Introduction
Modern applications run on complex, distributed systems that span microservices, containers, multiple clouds, and hybrid infrastructure. In this environment, traditional monitoring alone is not enough to keep systems fast, reliable, and cost effective. Observability engineering has emerged as a focused discipline that helps teams see what is happening inside their systems using metrics, logs, traces, and events. The Master in Observability Engineering (MOE) certification by DevOpsSchool is designed to help engineers and leaders build deep, hands-on expertise in this area. In this guide, you will learn what MOE is, who it is for, skills you gain, how to prepare, how it fits across DevOps, SRE, DevSecOps, AIOps/MLOps, DataOps, and FinOps, and how to connect it with your long-term career path.
What is Master in Observability Engineering (MOE)?
Master in Observability Engineering (MOE) is a specialized certification and training program focused on building end-to-end observability for modern software systems. It helps you design, implement, and improve telemetry across metrics, logs, traces, and events using popular tools and cloud services.
The program covers concepts, architecture, tools, and hands-on labs that map directly to real production environments. You learn how to detect issues faster, reduce MTTR, and make data-driven decisions for performance, reliability, and cost.
Why Observability Matters Today
- Systems are distributed across containers, Kubernetes, serverless, and multi-cloud.
- Users expect fast, always-on digital experiences with minimal downtime.
- Business teams need insights into performance, reliability, and costs in near real time.
- SRE, DevOps, and platform teams must collaborate using shared, objective data from telemetry.
Observability gives you the ability to ask new questions about system behavior without adding new code each time. It becomes the foundation for SRE practices, DevSecOps, AIOps, and continuous improvement.
Key Skills Covered in MOE
You can expect MOE training to cover topics such as:
- Fundamentals of observability and its pillars (metrics, logs, traces, events).
- Instrumentation best practices for applications and infrastructure.
- Metrics collection, storage, and visualization using time-series tools.
- Log aggregation, indexing, and analysis patterns.
- Distributed tracing in microservices and service mesh environments.
- Designing alerting, SLOs, SLIs, and error budgets.
- Using tools like Prometheus, Grafana, ELK stack, OpenTelemetry, Jaeger, and cloud-native services.
- Observability for Kubernetes and cloud-native systems.
- Root cause analysis and incident troubleshooting workflows.
- Integrating observability into CI/CD and DevOps pipelines.
- Advanced analysis, anomaly detection, and AI/ML for observability.
These skills are directly applicable across DevOps, SRE, security, data, and financial operations teams.
MOE Certification Overview Table
Below is a simplified overview of the MOE certification in the format you requested.
| Track | Level | Who it’s for | Prerequisites | Skills covered | Recommended order |
|---|---|---|---|---|---|
| Observability Engineering | Intermediate–Advanced | Software/DevOps/SRE/Cloud/Platform engineers, managers, tech leads | Basic Linux, networking, app lifecycle, monitoring basics | Observability concepts, metrics/logs/traces, OpenTelemetry, Prometheus, Grafana, ELK, APM, alerting, SLO/SLI, incident response | Take after basic DevOps/Cloud/Monitoring knowledge |
Detailed View: Master in Observability Engineering (MOE)
What it is
Master in Observability Engineering (MOE) is a focused certification program that teaches you how to design and implement complete observability for modern, distributed systems. It brings together concepts, patterns, and tools to help you make production systems transparent, measurable, and reliable.
Who should take it
- DevOps engineers who manage CI/CD, infrastructure, and deployment pipelines.
- SREs responsible for SLOs, incident response, and reliability.
- Cloud and platform engineers managing Kubernetes, containers, and multi-cloud platforms.
- Security engineers who need better visibility into runtime behavior and threats.
- Data and AIOps engineers building analytics, dashboards, and automation on top of telemetry.
- Engineering managers who want to standardize observability practices across teams.
Skills you’ll gain
- Understand observability pillars and how they differ from traditional monitoring.
- Design observability architectures for microservices and cloud-native systems.
- Instrument applications and services with OpenTelemetry.
- Collect and visualize metrics with Prometheus, Grafana, and cloud services.
- Implement log aggregation and analysis using ELK and similar stacks.
- Set up distributed tracing for end-to-end request visibility.
- Define SLOs, SLIs, and alerting strategies aligned to business goals.
- Apply observability techniques to incident management and postmortems.
- Use AI/ML-based insights and anomaly detection to improve reliability.
- Integrate observability into DevOps pipelines and Infrastructure as Code.
Real-world projects you should be able to do after it
- Design and implement an observability stack for a microservices-based web application.
- Set up metrics, logs, and traces for a Kubernetes cluster with dashboards and alerts.
- Build SLOs, SLIs, and alert policies for critical services, and integrate with incident tools.
- Implement OpenTelemetry-based instrumentation across services in different languages.
- Build dashboards for application performance, infrastructure health, and business KPIs.
- Conduct root cause analysis using logs, traces, and metrics during outages.
- Automate observability setup via scripts, IaC templates, and CI/CD stages.
Preparation plan (7–14 days / 30 days / 60 days)
7–14 days (Fast track):
- Day 1–2: Study observability fundamentals and pillars.
- Day 3–4: Practice metrics and dashboarding with one stack (for example, Prometheus + Grafana).
- Day 5–6: Learn basic logging and distributed tracing on a sample app.
- Day 7–10: Implement a small observability lab (app + infra + dashboards + alerts).
- Day 11–14: Revise core concepts, tools, and do a mock project end-to-end.
30 days (Balanced track):
- Week 1: Observability concepts, architecture, and patterns.
- Week 2: Metrics, logging, and dashboards using two tool stacks (for example, cloud-native + open source).
- Week 3: Distributed tracing, OpenTelemetry, and Kubernetes observability.
- Week 4: SLOs/SLIs, alerting, incident management, and a capstone project mapping to your current environment.
60 days (Deep dive):
- Weeks 1–2: Fundamentals, monitoring vs observability, core tools.
- Weeks 3–4: Advanced logging, tracing, and service mesh observability.
- Weeks 5–6: AIOps techniques, anomaly detection, cost-aware observability, and automation via CI/CD and IaC.
Common mistakes
- Treating observability as just “more dashboards” instead of a design principle.
- Over-collecting data without clear use cases, leading to noise and high costs.
- Ignoring logs or traces and focusing only on metrics.
- Not aligning SLOs and alerts with actual user and business impact.
- Building observability as a one-time project rather than an evolving practice.
- Leaving observability ownership only to a single team instead of making it a shared responsibility.
Best next certification after this
- Same track (Operations/Observability):
- Advanced SRE or reliability engineering certification.
- A specialized monitoring or performance engineering program.
- Cross-track (Broadening skills):
- DevSecOps certification to connect observability with security.
- Kubernetes or cloud-native certifications to deepen platform understanding.
- Leadership (Management & Strategy):
- Engineering management, platform leadership, or architecture-focused courses.
- Programs that cover building observability culture, governance, and cross-team adoption.
Choose Your Path: How MOE Fits Different Tracks
MOE is flexible and supports multiple career paths. Below are six learning paths where observability acts as a core enabler.
1. DevOps Path
- Use observability to validate deployments, detect regressions, and roll back safely.
- Embed telemetry checks into CI/CD pipelines.
- Combine MOE with container, Kubernetes, and cloud certifications for full-stack DevOps maturity.
2. DevSecOps Path
- Use logs and traces to detect anomalies and possible security events.
- Build security dashboards for runtime behavior and access patterns.
- Combine MOE with security scanning, threat modeling, and compliance tools.
3. SRE Path
- Make observability the backbone of SLOs, SLIs, and error budgets.
- Drive incident response, on-call workflows, and postmortems based on telemetry.
- Combine MOE with SRE and reliability engineering certifications.
4. AIOps / MLOps Path
- Use observability data as input to AIOps platforms for anomaly detection and predictive alerts.
- Monitor ML pipelines, model performance, and data drift through metrics and logs.
- Combine MOE with AIOps/MLOps programs to automate operations using machine learning.
5. DataOps Path
- Treat telemetry as a data product for analytics and reporting.
- Build pipelines that clean, store, and analyze observability data at scale.
- Combine MOE with data engineering and DataOps certifications to support data-driven decision making.
6. FinOps Path
- Use observability metrics to understand resource usage and cost drivers.
- Correlate performance and reliability metrics with spend to optimize cost.
- Combine MOE with FinOps training to align technical observability with financial accountability.
Role → Recommended Certifications Mapping
Below is a role-based mapping with MOE as a core element.
| Role | Primary focus with MOE | Recommended certifications (including MOE) |
|---|---|---|
| DevOps Engineer | CI/CD, infra automation, deployment health, rollback safety | MOE, container/Kubernetes, cloud associate/professional, infra as code and pipeline-focused programs |
| SRE | Reliability, SLOs/SLIs, incident response, error budgets | MOE, SRE foundations/advanced reliability, Kubernetes, on-call and incident management-focused trainings |
| Platform Engineer | Internal platforms, self-service, shared observability stack | MOE, cloud-native platform, Kubernetes, GitOps, internal developer platform certifications |
| Cloud Engineer | Cloud services, infra design, cost and performance monitoring | MOE, cloud architect/operations, security basics, cost optimization trainings |
| Security Engineer | Runtime security, threat visibility, compliance | MOE, DevSecOps programs, cloud security, logging and SIEM-focused certifications |
| Data Engineer | Telemetry as data, pipelines, analytics dashboards | MOE, data engineering, streaming platforms, BI/reporting and analytics-focused certifications |
| FinOps Practitioner | Cost visibility, optimization, value tracking | MOE, FinOps certifications, cloud cost management, KPI and reporting trainings |
| Engineering Manager | Standardizing practices, KPIs, reliability and cost governance | MOE, leadership/management programs, architecture and platform strategy, SRE or DevOps management-focused certifications |
Top Institutions for MOE Training and Certification Support
Below are institutions that provide training and certification support around Master in Observability Engineering (MOE) and related topics. Descriptions are generic and concise.
DevOpsSchool
DevOpsSchool is the primary provider of the Master in Observability Engineering (MOE) certification and training. It offers instructor-led sessions, self-paced content, hands-on labs, and lifetime learning resources to support learners at different levels.
Cotocus
Cotocus focuses on specialized DevOps, SRE, and cloud-native upskilling programs. It supports learners with structured tracks, real-world projects, and corporate-ready training plans for modern operations roles.
Scmgalaxy
Scmgalaxy offers training across DevOps, CI/CD, cloud technologies, and tooling ecosystems. It helps individuals and teams adopt best practices in automation, configuration management, and collaborative delivery.
BestDevOps
BestDevOps works as a content and learning hub for DevOps and reliability engineering topics. It shares guides, training resources, and curated learning paths to help professionals advance in DevOps and observability careers.
devsecopsschool.com
devsecopsschool.com specializes in DevSecOps training. It helps engineers blend observability, security tooling, and automation to build secure and visible software delivery pipelines.
sreschool.com
sreschool.com focuses on SRE skills such as reliability, incident management, and on-call practices. It aligns closely with observability, SLOs, and platform stability.
aiopsschool.com
aiopsschool.com provides programs in AIOps and intelligent operations. It emphasizes using telemetry, machine learning, and automation to predict and prevent failures in complex systems.
dataopsschool.com
dataopsschool.com targets DataOps and data engineering workflows. It supports building reliable, observable data pipelines and analytics environments.
finopsschool.com
finopsschool.com focuses on FinOps and cloud cost management skills. It connects usage metrics, observability data, and financial insights to optimize cloud spending.
FAQs (Master in Observability Engineering – General)
- What is Master in Observability Engineering (MOE)?
Master in Observability Engineering (MOE) is a certification and training program that teaches you how to design and implement observability for modern applications and infrastructure. - Is MOE only for DevOps or SRE roles?
No, MOE is useful for DevOps, SRE, cloud, platform, security, data, and FinOps roles, as well as managers who lead these teams. - How difficult is the MOE certification?
The difficulty is moderate if you already understand basic infrastructure, applications, and monitoring concepts. With focused preparation, most working engineers can complete it successfully. - How much time do I need to prepare for MOE?
Depending on your background, you can prepare in 2–8 weeks. A fast track (7–14 days), balanced (30 days), or deep-dive (60 days) plan can all work well. - What are the prerequisites for MOE?
You should know basic Linux, networking, application lifecycle, and general monitoring ideas. Hands-on experience with any cloud or container platform is helpful but not mandatory. - In what order should I take MOE compared to other certifications?
It is better to take MOE after you have fundamental cloud or DevOps knowledge. After MOE, you can move into SRE, Kubernetes, DevSecOps, or AIOps programs. - What career benefits can I expect from MOE?
MOE can help you move into SRE, platform engineering, observability engineering, or lead DevOps roles by proving you understand production-grade visibility and reliability. - Is MOE useful if I already work as an SRE?
Yes, MOE deepens your understanding of telemetry, tracing, and tooling, and helps you design more mature observability practices across teams. - Does MOE focus on specific tools or general concepts?
It covers both: general patterns and specific tools like Prometheus, Grafana, ELK, OpenTelemetry, and cloud-native services, combined with real-world labs. - Can managers or non-coding roles benefit from MOE?
Yes. Managers gain a better view of how to measure reliability, align SLOs with business goals, and build observability culture in their teams. - How does MOE help with FinOps or cost optimization?
By giving visibility into resource usage and performance, MOE helps you connect technical telemetry with cost and value metrics, which is vital for FinOps. - Is MOE relevant for AI/ML and data-heavy systems?
Yes. Observability is critical for monitoring ML pipelines, model performance, and data quality, which makes MOE valuable in AIOps and MLOps environments.
FAQs
- What learning format does MOE typically follow?
MOE is usually delivered as instructor-led online sessions supported by self-paced content, labs, and project work that mirror real production environments. - What topics are covered in the MOE agenda?
The agenda includes observability fundamentals, instrumentation, metrics, logs, traces, OpenTelemetry, cloud-native observability, incident management, and AI/ML-based analysis. - Are there hands-on labs in MOE?
Yes, MOE includes guided hands-on labs where you set up observability tools, instrument applications, and troubleshoot realistic scenarios. - Does MOE include interview preparation support?
Some MOE programs offer interview support, including question banks, resume guidance, and mock interviews for observability and SRE roles. - How long is the MOE training itself?
Depending on format, MOE can range from short, intensive training over a few days to extended programs spread over several weeks, with flexible modes for individuals and corporates. - Which industries value MOE skills the most?
Industries that run large digital platforms—such as finance, e-commerce, SaaS, healthcare, and telecom—value observability skills because uptime and performance are critical. - Does MOE require coding skills?
Basic coding and scripting skills are helpful, especially for instrumentation and automation, but you do not need to be a full-time developer to benefit from MOE. - How do I keep my MOE skills up to date after certification?
Continue practicing on real systems, explore new tools in the observability ecosystem, and align your work with SRE, DevSecOps, and FinOps practices as they evolve.
Next certifications to take (3 options: same track, cross-track, leadership)
1) Same-track (Observability / SRE)
Stay tightly aligned with MOE and build a recognizable observability/SRE profile.
- New Relic role-based certifications – Foundations → APM Practitioner → Performance Engineer / Reliability Engineer; this pairs nicely with the MOE focus on APM, telemetry, and incident management.
- DevOps Institute Observability Foundation – formalizes vendor-neutral best practices around full-stack observability, logs/metrics/traces, and SLO-centric thinking.
- Advanced OpenTelemetry / tracing specialization (via focused vendor programs or workshops) to double down on telemetry pipelines and distributed tracing, which MOE already emphasizes.
Good if you want to be seen as “Observability / SRE specialist” and monetize MOE content with tool-specific case studies and labs.
2) Cross-track (DevOps / Platform / Cloud)
Leverage MOE as a pillar inside a broader DevOps or platform engineering narrative.
- DevOpsSchool – Masters in DevOps Engineering (MDE): turns your observability depth into part of a full DevOps/DevSecOps toolkit (CI/CD, infra-as-code, Kubernetes, SRE-style practices).
- Cloud provider tracks with strong monitoring content (e.g., AWS, Azure, GCP associate/professional level) to tie MOE’s Prometheus/Grafana/APM/logging skills into cloud-native operations.
- Data / AI observability (e.g., Acceldata’s free Data Observability certification) if you want to pivot some content toward MLOps/DataOps reliability.
Good if your brand is “end-to-end DevOps / Cloud engineer who also masters observability.”
3) Leadership / Architecture / Strategy
Use MOE as your technical credibility, then add credentials that signal decision-making authority and roadmap skills.
- SRE / Reliability leader certifications (e.g., SRE-focused programs that emphasize SLOs, error budgets, incident command, and reliability culture) to move from “tool user” to “reliability owner.”
- DevOps leadership / transformation certifications (from DevOps-focused institutes) covering value streams, org design, and cultural change, where MOE becomes your proof of “I know how to actually instrument what I’m designing.”
- Architecture-focused paths (cloud or platform architect) where observability is presented as a core non-functional requirement baked into all designs.
Conclusion
Master in Observability Engineering (MOE) is a powerful certification for anyone working with modern, distributed systems who wants deeper visibility, better reliability, and more informed decision making. It connects naturally with DevOps, SRE, DevSecOps, AIOps/MLOps, DataOps, and FinOps, making it a central building block in your long-term engineering career.
By investing in MOE, you are not just learning tools, but building a mindset where observability becomes an essential part of how you design, ship, and operate software.
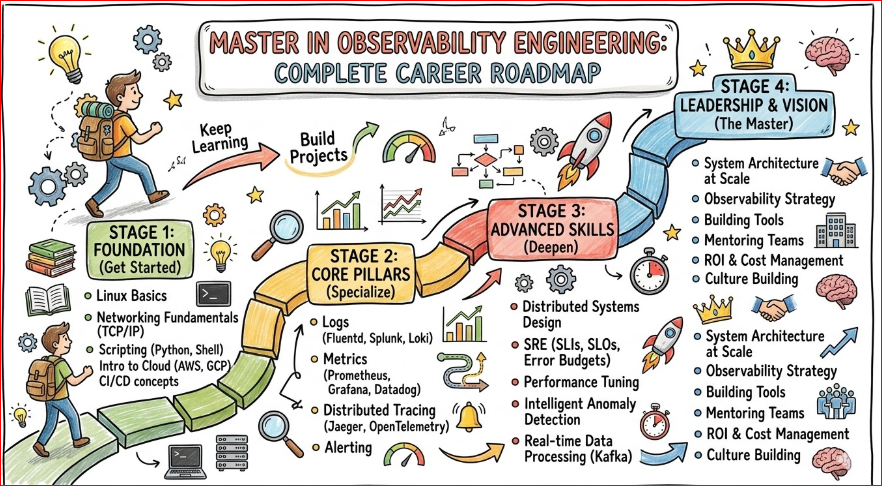
The roadmap provides a clear direction for building skills in monitoring, tracing, and performance optimization.
Great roadmap for Observability Engineering—clearly explains how monitoring, logging, and tracing build strong system visibility for modern cloud applications.