Availability
- Definition: The mathematical percentage of time a system remains fully operational, reachable, and capable of executing its intended functions for end-users over a given period.
- Why it Matters: Availability is the foundation of user trust. If your platform is frequently unavailable, customers will quickly migrate to more reliable competitors.
- Real-World Example: A popular e-commerce storefront maintains 99.99% availability over an entire calendar year, meaning total downtime across the year was limited to less than 53 minutes.
- Common Problem When Ignored: Chronic, unmeasured micro-outages that slowly erode user satisfaction and drive customers away from the platform over time.
- How AIOps Helps Solve It: Distributed global probing engines simulate user workflows from multiple locations around the world, detecting localized availability drops that internal infrastructure dashboards might miss.
User Experience Indicators
- Definition: High-level metrics that evaluate system performance from the direct perspective of the end-user, tracking elements like page load speeds, interface responsiveness, and frontend visual stability.
- Why it Matters: Backend servers can report perfect health even when a broken frontend script prevents users from interacting with an application. These indicators track actual user satisfaction.
- Real-World Example: A mobile application’s backend database is running optimally, but an unoptimized frontend script causes the login button to become completely unclickable on certain devices.
- Common Problem When Ignored: Organizations remain completely blind to client-side application crashes, resulting in poor app store ratings and lost business despite “green” backend infrastructure dashboards.
- How AIOps Helps Solve It: Real-user monitoring engines track real-time client interactions, automatically flagging client-side interface delays or rendering bugs using behavioral anomaly detection.
In Simple Terms:
Reliability metrics are like the performance commitments of a commercial airline. An SLA is the legal contract promising a refund if a flight is canceled, an SLO is the airline’s internal goal to keep 95% of flights on time, an SLI is the actual clock measurement of a specific flight’s arrival time, service availability is the total percentage of scheduled flights that safely fly, and user experience indicators are passenger satisfaction surveys about legroom and meal quality.
Key Takeaways
- Reliability metrics align day-to-day technical operations with commitments made to clients.
- Error budgets provide an objective, data-driven framework for balancing rapid feature development with platform stability.
- Monitoring must include frontend client-side experiences to catch silent application failures that backend systems miss.
Business Impact Metrics
Modern enterprise monitoring bridges the gap between pure technical performance and real-world business outcomes, translating infrastructure health into clear financial impact.
Revenue Impact of Downtime
- Definition: The financial loss calculated per unit of time that an enterprise suffers when its primary transactional platforms are offline or severely degraded.
- Why it Matters: This metric converts abstract technical downtime into clear financial reality, helping leadership make informed decisions about infrastructure security investments and resource allocation.
- Real-World Example: A major digital payment processing platform goes offline for 20 minutes during a peak shopping window, resulting in a direct loss of $400,000 in transaction fee revenue.
- Common Problem When Ignored: IT operations are viewed strictly as an expensive cost center rather than a critical driver of business revenue protection, leading to underfunded infrastructure teams.
- How AIOps Helps Solve It: Financial data integrations combine real-time transactional throughput with application uptime metrics, displaying a live revenue-impact chart on operational dashboards during incidents to help prioritize recovery efforts.
Customer Experience Metrics
- Definition: The quantitative measurement of customer satisfaction during digital interactions, tracked through metrics like customer effort scores, churn rates, and abandoned interactions.
- Why it Matters: Technical performance directly shapes customer loyalty. Slow checkout experiences or frequent application errors drive users to abandon transactions and switch to competitors.
- Real-World Example: A food delivery application experiences a minor 3-second delay on its payment page, causing checkout abandonment rates to spike by 25% over a weekend.
- Common Problem When Ignored: Long-term loss of customers and market share, without a clear understanding of how underlying technical flaws are driving users away.
- How AIOps Helps Solve It: Behavioral analytics models connect customer journey drop-off points directly with underlying microservice performance anomalies, revealing exactly which software delays cause users to leave.
Operational Cost Efficiency
- Definition: The financial optimization of an IT organization, measured by balancing resource utilization costs against total headcount expenses and incident management overhead.
- Why it Matters: High cloud spend and large operations teams can eat into corporate profit margins if infrastructure is managed inefficiently or scaling practices are wasteful.
- Real-World Example: An enterprise cloud deployment leaves thousands of development servers running over weekends, wasting $50,000 monthly on idle infrastructure resources.
- Common Problem When Ignored: Exploding operational budgets, massive resource waste, and an inefficient allocation of capital that reduces corporate profitability.
- How AIOps Helps Solve It: Automated resource optimization tools analyze long-term utilization patterns, automatically downsizing over-provisioned infrastructure and reclaiming idle resources to minimize cloud spend.
In Simple Terms:
Business impact metrics trace how technical health affects corporate finances. Revenue impact is counting the money lost while a store’s registers are broken, customer experience metrics track how many frustrated shoppers leave their carts in the aisles due to long lines, and operational efficiency is ensuring you aren’t paying for electricity to light an empty warehouse overnight.
Key Takeaways
- Correlating technical performance with financial metrics transforms IT monitoring from an operational cost center into a strategic business asset.
- Minor application delays can cause immediate spikes in checkout abandonment and long-term customer churn.
- Automated resource optimization helps enterprises control cloud spend by eliminating over-provisioning and idle infrastructure.
How AIOps Tools Analyze These Metrics
Advanced observability platforms apply automated analytics pipelines to ingest raw telemetry data and transform it into actionable operational intelligence.
+---------------------------------------------------------------------------------------+
| AIOPS DATA PROCESSING PIPELINE |
+---------------------------------------------------------------------------------------+
| |
| [ Ingestion ] ──► Collects multi-source Metrics, Logs, and Traces |
| │ |
| ▼ |
| [ Pattern Matching ] ──► Establishes dynamic mathematical behavior baselines |
| │ |
| ▼ |
| [ Event Correlation ]──► Groups distributed alerts using topology graphs |
| │ |
| ▼ |
| [ Root Cause RCA ] ──► Isolates exact broken components or code lines |
| │ |
| ▼ |
| [ Remediation ] ──► Triggers automated recovery runbooks to restore service |
| |
+---------------------------------------------------------------------------------------+
Step 1: Data Collection
The analytical pipeline begins at the collection layer, where light agents and open APIs pull data from thousands of distributed infrastructure sources. This layer ingests varied inputs like streaming metrics, kernel event codes, and transaction traces, standardizing the format and aligning timelines into a single continuous stream.
Step 2: Pattern Recognition
Once data is standardized, machine learning algorithms analyze historical behaviors to establish dynamic operational baselines. Rather than using static limits, these models learn the natural rhythm of the system, factoring in regular shifts like daily workflow drops or end-of-month processing spikes to create context-aware performance boundaries.
Step 3: Event Correlation
When anomalies break through these dynamic boundaries, the system uses architectural dependency maps to cluster related alerts. By analyzing topology graphs and time-series alignments, the platform links separate warnings across network, database, and application layers into a single cohesive incident event.
Step 4: Root Cause Analysis
With related alerts grouped, the diagnostic engine isolates the primary driver of the failure. The system traces the timeline of anomalies across infrastructure layers, separating downstream symptoms from the initial failure point to guide engineers straight to the source of the breakdown.
Step 5: Automated Remediation
In mature systems, the pipeline moves from diagnosis to active resolution. When a verified root cause matches a known issue pattern, the platform triggers automated runbooks to resolve the problem immediately—such as restarting a leaked process or scaling out a filled disk—restoring services without human intervention.
In Simple Terms:
Advanced automated analysis works like a modern city traffic management center. First, it gathers real-time camera feeds from every intersection. Second, it learns typical rush hour traffic patterns. Third, when an accident happens, it groups related traffic jams across five blocks into a single incident report. Fourth, it identifies the exact broken-down truck causing the backup. Finally, it automatically updates digital street signs to detour traffic and dispatches a tow truck to clear the lane.
Key Takeaways
- Automated analytics pipelines ingest data from across the infrastructure stack to break down operational information silos.
- Dynamic pattern recognition identifies true system anomalies by adapting to natural workload changes.
- Isolating the root cause allows platforms to trigger automated recovery steps, resolving issues before users experience visible downtime.
Real-World Enterprise Use Cases
E-Commerce Platforms
- Challenge: During a massive global shopping event, a popular online retailer suffers a major database performance drop that threatens to stall checkouts and disrupt peak sales traffic.
- Metrics Monitored: Transaction Success Rate, Database Lock Duration, Storage IOPS, API Request Latency.
- AIOps Solution: The analytics platform detects a subtle spike in database lock durations and automatically traces the bottleneck to an unoptimized inventory lookup script. It immediately routes the issue to the database team with full context while temporarily enabling an edge-caching layer to reduce database load.
- Business Outcome: The checkout system remains fully operational, preventing a potential $1.2 million revenue loss and protecting the brand’s reputation during its largest sales event of the year.
Banking Systems
- Challenge: A retail bank experiences unpredictable performance lag across its ATM network and mobile banking applications, leading to transaction timeouts and customer complaints.
- Metrics Monitored: Network Latency, Message Queue Lengths, Core Application Response Times, Error Rates.
- AIOps Solution: An event correlation engine analyzes telemetry across thousands of ATMs, linking minor network latency spikes back to a misconfigured routing update at a central data center.
- Business Outcome: The network team fixes the routing error within minutes, reducing MTTR by 85% and maintaining uninterrupted access to financial services for millions of banking customers.
Healthcare Infrastructure
- Challenge: A hospital network’s electronic health record platform experiences slow response times, delaying access to critical patient files for medical staff in emergency rooms.
- Metrics Monitored: Host Memory Utilization, Container Restart Frequencies, Storage Read Latency, Microservice Call Traces.
- AIOps Solution: Predictive capacity models identify a progressive memory leak inside a core data service, alerting system administrators three days before the service would have exhausted host memory and crashed.
- Business Outcome: IT teams deploy a software patch during a scheduled maintenance window, preventing a critical system crash and ensuring emergency medical teams have uninterrupted access to patient records.
SaaS Platforms
- Challenge: A cloud-based enterprise collaboration platform suffers from fluctuating service availability, caused by sudden, unpredictable usage surges from enterprise clients.
- Metrics Monitored: Pod Resource Starvation, Auto-Scaling Efficiency, HTTP 503 Error Rates, User Experience Indicators.
- AIOps Solution: An intelligent auto-scaling engine monitors incoming workload indicators, predicting usage spikes 15 minutes before they arrive and scaling out Kubernetes node capacity proactively.
- Business Outcome: The platform maintains its 99.99% availability commitment, eliminating service drops during peak business hours and optimizing infrastructure costs by scaling down resources when demand drops.
Cloud-Native Enterprises
- Challenge: A multi-cloud logistics company struggles with alert fatigue, as its monitoring tools flood the operations team with over 50,000 disconnected infrastructure notifications every week.
- Metrics Monitored: Alert Volume, Alert Noise Ratio, False Positive Rate, Event Correlation Accuracy.
- AIOps Solution: An intelligent event processing layer filters the incoming alert stream, automatically suppressing duplicate alerts and clustering related notifications into context-rich incident summaries.
- Business Outcome: Weekly alert volume drops by 94%, eliminating alert fatigue for the engineering team and allowing them to focus on core platform optimization and reliability improvements.
Common Monitoring Mistakes
Monitoring Too Many Metrics
- The Mistake: Tracking every single performance variable across the entire infrastructure stack, resulting in cluttered dashboards and data overload.
- The Solution: Focus on high-value indicators that directly affect service delivery, using core metrics like latency, traffic, error rates, and resource utilization to maintain a clean, actionable view of system health.
Ignoring Context
- The Mistake: Evaluating performance metrics in isolation, without considering how separate infrastructure layers interact or factoring in predictable time-based workload changes.
- The Solution: Use topological maps and historical baseline models to evaluate metrics in context, ensuring alerts are triggered only when anomalous behavior matches a genuine system threat.
Poor Threshold Settings
- The Mistake: Relying on rigid, static alert thresholds across highly dynamic cloud environments, which leads to a constant stream of false alarms or missed system failures.
- The Solution: Replace fixed thresholds with dynamic, machine-learned baselines that automatically adjust to regular seasonal shifts and business growth patterns.
Alert Overload
- The Mistake: Allowing monitoring systems to send unfiltered notifications to engineering teams for every minor performance dip, causing severe alert fatigue.
- The Solution: Implement intelligent deduplication and correlation rules to cluster related alerts into clean incident summaries, ensuring on-call engineers are paged only for actionable emergencies.
Reactive Monitoring
- The Mistake: Operating strictly in a firefighting posture, waiting for a system component to break entirely before assigning an engineering team to resolve the issue.
- The Solution: Use predictive time-series forecasting and early risk indicators to identify resource exhaustion trends and patch vulnerabilities before they can impact end-users.
Best Practices
- Implement KPI-Driven Monitoring: Structure alerting strategies around clear key performance indicators that directly reflect the operational health and stability of your core services.
- Track Business-Centric Metrics: Connect technical telemetry directly to business outcomes by mapping system performance alongside transaction success rates and downtime revenue impacts.
- Leverage Predictive Monitoring: Use time-series forecasting and anomaly detection models to identify infrastructure vulnerabilities early, shifting operations from reactive recovery to proactive prevention.
- Optimize Alerting Pipelines: Continuously refine alert routing and correlation policies to suppress routine background noise, ensuring response teams receive only high-value, actionable notifications.
- Commit to Continuous Improvement: Regularly audit monitoring configurations and post-incident reports, using past operational insights to optimize threshold accuracy and accelerate system remediation workflows.
Future of AIOps Metrics
The future of enterprise observability centers on the transition from traditional system monitoring to fully autonomous infrastructure management. As architectures grow more complex, machine learning models will move beyond simple data aggregation to handle real-time system diagnostic reasoning.
Advanced observability systems will seamlessly combine metrics, logs, and distributed traces into a single, unified data model, using deep learning architectures to understand complex system dependencies across multi-cloud environments.
+---------------------------------------------------------------------------------------+
| EVOLUTION OF OPERATIONAL MATURITY |
+---------------------------------------------------------------------------------------+
| |
| Legacy Monitoring ──► Static Thresholds & Manual Firefighting |
| │ |
| ▼ |
| Modern AIOps ──► Dynamic Baselines & Automated Root-Cause Analysis |
| │ |
| ▼ |
| Autonomous Ops ──► Self-Healing Code, Predictive Remediation & Zero-Downtime |
| |
+---------------------------------------------------------------------------------------+
This evolution will enable the rise of self-healing systems. When an anomaly detection engine identifies an early performance risk, the platform will not simply generate an alert for an engineer; it will independently reason through the root cause, validate a solution within a secure sandbox environment, and automatically apply the necessary infrastructure or code patch.
At the same time, predictive capacity management will become fully automated, dynamically shifting global container workloads across cloud providers in real time to optimize performance, cloud spend, and carbon efficiency without requiring human oversight.
FAQ Section
- What is the difference between standard monitoring metrics and AIOps metrics?Standard monitoring metrics rely on static, human-configured limits that trigger alerts when a threshold is passed. AIOps metrics are analyzed using machine learning algorithms that factor in historical context, architectural dependencies, and seasonal variations to identify true system anomalies.
- How do AIOps tools help reduce alert noise for on-call engineers?AIOps platforms ingest raw notification streams and apply time-series correlation and deduplication algorithms to cluster thousands of related alerts into a single cohesive incident report, silencing the background noise and highlighting the true root cause.
- Can predictive analytics actually prevent enterprise infrastructure outages?Yes. By analyzing long-term utilization trends and identifying subtle patterns across system layers, predictive models can calculate exactly when resources will become exhausted, allowing teams to patch vulnerabilities before services are impacted.
- Why is Mean Time to Resolve considered a critical operational metric?Mean Time to Resolve measures the average time it takes to repair a degraded system and restore full service. It directly impacts your business bottom line because shorter resolution windows minimize downtime costs and protect user trust.
- What role does topology data play in event correlation accuracy?Topology data provides a living structural map of how your hardware, applications, and microservices interact. Correlation engines use this map to verify that separate alerts occurring across different layers are actually linked to a single shared root cause.
- How do dynamic thresholds adapt to seasonal changes in business traffic?Dynamic thresholds use statistical machine learning models to track historical system performance. They learn typical patterns—such as midday traffic peaks or weekend drops—and automatically adjust alert boundaries to match expected workloads.
- What is an error budget and how does it help development teams?An error budget is the total acceptable amount of system instability allowed by your Service Level Objectives. It provides a data-driven framework: if the error budget is full, developers can safely ship features; if it is depleted, they must freeze updates and focus on stability.
- How do cloud-native architectures change enterprise monitoring needs?Cloud-native environments rely on short-lived containers and microservices that scale constantly. This dynamic nature makes traditional static monitoring obsolete, requiring specialized tools that can track ephemeral container health and map shifting dependencies automatically.
- Can technical application performance metrics be linked to business outcomes?Yes. By tracking system performance alongside transactional success metrics, enterprises can measure how technical issues—like an API response delay—directly impact business goals like checkout completions and real-time revenue protection.
- What is the first step an enterprise should take when adopting AIOps tools?The first step is to clean up and unify your data ingestion pipelines. Ensure you are gathering reliable, high-resolution metrics from across your infrastructure stack, as this data forms the foundation your machine learning models need to build accurate baselines.
Final Summary
Building a resilient, modern enterprise infrastructure requires a comprehensive approach to monitoring system health. Tracking performance variables across your hardware stack provides essential visibility into the physical and virtual resource limits of your servers. At the same time, application metrics ensure your software layers run efficiently and deliver a smooth user experience.
When failures do happen, tracking incident management performance helps teams coordinate response efforts, reduce alert fatigue, and shorten resolution windows to minimize system downtime.
Great article! The explanation of key AIOps metrics is clear and practical, helping readers understand what to monitor for better visibility and operational performance.
This is a highly practical guide! The focus on meaningful AIOps metrics helps IT teams understand what truly matters for improving visibility and operational health.