Introduction
Modern corporate networks are expanding faster than ever before. With companies migrating to hybrid cloud architectures, deploying microservices, and managing thousands of connected devices, the scale of corporate tech infrastructure has reached a tipping point. Traditional monitoring tools simply cannot keep up. Legacy setups rely on human engineers to manually sort through millions of system logs, infrastructure alerts, and performance metrics. When an outage occurs, finding the root cause feels like searching for a needle in a digital haystack. This operational bottleneck drains engineering time, costs money, and leads to costly downtime. To solve this data overload, organizations are turning to Artificial Intelligence for IT Operations. By applying machine learning, natural language processing, and advanced data analytics to infrastructure logs, these smart platforms automate system monitoring, reduce alert fatigue, and fix performance issues before they impact the end user. If you are looking to master these modern methodologies, educational learning resources like AIOpsSchool provide structured, practical training designed to help professionals navigate this evolving digital landscape. In this comprehensive guide, we will break down the foundational concepts of modern infrastructure management, examine the core hurdles tech teams face, and explore practical strategies to successfully implement intelligent automation within your organization.
What Is AIOps in Enterprise IT?
Definition
AIOps, which stands for Artificial Intelligence for IT Operations, is the practice of using machine learning, big data, and analytics to automate and improve enterprise IT operations. It acts as an intelligent brain layer that sits on top of your entire technology infrastructure, continuously collecting, analyzing, and acting upon operational data.
Core Objectives
The primary goals of deploying intelligent analytics within a corporate network include:
- Consolidating massive volumes of data from scattered infrastructure layers into a single pane of glass.
- Moving from a reactive fire-fighting mode to proactive, predictive system management.
- Automating repetitive manual tasks to free up highly skilled engineers.
- Drastically reducing the time it takes to detect and resolve system outages.
Key Technologies Behind AIOps
These platforms combine several advanced technologies to process complex infrastructure ecosystems:
- Big Data Ingestion: Pipelines capable of collecting streaming logs, metrics, traces, and events from thousands of sources simultaneously.
- Machine Learning (ML): Algorithms that learn normal baseline behavior and identify unexpected deviations without manual threshold tuning.
- Natural Language Processing (NLP): Systems that analyze unstructured text, such as support tickets or error logs, to categorize issues automatically.
- Automated Orchestration: Scripted workflows that trigger automated fixes when specific performance anomalies are detected.
Why Enterprises Are Adopting AIOps
Organizations are adopting intelligent IT monitoring because human operators can no longer process the sheer volume of data generated by multi-cloud environments. When a single application relies on hundreds of distributed microservices, manual oversight is impossible. Businesses need automated, intelligent systems to maintain uptime, protect revenue, and deliver flawless digital experiences.
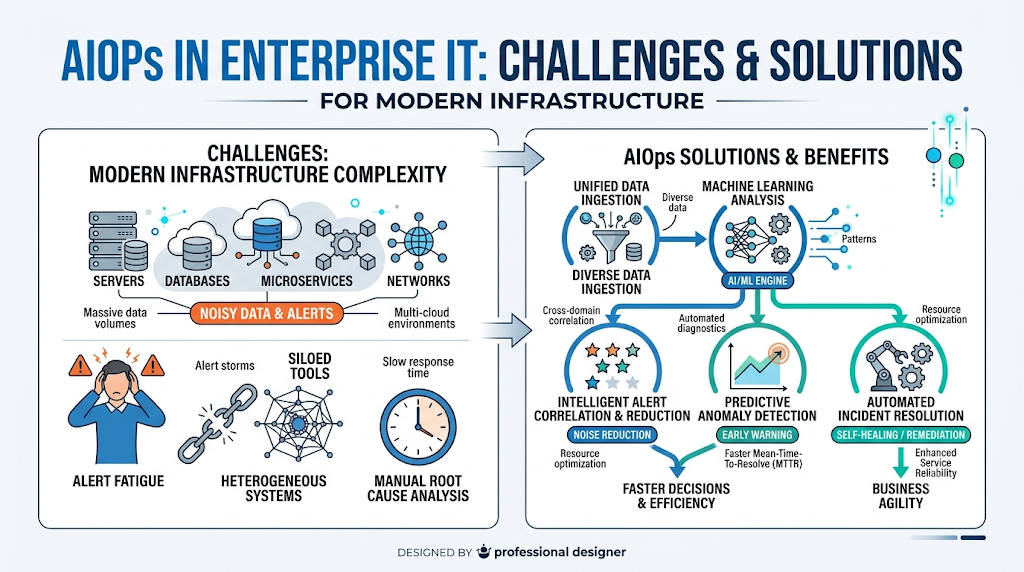
Understanding Enterprise IT Challenges
Before exploring solutions, it is crucial to understand the foundational pain points that plague modern engineering and infrastructure teams.
Alert Fatigue
On a typical day, a corporate infrastructure team can receive tens of thousands of automated alerts. Most of these notifications are non-critical noise, such as a temporary spike in CPU usage. Because engineers are constantly bombarded with notifications, they become desensitized, increasing the risk that a critical, revenue-threatening system failure goes unnoticed.
Data Silos
Large corporations often use separate monitoring tools for different departments. The database team uses one dashboard, the network engineers use another, and the software development team relies on a third application performance monitor. Because these tools do not talk to each other, it is difficult to get a unified view of system health when an incident occurs.
Increasing Infrastructure Complexity
Modern software runs on a mix of on-premises legacy servers, public cloud environments, containerized Kubernetes clusters, and serverless architectures. This distributed footprint makes it incredibly difficult to map how different systems depend on each other, causing visibility gaps across the tech stack.
Manual Incident Response
When an application crashes, engineers from different departments typically jump onto an emergency troubleshooting call. They manually pull up logs, write custom database queries, and debate where the problem lies. This uncoordinated, manual process elongates system downtime and hurts productivity.
Limited Operational Visibility
Without centralized observability, teams only know a system is down after it breaks—or worse, after a customer files a complaint. Lacking real-time visibility prevents engineers from anticipating infrastructure failures or identifying hidden bottlenecks before they turn into critical outages.
Scalability Challenges
As a company grows, its infrastructure data scales exponentially. Traditional rule-based monitoring tools require engineers to manually update alert thresholds every time a new server or service is added. This approach does not scale, leaving teams trapped in an endless cycle of configuration updates.
AIOps in Enterprise IT: Challenges and Solutions
Implementing intelligent systems directly addresses these enterprise operational roadblocks through targeted, data-driven features.
Intelligent Event Correlation
- The Challenge: A single network glitch can trigger hundreds of individual alarms across various connected databases, applications, and firewalls, confusing the triage team.
- The Solution: Intelligent platforms ingest all these scattered alerts, recognize they stem from the exact same network glitch, and compress them into a single, actionable incident ticket. For example, if a core switch fails, instead of alerting on fifty down servers, the platform creates one ticket pointing directly to the switch.
Anomaly Detection
- The Challenge: Static thresholds (like alerting whenever memory usage hits 85%) cause false alarms during standard high-traffic periods, such as an e-commerce site during a holiday sale.
- The Solution: Machine learning algorithms evaluate historical patterns to build a dynamic baseline of normal behavior. If memory spikes to 90% during an expected peak shopping window, the system knows it is normal and remains quiet. If it spikes to 90% at midnight on a Tuesday, the platform flags it as an anomaly.
Predictive Analytics
- The Challenge: Storage disks and cloud resources run out of capacity unexpectedly, causing sudden application crashes and performance degradation.
- The Solution: By analyzing historical data growth trends, predictive engines forecast exactly when a storage volume will fill up. For instance, the system can notify the infrastructure team that a database disk will hit 95% capacity in roughly fourteen days, allowing engineers to expand the drive during normal business hours.
Automated Root Cause Analysis
- The Challenge: When an application slows down, finding whether the culprit is a slow database query, a bad software deployment, or a cloud provider outage takes hours of manual research.
- The Solution: The platform maps the dependencies across your entire infrastructure in real time. If a performance drop happens right after a new code deployment, the system cross-references the event log and instantly tells the engineer: “The app slowed down because deployment version 2.4 caused a database deadlock.”
Self-Healing Automation
- The Challenge: Engineers are frequently woken up in the middle of the night to clear temporary cache files or restart stuck system services.
- The Solution: When a known, predictable issue occurs, the platform triggers an automated script to resolve it instantly without human intervention. For example, if a specific web service freezes, the system detects the freeze, safely restarts the service container, verifies it is healthy, and logs the action—all while the on-call engineer stays asleep.
Capacity Planning
- The Challenge: Enterprises over-provision cloud infrastructure to prevent downtime, wasting thousands of dollars each month on idle computing resources.
- The Solution: Advanced analytics engines track processing loads over extended periods and recommend right-sizing configurations. The platform might identify twenty cloud instances that are constantly running below 10% capacity and safely suggest downgrading them to smaller, less expensive server profiles.
Performance Optimization
- The Challenge: Hidden application latencies slowly degrade user experience over time, but go unnoticed because systems technically remain “online.”
- The Solution: Continuous monitoring models track end-to-end user transactions across infrastructure layers. If an API request that normally takes 200 milliseconds begins taking 800 milliseconds due to an inefficient database index, the platform flags the trend so developers can optimize the code.
AIOpsSchool Guide to Enterprise AIOps
Successfully shifting to an intelligent operational model requires a structured, deliberate roadmap. This framework outlines how to transition your engineering teams toward automated operations.
Building a Strong Observability Strategy
Before deploying artificial intelligence, you need comprehensive, high-quality data. Establish a centralized observability pipeline that ingests the three core pillars of monitoring:
- Metrics: Numeric time-series data tracking system health (CPU, memory, disk usage).
- Logs: Text records of specific events that occurred within your applications and servers.
- Traces: End-to-end paths of a user request as it travels through your distributed network.
Reducing Operational Complexity
Break down internal organizational walls by funneling all telemetry data into a unified platform. Ensure your software developers, cloud engineers, and security specialists share the same operational view. This shared visibility eliminates finger-pointing during major system incidents and establishes a single source of truth.
Improving Incident Response
Design a progressive alerting workflow that filters out low-priority noise. Configure your platform to route highly critical, correlated incidents directly to your team’s communication tools (like Slack or Microsoft Teams) along with the context needed to fix it. Keep lower-priority warnings out of emergency channels and store them in non-urgent tracking queues.
Automating Repetitive IT Tasks
Start small with automation. Identify high-volume, low-risk operational workflows that your engineering team handles manually every week. Good initial candidates include:
- Clearing disk space when log folders fill up.
- Restarting non-production servers on a weekend.
- Scaling up web app instances before scheduled promotional emails go out.
Preparing for Enterprise-Scale AIOps Adoption
Prepare your staff for culture shifts by treating automation as an assistant, not a replacement. Focus initial efforts on achieving high data quality across your current monitoring systems. Ensure your engineering teams document operational procedures into standard execution playbooks so they can eventually be translated into automated, self-healing workflows.
Benefits of AIOps for Enterprise IT
[Telemetry Ingestion] ──> [Intelligent Correlation] ──> [Automated Root Cause] ──> [Self-Healing Fix]Faster Incident Detection
By analyzing telemetry data in real time, machine learning engines catch subtle anomalies long before they trigger a major system alert or cause noticeable application slowdowns.
Reduced Downtime
When systems fail, automated root cause identification slashes troubleshooting times from hours to minutes, keeping enterprise services online and preserving business revenue.
Better Operational Efficiency
Automating repetitive diagnostic and maintenance tasks frees engineering teams from tedious fire-fighting, allowing them to focus on building new features and scaling system infrastructure.
Improved Resource Utilization
Predictive capacity planning identifies over-provisioned infrastructure, helping finance and technology leaders scale down unused assets and lower public cloud costs.
Enhanced Service Reliability
Catching infrastructure issues early and applying automated, self-healing fixes ensures that your customer-facing applications maintain consistently high uptime and performance stability.
Better Customer Experience
When underlying IT environments run smoothly, end users experience fast page load speeds, minimal application downtime, and seamless interactions with your digital products.
Real-World Enterprise Use Cases
Banking and Financial Services
A global bank handles millions of payment transactions every minute. A small database delay can stall credit card verifications worldwide. By using intelligent monitoring, the bank tracks transactional flows across hybrid mainframes and cloud containers, instantly pointing out and isolating network bottlenecks to keep processing lines moving smoothly.
Healthcare
Hospital networks host critical patient-tracking applications and electronic health record databases that require zero downtime. Intelligent IT platforms scan hospital server clusters for memory leaks, alerting infrastructure engineers to perform automated live migrations of critical software before any medical systems freeze.
Telecommunications
Telecom operators run massively distributed cellular towers and edge-computing nodes. An anomaly detection model monitors traffic spikes across these locations, automatically rerouting network traffic during sudden outages to prevent dropped calls and maintain local service quality.
Manufacturing
Smart factories rely on internet-of-things (IoT) assembly systems and connected inventory software. An analytics engine tracks connectivity telemetry across the factory floor, identifying failing hardware gateways and initiating automated backup connections to prevent assembly line stoppages.
Retail and E-Commerce
During major online shopping holidays, flash traffic can easily crash retail web servers. Intelligent capacity planning tools forecast shopping spikes based on real-time inbound traffic trends, automatically scaling up cloud compute instances before checkout systems get overwhelmed.
Cloud Service Providers
Large-scale infrastructure hosts manage tens of thousands of customer virtual machines simultaneously. Automated log correlation groups millions of system events together, allowing hosting engineers to isolate localized fiber-optic line cuts from broader, platform-wide outages within seconds.
Traditional IT Operations vs AIOps-Driven Operations
The table below contrasts traditional infrastructure management with a modern, intelligent operational approach:
| Capability | Traditional IT Operations | AIOps-Driven Operations |
|---|---|---|
| Monitoring | Manual dashboards and static thresholds | AI-driven observability with dynamic baselines |
| Alert Management | Rule-based alerts resulting in high noise | Intelligent event correlation and noise reduction |
| Incident Resolution | Manual troubleshooting and war rooms | Automated root cause analysis and smart diagnostics |
| Capacity Planning | Reactive scaling based on historical guesswork | Predictive resource forecasting and right-sizing |
| Automation | Limited, basic script execution | Continuous intelligent automation and self-healing |
Common Implementation Challenges
Transitioning to an AI-driven operational framework presents distinct technical and cultural hurdles that leadership teams must carefully manage.
Legacy Systems Integration
- The Challenge: Old, on-premises applications often lack standard APIs or logging methods, making it hard to feed their operational data into modern analytics engines.
- The Recommendation: Deploy lightweight open-source data collectors and log forwarders (like Fluentbit or OpenTelemetry collectors) to capture legacy outputs and transform them into standardized data formats before processing.
Poor Data Quality
- The Challenge: Machine learning models rely heavily on clean data. If your servers produce fragmented logs or inaccurate timestamps, your AI platform will produce inaccurate alerts.
- The Recommendation: Establish strict enterprise-wide logging standards. Ensure every development team logs errors using structured JSON formats with uniform timestamping protocols.
Resistance to Organizational Change
- The Challenge: Veteran system administrators and operations engineers are often skeptical of automated actions, fearing that a rogue script could break a critical production environment.
- The Recommendation: Implement automation gradually using “read-only” recommendations first. Let the AI recommend a fix to an engineer via an interactive prompt. Once the team trusts the system’s accuracy, enable fully automated execution.
Skills Gap
- The Challenge: Traditional system operators often lack deep expertise in data science, machine learning models, and modern cloud observability concepts.
- The Recommendation: Invest in clear technical training and continuous educational upskilling programs to help your engineers transition into modern, automated operational roles.
AI Model Accuracy
- The Challenge: If an AI model is not properly calibrated, it can suffer from “hallucinations” or generate false positives, leading to inaccurate system conclusions.
- The Recommendation: Continuously validate your machine learning models against actual operational incident reports. Periodically retrain your models with updated infrastructure baselines to keep up with changing system environments.
Best Practices for Enterprise AIOps
To ensure long-term operational success, ground your implementation strategy in these core operational principles:
- Centralize Observability Data: Funnel all network, server, database, and application logs into a single data lake to eliminate operational blind spots.
- Standardize Monitoring Processes: Define clear, uniform key performance indicators across all business units so your analytics platform evaluates metrics using a consistent framework.
- Automate Repetitive Workflows: Start by automating predictable operational tasks, then gradually expand to complex self-healing processes as your platform matures.
- Continuously Refine AI Models: Regularly audit your platform’s anomaly detection alerts to eliminate false positives and keep machine learning baselines accurate.
- Encourage Cross-Functional Collaboration: Bring your software developers, cloud infrastructure engineers, and security specialists together to build a shared, collaborative automation strategy.
Career Opportunities
The shift toward intelligent infrastructure management is creating a wave of high-demand technical career paths across the corporate landscape:
- AIOps Engineer: Specialists who deploy, tune, and manage the platform tools, data pipelines, and machine learning models that drive automated operations.
- Site Reliability Engineer (SRE): Software engineers focused on using automation, monitoring, and proactive architectural design to maximize system uptime and reliability.
- Cloud Operations Engineer: Professionals tasked with deploying, monitoring, and optimizing distributed cloud infrastructure resources and microservices.
- DevOps Engineer: Specialists focused on bridging the gap between software development and IT operations by automating build pipelines and infrastructure provisioning.
- Platform Engineer: Infrastructure architects who design internal self-service developer platforms, making it easier for engineering teams to deploy code safely.
- Enterprise IT Architect: Senior technology leaders who design the overarching infrastructure strategies, tools, and integration roadmaps for the entire corporation.
Future of AIOps in Enterprise IT
Autonomous IT Operations
As machine learning capabilities advance, corporate technology infrastructure will transition toward completely autonomous operations. These highly advanced environments will monitor, diagnose, patch, and optimize themselves continuously, requiring human engineering intervention only for major strategic design decisions.
AI-Driven Observability
Future monitoring frameworks will automatically instrument new services the moment they are deployed. The system will independently identify what metrics matter, map application dependencies dynamically, and build out customized operational dashboards without any manual configuration.
Predictive Infrastructure Management
Analytics engines will move far beyond basic capacity planning, using deep historical trends to forecast seasonal storage shortages, bandwidth constraints, and global hardware supply limits months in advance.
Self-Healing Systems
Automated self-healing workflows will soon mature into sophisticated, multi-layered defensive frameworks. If an application database fails, the platform will spin up isolated testing sandboxes, run diagnostic tests, compile an emergency code patch, test it, and push it live into production completely safely.
Intelligent Enterprise Automation
Intelligent workflows will increasingly unify technical system infrastructure with broader business processes, seamlessly linking real-time server application performance directly to corporate inventory logs, user signup statistics, and financial tracking ledgers.
Common Misconceptions
AIOps Replaces IT Professionals
The Reality: These tools are designed to automate repetitive, boring tasks like log scanning and basic diagnostics. By taking over routine work, the platform acts as an assistant, allowing engineers to focus on higher-value creative tasks like system architecture and software innovation.
AIOps Is Only for Large Enterprises
The Reality: While large corporations face massive data scaling challenges, medium-sized businesses running modern cloud applications benefit just as much. Implementing automated observability early helps smaller teams manage complex container infrastructure without hiring an army of operations engineers.
AI Can Solve Every Operational Problem Automatically
The Reality: An intelligent platform is only as good as the underlying data it receives. If your systems output messy logs or your engineering workflows are poorly defined, your automation models will produce flawed results. Success requires clean data and clear human-designed processes.
AIOps Is Just Advanced Monitoring
The Reality: Traditional monitoring tools focus on displaying what happened in the past on static dashboards. Intelligent platforms go a massive step further—they ingest multi-source data, correlate events, predict future failures, and execute automated actions to resolve problems independently.
FAQ Section
- What is the primary difference between traditional monitoring and AIOps?
Traditional monitoring tools simply collect data and alert engineers when a specific system threshold is broken. Intelligent platforms go much further by analyzing all your data sources simultaneously, grouping related alerts together, pinpointing the root cause, and triggering automated fixes. - Can small companies benefit from intelligent IT automation, or is it only for massive corporations?
Companies of all sizes benefit from these platforms. If a mid-sized business manages a modern cloud-native system using microservices, the environment can quickly become too complex for a small engineering team to watch manually. Automation helps them scale operations efficiently without rapidly expanding headcount. - How does automated event correlation help reduce alert fatigue for on-call engineers?
When an infrastructure component fails, it usually triggers a storm of individual alarms across connected systems. An event correlation engine scans these incoming warnings in real time, recognizes they are caused by the same root issue, and combines them into a single, organized incident ticket. - Will adopting intelligent platforms require us to completely replace our existing monitoring tools?
No, you do not need to throw away your current monitoring tools. Modern intelligence platforms are built to integrate with your existing setup, acting as a smart processing layer that ingests data from your current application performance monitors, log aggregators, and cloud platforms. - What exactly is a “self-healing” system in enterprise IT operations?
A self-healing system uses automated orchestration to fix known, predictable infrastructure errors without human help. For instance, if a server run out of disk space due to temp files, the platform detects the issue, triggers a script to clear the cache, and confirms the system is healthy. - What is the role of machine learning in anomaly detection?
Instead of relying on rigid, manually entered alert limits, machine learning algorithms continuously study your historical system data to understand what normal performance looks like. This lets the system set dynamic baselines that automatically adjust for seasonal traffic changes and business growth. - How can an organization measure the return on investment of an AIOps implementation?
You can calculate your return on investment by tracking key metrics over time. Look for a steady drop in your Mean Time to Resolve incidents, a reduction in total system downtime hours, lower cloud infrastructure spend, and fewer low-priority alert notifications hitting your engineers. - What are the biggest cultural hurdles when introducing automation to an IT team?
The main cultural challenge is skepticism from engineering staff who worry about loss of control or job security. Overcome this by involving your teams in the rollout, using read-only recommendations at first to build trust, and emphasizing how automation eliminates boring tasks so they can focus on cool projects. - How does predictive analytics assist in enterprise capacity planning?
Predictive analytics looks at your historical resource usage trends to forecast future needs accurately. For example, it analyzes your database growth rate over the last six months to predict the exact week a storage volume will fill up, letting you expand it safely ahead of time. - Where should a technology professional start if they want to learn more about AIOps methodologies?
Engineers looking to build their skills should focus on learning the core pillars of observability—metrics, logs, and traces. Utilizing structured educational resources like AIOpsSchool helps professionals gain practical, structured insights into machine learning, data engineering, and modern automated operations.
Final Summary
As enterprise IT environments grow more complex, relying on manual monitoring processes is no longer viable. Teams cannot scale by simply adding more dashboards or expanding on-call shifts. To maintain system availability and keep pace with digital transformation, businesses must adopt an intelligent, automated approach to managing their infrastructure. By implementing advanced observability, event correlation, and predictive analytics, enterprises can cut through operational noise, slash system resolution times, and prevent outages before they impact customers. Success requires a deliberate focus on high data quality, structured automation roadmaps, and continuous team upskilling. If you are ready to advance your career and master the principles of automated, intelligent infrastructure management, leverage the comprehensive learning paths and educational resources available at AIOpsSchool to become a leader in the next generation of enterprise IT operations.